Project Babylon is building a code reflection API that lets the JVM understand computation semantics, not just execute them. The goal: first-class GPU programming in pure Java.
There’s a feature of the Java ecosystem that doesn’t get enough credit: the ability to quietly incubate genuinely radical ideas for years, letting them develop rigor before the community notices them. Virtual threads did this. The Foreign Function & Memory API did this. Project Babylon is doing this right now, and if it succeeds, the consequences will be felt far beyond the Java world.
While the community tracks Valhalla’s value classes and Loom’s concurrency, Project Babylon has been methodically building something different: a way for the JVM to not just run Java code, but to understand what that code means — its computational structure — and translate it into something entirely different. A GPU kernel. A SQL query. A neural network computation graph. The goal is stated plainly on the project page: extend Java’s reach to foreign programming models such as SQL, differentiable programming, machine learning models, and GPUs.
The key word is foreign. Today, if you want to run Java computation on a GPU, you’re dealing with JNI bindings, bytecode analysis via non-standard APIs, or runtime-compiled kernels that require careful alignment between your Java types and the GPU’s memory model. Babylon wants to make that the platform’s problem, not yours.
1. What Code Reflection Actually Means
Java has had reflection since Java 1.1. You can inspect classes, fields, and methods at runtime. What you cannot do — at least not through any standard API — is inspect the body of a method. The bytecode exists, but it’s a low-level instruction format that discards most of the type information and structural intent that the original Java source carried. Abstract syntax trees are available to annotation processors at compile time, but only in fragile, non-standard ways. Neither is suitable for the kind of semantic analysis needed to translate Java code into a GPU kernel.
Babylon introduces a new concept: the code model. When you annotate a method with @CodeReflection, the javac compiler generates a structured, type-rich representation of that method’s body and stores it in the class file alongside the bytecode. This code model captures the actual intent of the code — operations, types, control flow — in a form that is designed for analysis and transformation, not execution. It is, essentially, the method’s source as a first-class data structure accessible at runtime through standard Java APIs.
“Babylon will extend Java’s reach to foreign programming models with an enhancement to reflective programming in Java, called code reflection — enabling standard access, analysis, and transformation of Java code in a suitable form.”— Paul Sandoz, Oracle Architect · openjdk.org/projects/babylon
The distinction from existing reflection matters enormously. Current Java reflection lets you ask “what methods does this class have?” Babylon’s code reflection lets you ask “what does this method compute?” — and get back a structured answer you can inspect, rewrite, and retarget. That is a different kind of capability entirely.
2. The GPU Problem Babylon Is Solving
GPU programming has historically required a complete context switch. You write CUDA or OpenCL in C or C++, manage memory explicitly in both CPU and GPU address spaces, invoke the kernel from the host language, and handle synchronization manually. For Python developers, frameworks like PyTorch abstracted much of this behind tensor operations — you write mathematical intent, and the framework maps it to GPU kernels. Java developers have had no equivalent story.
The gap exists because GPU compilers need the computation in symbolic form — they need to know what operations are being performed, not just what binary instructions will execute them. Python’s NumPy and PyTorch work because array operations carry their intent explicitly: when you write A @ B, the framework knows this is matrix multiplication and can dispatch the right CUDA kernel. Java code compiled to bytecode loses that intent. The bytecode for a matrix multiply looks like loops and array accesses — structurally identical to a hundred other algorithms.
Babylon’s code models restore that intent. A method annotated with @CodeReflection produces a model that describes the computation symbolically, at a level above bytecode. A GPU backend — the Heterogeneous Accelerator Toolkit (HAT) — can then walk that model, recognize the computational structure, and generate the appropriate GPU kernel code. Two compilation stages: Java → code model → GPU driver binary (OpenCL C, CUDA PTX, or SPIR-V). No JNI. No C. Neither separate GPU source files to maintain.
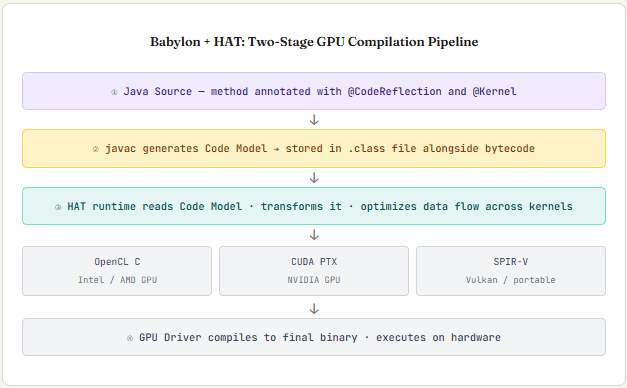
The @CodeReflection annotation is placed on the Java method to be offloaded. The HAT toolkit provides the NDRange API for expressing thread configurations, iFaceMapper for memory layout between Java and GPU address spaces, and the Accelerator abstraction for target-device selection. As of January 2026, HAT supports OpenCL and CUDA backends with SPIR-V under active development.
3. Beyond GPUs: The Wider Scope
GPU acceleration is Babylon’s flagship use case, but the project is explicit that code models are a general-purpose tool. Three other use cases are actively under development by the Babylon team, and each one is significant in its own right.
Automatic differentiation is the mathematical operation that underlies training neural networks — computing gradients by applying the chain rule through a computation graph. Today, this requires Python frameworks that build explicit computation graphs (TensorFlow, JAX) or trace through Python operations dynamically (PyTorch). With Babylon, a Java method annotated with @CodeReflection can have its gradient derived by a library that walks the code model and generates the partial derivative — all in Java, with full type safety. A proof-of-concept implementation is already demonstrated on the project’s website.
LINQ-style query expressions — where Java collections operations are translated to SQL or other query languages rather than executed in memory — become possible when a library can read the code model of a lambda and understand what filter or projection it represents. This is something C# has had since 2007 via expression trees. Babylon gives Java the foundation to build equivalent libraries without language changes or annotation processors.
ONNX-based LLM inference is perhaps the most immediately commercially relevant direction. A November 2025 inside.java article by Adam Sotona demonstrates using Babylon to run ONNX-based generative AI models in Java, with code models providing the bridge between Java’s type system and ONNX’s computational graph format. As organizations look to run LLM inference in their existing Java infrastructure rather than Python microservices, this path becomes increasingly attractive.
Why this matters beyond GPU: Babylon’s code model is, at its core, a way for Java libraries to become aware of the intent of code passed to them — not just its effect. That unlocks a category of library design that has been inaccessible to Java: declarative APIs where the library can inspect, optimize, and retarget the operations it receives. This is the same capability that made Python the language of machine learning.
4. TornadoVM: The Proof of Concept That Came First
TornadoVM, developed at the University of Manchester, is the most mature demonstration that Java GPU programming is possible — and the benchmark against which Babylon/HAT will ultimately be measured. It also operates as a JIT compiler plugin for OpenJDK and GraalVM, accepting Java code annotated with @Parallel and @Reduce and compiling it at runtime to OpenCL C, NVIDIA PTX, or SPIR-V kernels.
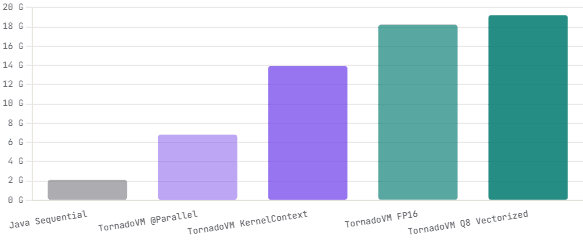
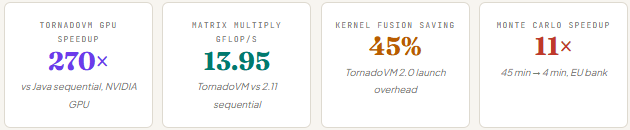
The performance numbers are striking. On an NVIDIA GPU, TornadoVM achieves speedups of up to 270x over Java sequential code for suitable workloads. In December 2025, TornadoVM 2.0 shipped with native INT8 support for NVIDIA PTX and OpenCL, LLM-ready tensor operation bindings, automatic kernel fusion cutting launch overhead by up to 45%, and full Java 21 compatibility. The gpullama3 project — a proof-of-concept running Llama 3 inference entirely in Java via TornadoVM — is the clearest demonstration of where this is headed.
TornadoVM GPU Speedup vs Java Sequential — Matrix Multiply Benchmark
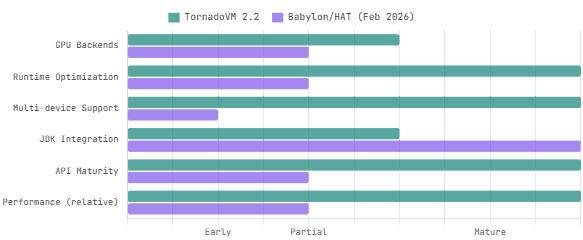
The key distinction between TornadoVM and Babylon/HAT is architectural. Juan Fumero, TornadoVM’s lead developer, compared the two directly in February 2025: TornadoVM is a complete runtime with adaptive compiler optimizations, a specialized code optimizer, dynamic device selection, and runtime task migration. Babylon/HAT is focused on compilation infrastructure — getting code models correct, enabling transformations, building the backend pipeline. TornadoVM currently achieves up to 346x more performance than Babylon/HAT on equivalent GPU workloads, because it has years of runtime optimization built up.
But that framing misses the point of Babylon. TornadoVM is a sophisticated plugin to an existing JVM. Babylon is building the standard platform infrastructure on which tools like TornadoVM — or successors to it — can be built as ordinary Java libraries, without bytecode manipulation, non-standard APIs, or JVM-level instrumentation. The goal isn’t to replace TornadoVM; it’s to make TornadoVM-style capabilities achievable with standard tooling.
Babylon / HAT vs TornadoVM — Current State Comparison (February 2025)
5. Where Babylon Sits in the JDK Roadmap
Babylon is an OpenJDK project sponsored by the Core Libraries and Compiler Groups, led by Paul Sandoz (Oracle). It is not yet a JEP — the project is working on getting code reflection correct before formalizing the API through the JEP process. The current development branch tracks the JDK mainline. Talks at JVMLS 2025, Devoxx Belgium 2025, and JavaOne 2025 confirm the project is active and advancing.
| Component | Status (Feb 2026) | Backends Supported | Notes |
|---|---|---|---|
| @CodeReflection annotation | In development | N/A — compiler feature | javac generates code models, stored in .class file |
| Code Model APIs | In development | N/A — runtime library | Build, analyze, transform code models; updated Dec 2025 |
| HAT — NDRange Kernel API | Research prototype | OpenCL, CUDA PTX | SPIR-V in progress; single-device only as of Feb 2025 |
| Auto-differentiation PoC | Proof of concept | Java (CPU only) | Demonstrated on project site; not production-ready |
| ONNX / LLM inference (Babylon) | Emerging demo | CPU + ONNX runtime | inside.java demo, Nov 2025; Adam Sotona |
| LINQ-style query PoC | Demonstrated | SQL (concept) | Published Feb 2024; shows collections → SQL viability |
| JEP submission | Not yet filed | — | Expected when API stabilizes; multi-release delivery plan |
| TornadoVM 2.2 (separate project) | Released Dec 2025 | OpenCL, PTX, SPIR-V | Production-ready today; does not require Babylon |
Honest timeline note: Babylon is not shipping in JDK 26 or 27. The project leadership has explicitly stated delivery will happen via a series of JEPs across multiple feature releases. What exists today is a development branch that tracks mainline, active research prototypes, and a growing body of published demonstrations. For production GPU work in Java today, TornadoVM 2.2 is the answer. Babylon is what you watch to understand where the JVM platform is heading.
6. What It Takes to Write a GPU Kernel with HAT Today
For developers curious about the developer experience, here’s what the HAT API looks like in practice. The following pattern reflects the Babylon prototype as of January 2026. It requires building from the Babylon development branch — this is not yet available in any JDK release.
// Babylon/HAT GPU kernel pattern — development branch, Jan 2026
import hat.Accelerator;
import hat.ComputeContext;
import hat.KernelContext;
import hat.buffer.Buffer;
import java.lang.reflect.code.CodeReflection;
public class VectorAdd {
// @CodeReflection tells javac to store a code model
// HAT reads this model at runtime to generate GPU kernel
@CodeReflection
static void addKernel(KernelContext kc,
Buffer.F32Array a,
Buffer.F32Array b,
Buffer.F32Array result) {
int i = kc.x; // GPU thread index
result.array(i, a.array(i) + b.array(i));
}
@CodeReflection
void compute(ComputeContext cc,
Buffer.F32Array a,
Buffer.F32Array b,
Buffer.F32Array result) {
// NDRange defines thread count — HAT dispatches to GPU
cc.dispatchKernel(a.length(),
kc -> addKernel(kc, a, b, result));
}
public static void main(String[] args) {
Accelerator acc = new Accelerator(OpenCLBackend.class);
// Java arrays mapped to GPU-accessible memory via Panama FFM
try (var a = acc.allocate(Buffer.F32Array::create, 1024);
var b = acc.allocate(Buffer.F32Array::create, 1024);
var result = acc.allocate(Buffer.F32Array::create, 1024)) {
acc.compute(cc -> new VectorAdd().compute(cc, a, b, result));
}
}
}
Several things are notable here. Memory management uses Project Panama’s Foreign Function & Memory API under the hood — the same API that landed in JDK 22. The GPU thread model (thread index via kc.x) maps directly to OpenCL’s and CUDA’s programming models. The developer writes Java; the HAT compiler reads the code model and generates the target language. No C, no CUDA headers, no glue code.
7. The Bigger Picture: Java for AI Infrastructure
The timing of Babylon is not accidental. The AI infrastructure landscape is almost entirely Python and C++, with GPU compute being the critical path for training and inference. Java enterprises — banks, insurers, logistics companies, telecoms — that have invested decades in Java systems find themselves needing to build AI capabilities while managing an uncomfortable language boundary at the inference layer.
Babylon, combined with Project Leyden’s startup improvements and TornadoVM’s existing GPU runtime, sketches a plausible path where Java inference pipelines can run on GPU hardware without crossing language boundaries. That path is not production-ready today. But the demonstration at Devoxx Belgium 2025 on “Java for AI”, the JVMLS 2025 code reflection talks, and the inside.java November 2025 article on ONNX inference all confirm that the Java stewards are building towards this future deliberately.
8. What We’ve Learned
Project Babylon is building a code reflection API that fundamentally changes what Java can express: not just executing computation, but representing computation symbolically in a form that libraries can inspect, transform, and retarget.
The @CodeReflection annotation causes javac to generate a structured code model stored in the class file alongside bytecode — a representation designed for analysis, not execution.
The primary target is GPU programming through the Heterogeneous Accelerator Toolkit (HAT), which provides an NDRange kernel API on top of Babylon’s code models and compiles to OpenCL C, CUDA PTX, and SPIR-V without any C code from the developer.
But the scope is wider: automatic differentiation for neural network training, LINQ-style query translation, and ONNX-based LLM inference are all demonstrated use cases, all enabled by the same underlying mechanism.
TornadoVM 2.2, shipping today with up to 270× speedups over sequential Java and full LLM inference support, shows that Java GPU programming is already real — Babylon wants to make it standard platform infrastructure rather than a sophisticated plugin. The project is not yet at the JEP stage and will not ship in the near-term JDK cycle.
But the talks, demonstrations, and development activity in 2025 and early 2026 confirm that Babylon is the most architecturally significant JVM project in active development — one that could redefine what “Java backend” means in an AI-first infrastructure world.
