As I have said in my blog on “data-realised algorithms“, while we have not used mathematical equations explicitly, data collected using data-realised techniques such as “accumulation of various properties of molecular structures” inherently use mathematical concepts. The expression is in a form that is different from mathematical equations that allows for more complex representation than that is possible with the representation as equations. I know this seems like a tall claim, but if we stop to think, after all the language of mathematics has evolved because humans wanted to express what they observed and understood of nature not the other way. So, it should follow that the natural processes that are not specifically arranged by us to follow a specific path, will enact out mathematical concepts, both that which we understand and have represented by equations and that which we do not understand. But, before we get into the mathematical concepts, to summarise what I have said we can do as a design for AI:
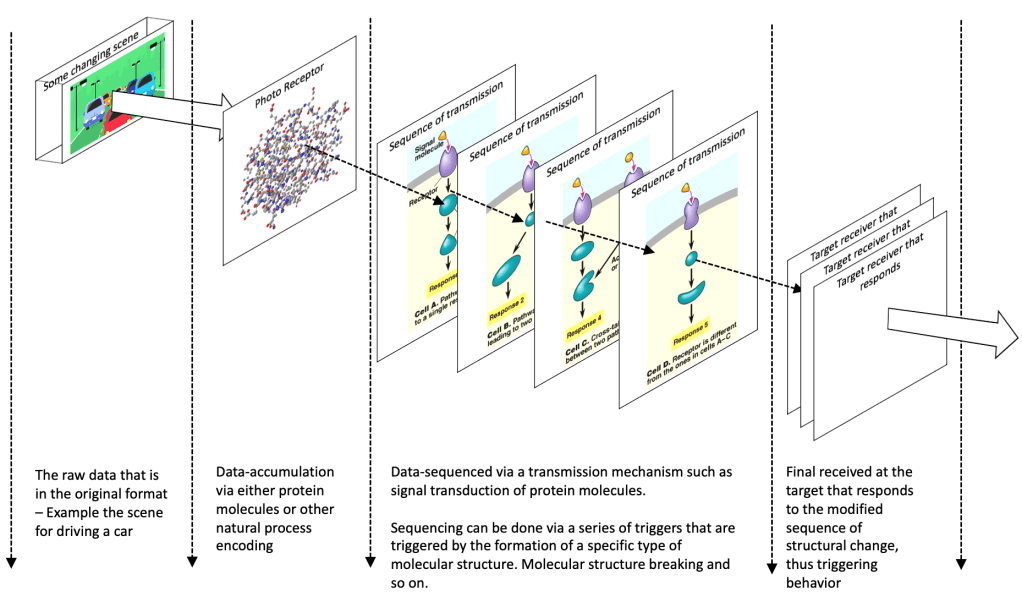
The above diagram shows the first set of steps in the data-realised algorithm. As the data passes through various responses and triggers of molecular structures, the sequence and behaviours of the data or the harmonics of the data is automatically established. When we look at the output of the response from the target, we should find that a few things are already done on the data:
- The related data are already grouped together.
- The changes of the relevant data across a duration is already accumulated in the relevant order.
- The sequence is already established through the series of transmission to the target. The specific target can be made to respond and retain the response only for a certain behaviour of the data. Thus, using the response from a specific target should give us only that data which has some intended behaviour.
- Even though a specific set of parameters could have been created as a single molecular structure, the structure can be broken down to only those relevant ones that contribute to a behaviour. Thus a filter is automatically established.
- The fuzziness of data is automatically present because we are not time bound and are accumulation and process trigger bound. Thus, the natural fuzziness which we notice in nature occurs automatically.
If we analyse this further we find that it is nothing but the same if-else clause that we implement. But, it gets implemented without much rigid “if-else” clauses or rigid mathematical functions to be learnt. Just a series of triggers of accumulation, formation or split which trigger when some or other condition is met. But, the number of mathematical functions that is realised by this process are many for which we seem to have to write a lot of code and need a very powerful processor to do the computation. And even after all that code and super-computer-based processing we cannot achieve the fuzziness that is already present in the above type of implementation.
So, what are the mathematical concepts that are present in the above? Let us start at the first concept of “encoding of changes by accumulation into some molecular structure“. To understand this, let us look in-depth at the steps in the protein synthesis process. On the high level, the process involves transcription, translation, post-translation modification and protein folding. For the first transcription: mRNA needs to be formed from DNA. For this, denaturation of a part of the DNA to be transcribed has to occur which splits the strands of the DNA. The strands split typically when the hydrogen bonds between the base pairs are broken. One of the various reasons for change in hydrogen bonds is heat. A specific variation in heat induces denaturation which then triggers the process of transcription. If variation in heat represents the data that we want to measure, then, a specific variation in heat splits specific hydrogen bonds in the DNA. The continuity of the heat variation and the duration is encoded in the number of hydrogen bonds split. Thus, the mRNA created from a denatured DNA should encode the variation, the continuity and the duration of heat variation. So what we have encoded is a combination ∆T over ∆s, where T = temperature and s = the space of temperature variance and ∆T over ∆t, where t = time of variance. But this is not just as simple as this, because what we is happening is a combination of both together. If we look at heat variance in time function and map to the structure formed say, we have something as below:

As time progresses, the structure changes based on the heat adding more bonds. It should be realised that while I have taken t1, t2 … as discrete time intervals, the bonds get formed because of the continuity that exists between t1 and t2, so variance in heat over ∆t translates to the bond. So, we can view this as the “continuous variation of the heat across time, transforming to the structure”. The structure thus contains all the information from t1 to t9. If we analyse this in the space view at t9, we are looking at just the final structure with the impact from all other time intervals accumulated into it, shown below:

At any instant of time, what we have is an accumulation of all the prior affecting changes contributing to the formation of the structure, continuously growing or decaying by a natural growth factor (e) from that prior time of formation till the current instant. So, if the structure has a variation of some function f(t) with time ‘t’ and the variation in space is F(s), then for any given ‘t’, we are looking at the projection of multiple: (f(t) * dt * e-st), where e is the natural growth/decay typically followed and dt is the delta time for which we can measure discretely the structure change. Integrate this and we get what is present in this frame of space.
So, we are looking at the molecular structure formed representing this equation: F(s) = ∫ e-st f(t) dt, which turns out to be the Laplace transform. This should really not surprise us, because, what is happening in the above is: a signal that is present as data in the heat distribution across space and time is converted to a molecular representation at any instant.
What is important to note here is that I have only taken one parameter as an example, i.e., heat. But, as I have said before, this need not be true. Heat is not the only parameter that affects the creation of these structures. There can be ‘n’ parameters affecting the formation, not just one or two. For example in proteins, which is an aggregation of amino acids by the formation of peptide bonds, there are many variations that are possible that determine the structure of the protein formed. Some of them are bond distance, bond angles, dihedral angles etc. They are affected by various parameters such as H-bonds, electrostatic and hydrophobic properties. Thus, the function f(t) in the above equation is in fact f(p1, p2, p3… )(t).
If we analyse what should be happening here, we find that at every ∆t when a bond is formed, an equilibrium has been established of all the variations in the affecting parameters that form the bond. This equilibrium established grows or decays based on effects of the variations of the same parameters after the time of formation till the time the structure is fully formed. So, the function f(p1, p2, p3… )(t) is not a regular function, but a continuously varying function.
So, as I have said before, even though we have not really computed functions using collected raw data, with this, we would have got the natural process to automatically act as per the required mathematical parameters we want without actually finding weights and biases or having a lot of data to learn from. It works with just the least amount of current data required to form the various structures. This allows us to break away from the expensive, rigid learning phase that we have and react to actual current circumstances based on the current data.
Published on Java Code Geeks with permission by Raji Sankar, partner at our JCG program. See the original article here: Mathematics of data-realised algorithm – Part 1 Opinions expressed by Java Code Geeks contributors are their own. |
