This post uses Tensorflow with Keras API for a classification problem of predicting diabetes based on a feed-forward neural network also known as multilayer perceptron and uses Pima Indians Diabetes Database from Kaggle. A Google colab notebook with code is available on GitHub.
Exploratory data analysis
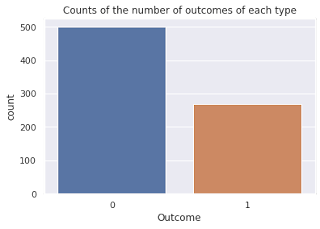
The dataset consists of 8 numeric features each of which does not have any missing values. The database contains 768 records from which 500 correspond to negative outcomes and 268 to positive.
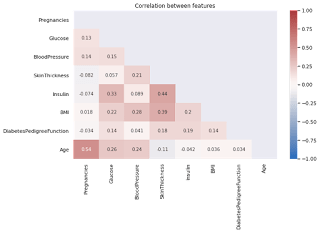
There are no features that strongly correlate to each other.
Building a model
We split the dataset into the training part which constitutes 80% of the whole data and the test part of 20%. A
sequential model consisting of 6 layers. The first one is a normalization layer that is a kind of experimental
preprocessing layer used to coerce it inputs to have distributions with the mean of zero and standard deviation of one.
normalizer = preprocessing.Normalization(axis=-1) normalizer.adapt(np.array(X_train)) normalizer.mean.numpy()
The model contains two three fully-connected layers, two with five units and ReLu activation and one output layer with sigmoid activation function. In addition, there are two dropout layers to prevent overfitting. The layers with ReLu activation use He normal weight initialization and the output layer uses normal Glorot normal weight initialization.
He normal weight initialization
model = Sequential()
model.add(normalizer)
model.add(Dense(5, input_shape=(X_train.shape[1],),
activation='relu', kernel_initializer='he_normal'))
model.add(Dropout(0.2))
model.add(Dense(5, activation="relu",
kernel_initializer='he_normal'))
model.add(Dropout(0.2))
model.add(Dense(1, activation="sigmoid",
kernel_initializer="glorot_normal"))
The model uses Adam optimizer, binary cross-entropy loss function and binary accuracy as a metric.
model.compile(Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['binary_accuracy'])
Results
The learning rate of 1e-5 was picked to ensure the decrease of both training and validation loss. Two dropout layers were added to prevent overfitting.
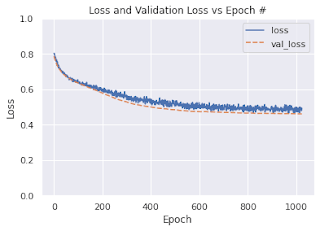
The accuracy of over 70% was achieved. The confusion matrix is depicted below.

Resources
1.https://en.wikipedia.org/wiki/TensorFlow
3.https://en.wikipedia.org/wiki/Keras
Published on Java Code Geeks with permission by Dmitry Noranovich, partner at our JCG program. See the original article here: Binary classification with Tensorflow 2 Opinions expressed by Java Code Geeks contributors are their own. |
