These days, there is a lot of excitement around 12-factor apps, microservices, and service mesh, but not so much around cloud-native data. The number of conference talks, blog posts, best practices, and purpose-built tools around cloud-native data access is relatively low. One of the main reasons for this is because most data access technologies are architectured and created in a stack that favors static environments rather than the dynamic nature of cloud environments and Kubernetes.
In this article, we will explore the different categories of data gateways, from more monolithic to ones designed for the cloud and Kubernetes. We will see what are the technical challenges introduced by the Microservices architecture and how data gateways can complement API gateways to address these challenges in the Kubernetes era.
Application architecture evolutions
Let’s start with what has been changing in the way we manage code and the data in the past decade or so. I still remember the time when I started my IT career by creating frontends with Servlets, JSP, and JSFs. In the backend, EJBs, SOAP, server-side session management, was the state of art technologies and techniques. But things changed rather quickly with the introduction of REST and popularization of Javascript. REST helped us decouple frontends from backends through a uniform interface and resource-oriented requests. It popularized stateless services and enabled response caching, by moving all client session state to clients, and so forth. This new architecture was the answer to the huge scalability demands of modern businesses.
A similar change happened with the backend services through the Microservices movement. Decoupling from the frontend was not enough, and the monolithic backend had to be decoupled into bounded context enabling independent fast-paced releases. These are examples of how architectures, tools, and techniques evolved pressured by the business needs for fast software delivery of planet-scale applications.
That takes us to the data layer. One of the existential motivations for microservices is having independent data sources per service. If you have microservices touching the same data, that sooner or later introduces coupling and limits independent scalability or releasing. It is not only an independent database but also a heterogeneous one, so every microservice is free to use the database type that fits its needs.
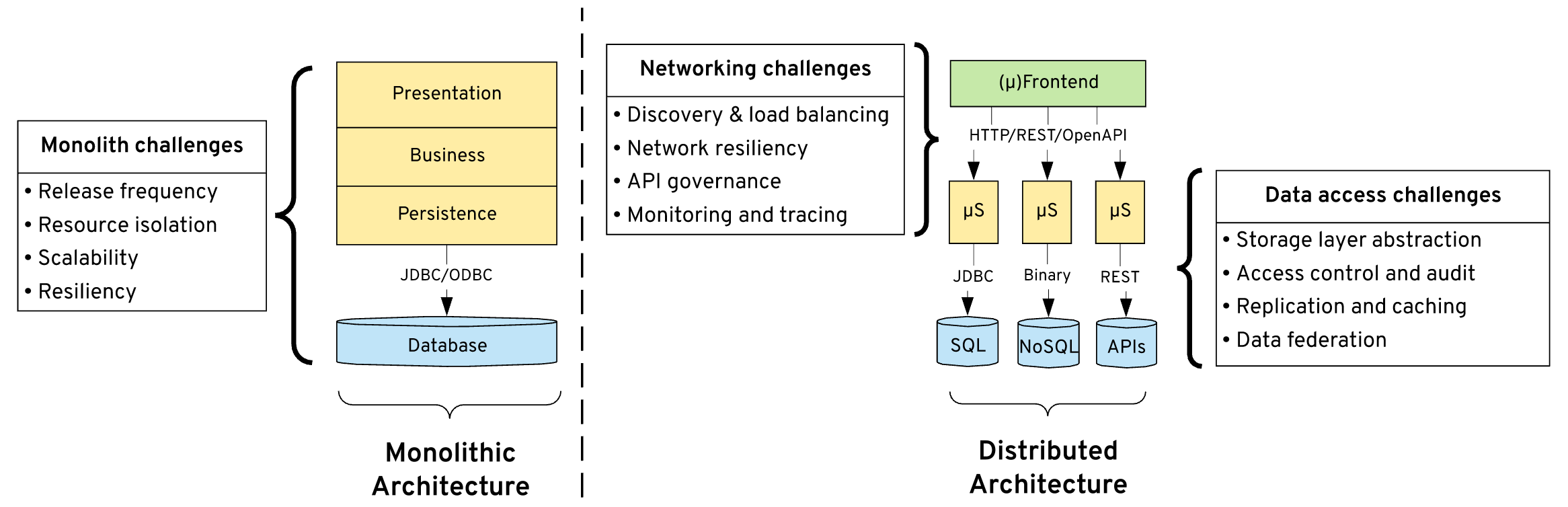
While decoupling frontend from backend and splitting monoliths into microservices gave the desired flexibility, it created challenges not-present before. Service discovery and load balancing, network-level resilience, and observability turned into major areas of technology innovation addressed in the years that followed.
Similarly, creating a database per microservice, having the freedom and technology choice of different datastores is a challenge. That shows itself more and more recently with the explosion of data and the demand for accessing data not only by the services but other real-time reporting and AI/ML needs.
The rise of API gateways
With the increasing adoption of Microservices, it became apparent that operating such an architecture is hard. While having every microservice independent sounds great, it requires tools and practices that we didn’t need and didn’t have before. This gave rise to more advanced release strategies such as blue/green deployments, canary releases, dark launches. Then that gave rise to fault injection and automatic recovery testing. And finally, that gave rise to advanced network telemetry and tracing. All of these created a whole new layer that sits between the frontend and the backend. This layer is occupied primarily with API management gateways, service discovery, and service mesh technologies, but also with tracing components, application load balancers, and all kinds of traffic management and monitoring proxies. This even includes projects such as Knative with activation and scaling-to-zero features driven by the networking activity.
With time, it became apparent that creating microservices at a fast pace, operating microservices at scale requires tooling we didn’t need before. Something that was fully handled by a single load balancer had to be replaced with a new advanced management layer. A new technology layer, a new set of practices and techniques, and a new group of users responsible were born.
The case for data gateways
Microservices influence the data layer in two dimensions. First, it demands an independent database per microservice. From a practical implementation point of view, this can be from an independent database instance to independent schemas and logical groupings of tables. The main rule here is, only one microservice owns and touches a dataset. And all data is accessed through the APIs or Events of the owning microservice. The second way a microservices architecture influenced the data layer is through datastore proliferation. Similarly, enabling microservices to be written in different languages, this architecture allows the freedom for every microservices-based system to have a polyglot persistence layer. With this freedom, one microservice can use a relational database, another one can use a document database, and the third microservice one uses an in-memory key-value store.
While microservices allow you all that freedom, again it comes at a cost. It turns out operating a large number of datastore comes at a cost that existing tooling and practices were not prepared for. In the modern digital world, storing data in a reliable form is not enough. Data is useful when it turns into insights and for that, it has to be accessible in a controlled form by many. AI/ML experts, data scientists, business analysts, all want to dig into the data, but the application-focused microservices and their data access patterns are not designed for these data-hungry demands.
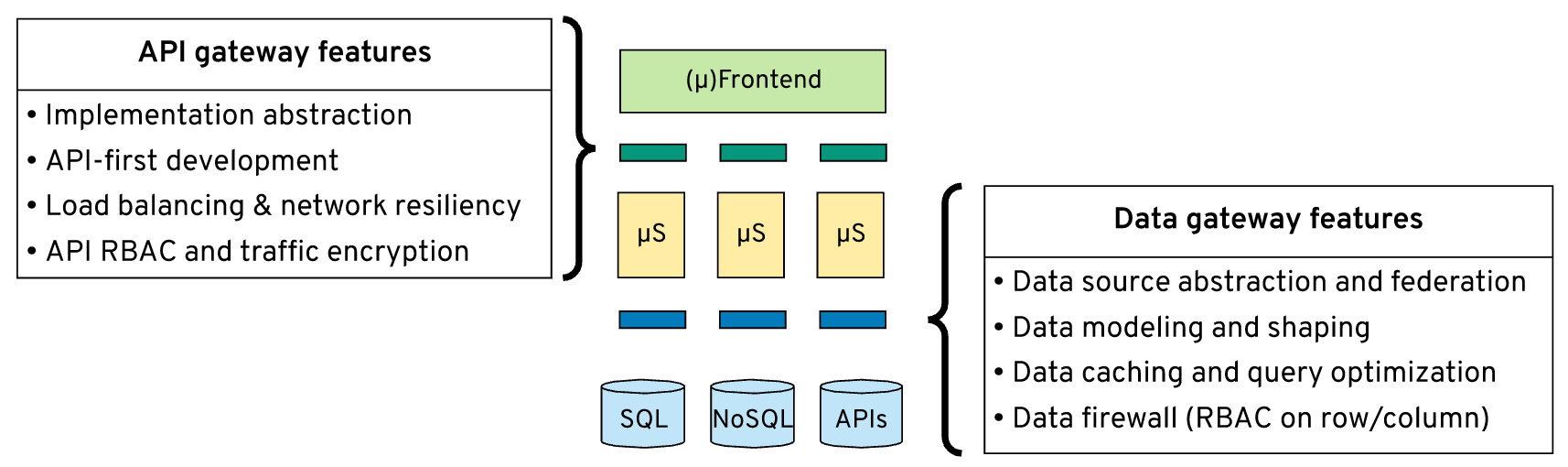
This is where data gateways can help you. A data gateway is like an API gateway, but it understands and acts on the physical data layer rather than the networking layer. Here are a few areas where data gateways differ from API gateways.
Abstraction
An API gateway can hide implementation endpoints and help upgrade and rollback services without affecting service consumers. Similarly, a data gateway can help abstract a physical data source, its specifics, and help alter, migrate, decommission, without affecting data consumers.
Security
An API manager secures resource endpoints based on HTTP methods. A service mesh secures based on network connections. But none of them can understand and secure the data and its shape that is passing through them. A data gateway, on the other hand, understands the different data sources and the data model and acts on them. It can apply RBAC per data row and column, filter, obfuscate, and sanitize the individual data elements whenever necessary. This is a more fine-grained security model than networking or API level security of API gateways.
Scaling
API gateways can do service discovery, load-balancing, and assist the scaling of services through an orchestrator such as Kubernetes. But they cannot scale data. Data can scale only through replication and caching. Some data stores can do replication in cloud-native environments but not all. Purpose-built tools, such as Debezium, can perform change data capture from the transaction logs of data stores and enable data replication for scaling and other use cases.
A data gateway, on the other hand, can speed-up access to all kinds of data sources by caching data and providing materialized views. It can understand the queries, optimize them based on the capabilities of the data source, and produce the most performant execution plan. The combination of materialized views and the stream nature of change data capture would be the ultimate data scaling technique, but there are no known cloud-native implementations of this yet.
Federation
In API management, response composition is a common technique for aggregating data from multiple different systems. In the data space, the same technique is referred to as heterogeneous data federation. Heterogeneity is the degree of differentiation in various data sources such as network protocols, query languages, query capabilities, data models, error handling, transaction semantics, etc. A data gateway can accommodate all of these differences as a seamless, transparent data-federation layer.
Schema-first
API gateways allow contract-first service and client development with specifications such as OpenAPI. Data gateways allow schema-first data consumption based on the SQL standard. A SQL schema for data modeling is the OpenAPI equivalent of APIs.
Many shades of data gateways
In this article, I use the terms API and data gateways loosely to refer to a set of capabilities. There are many types of API gateways such as API managers, load balancers, service mesh, service registry, etc. It is similar to data gateways, where they range from huge monolithic data virtualization platforms that want to do everything, to data federation libraries, from purpose-built cloud services to end-user query tools.
Let’s explore the different types of data gateways and see which fit the definition of “a cloud-native data gateway.” When I say a cloud-native data gateway, I mean a containerized first-class Kubernetes citizen. I mean a gateway that is open source, using open standards; a component that can be deployed on hybrid/multi-cloud infrastructures, work with different data sources, data formats, and applicable for many use cases.
Classic data virtualization platforms
In the very first category of data gateways, are the traditional data virtualization platforms such as Denodo and TIBCO/Composite. While these are the most feature-laden data platforms, they tend to do too much and want to be everything from API management, to metadata management, data cataloging, environment management, deployment, configuration management, and whatnot. From an architectural point of view, they are very much like the old ESBs, but for the data layer. You may manage to put them into a container, but it is hard to put them into the cloud-native citizen category.
Databases with data federation capabilities
Another emerging trend is the fact that databases, in addition to storing data, are also starting to act as data federation gateways and allowing access to external data.
For example, PostgreSQL implements the ANSI SQL/MED specification for a standardized way of handling access to remote objects from SQL databases. That means remote data stores, such as SQL, NoSQL, File, LDAP, Web, Big Data, can all be accessed as if they were tables in the same PostgreSQL database. SQL/MED stands for Management of External Data, and it is also implemented by MariaDB CONNECT engine, DB2, Teiid project discussed below, and a few others.
Starting in SQL Server 2019, you can now query external data sources without moving or copying the data. The PolyBase engine of SQL Server instance to process Transact-SQL queries to access external data in SQL Server, Oracle, Teradata, and MongoDB.
GraphQL data bridges
Compared to the traditional data virtualization, this is a new category of data gateways focused around the fast web-based data access. The common thing around Hasura, Prisma, SpaceUpTech, is that they focus on GraphQL data access by offering a lightweight abstraction on top of a few data sources. This is a fast-growing category specialized for enabling rapid web-based development of data-driven applications rather than BI/AI/ML use cases.
Open-source data gateways
Apache Drill is a schema-free SQL query engine for NoSQL databases and file systems. It offers JDBC and ODBC access to business users, analysts, and data scientists on top of data sources that don’t support such APIs. Again, having uniform SQL based access to disparate data sources is the driver. While Drill is highly scalable, it relies on Hadoop or Apache Zookeeper’s kind of infrastructure which shows its age.
Teiid is a mature data federation engine sponsored by Red Hat. It uses the SQL/MED specification for defining the virtual data models and relies on the Kubernetes Operator model for the building, deployment, and management of its runtime. Once deployed, the runtime can scale as any other stateless cloud-native workload on Kubernetes and integrate with other cloud-native projects. For example, it can use Keycloak for single sign-on and data roles, Infinispan for distributed caching needs, export metrics and register with Prometheus for monitoring, Jaeger for tracing, and even with 3scale for API management. But ultimately, Teiid runs as a single Spring Boot application acting as a data proxy and integrating with other best-of-breed services on Openshift rather than trying to reinvent everything from scratch.
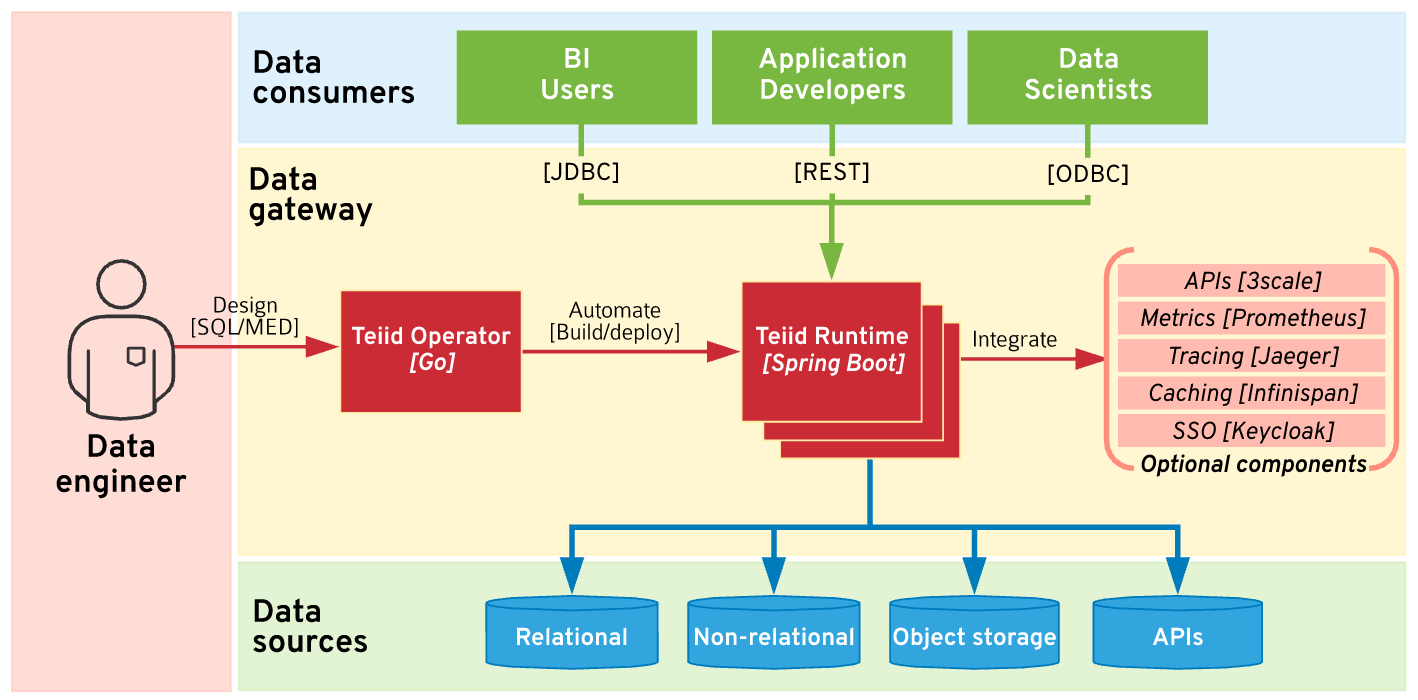
On the client-side, Teiid offers standard SQL over JDBC/ODBC and Odata APIs. Business users, analysts, and data scientists can use standard BI/analytics tools such as Tableau, MicroStrategy, Spotfire, etc. to interact with Teiid. Developers can leverage the REST API or JDBC for custom built microservices and serverless workloads. In either case, for data consumers, Teiid appears as a standard PostgreSQL database accessed over its JDBC or ODBC protocols but offering additional abstractions and decoupling from the physical data sources.
PrestoDB is another popular open-source project started by Facebook. It is a distributed SQL query engine targeting big data use cases through its coordinator-worker architecture. The Coordinator is responsible for parsing statements, planning queries, managing workers, fetching results from the workers, and returning the final results to the client. The worker is responsible for executing tasks and processing data.
Some time ago, the founders split from PrestoDB and created a fork called Trino (formerly PrestoSQL). Today, PrestoDB is part of The Linux Foundation, and Trino part of Trino Software Foundation. Both distributions of Presto are among the most active and powerful open-source data gateway projects in this space. To learn more about this technology, here is a good book I found.
Cloud-hosted data gateways services
With a move to the cloud infrastructure, the need for data gateways doesn’t go away but increases instead. Here are a few cloud-based data gateway services:
AWS Athena is ANSI SQL based interactive query service for analyzing data tightly integrated with Amazon S3. It is based on PrestoDB and supports additional data sources and federation capabilities too. Another similar service by Amazon is AWS Redshift Spectrum. It is focused around the same functionality, i.e. querying S3 objects using SQL. The main difference is that Redshift Spectrum requires a Redshift cluster, whereas Athena is a serverless offering that doesn’t require any servers. Big Query is a similar service but from Google.
These tools require minimal to no setup, they can access on-premise or cloud-hosted data and process huge datasets. But they couple you with a single cloud provider as they cannot be deployed on multiple clouds or on-premise. They are ideal for interactive querying rather than acting as hybrid data frontend for other services and tools to use.
Secure tunneling data-proxies
With cloud-hosted data gateways comes the need for accessing on-premise data. Data has gravity and also might be affected by regulatory requirements preventing it from moving to the cloud. It may also be a conscious decision to keep the most valuable asset (your data) from cloud-coupling. All of these cases require cloud access to on-premise data. And cloud providers make it easy to reach your data. Azure’s On-premises Data Gateway is such a proxy allowing access to on-premise data stores from Azure Service Bus.
In the opposite scenario, accessing cloud-hosted data stores from on-premise clients can be challenging too. Google’s Cloud SQL Proxy provides secure access to Cloud SQL instances without having to whitelist IP addresses or configure SSL.
Red Hat-sponsored open-source project Skupper takes the more generic approach to address these challenges. Skupper solves Kubernetes multi-cluster communication challenges through a layer 7 virtual network that offers advanced routing and secure connectivity capabilities. Rather than embedding Skupper into the business service runtime, it runs as a standalone instance per Kubernetes namespace and acts as a shared sidecar capable of secure tunneling for data access or other general service-to-service communication. It is a generic secure-connectivity proxy applicable for many use cases in the hybrid cloud world.
Connection pools for serverless workloads
Serverless takes software decomposition a step further from microservices. Rather than services splitting by bounded context, serverless is based on the function model where every operation is short-lived and performs a single operation. These granular software constructs are extremely scalable and flexible but come at a cost that previously wasn’t present. It turns out rapid scaling of functions is a challenge for connection-oriented data sources such as relational databases and message brokers. As a result cloud providers offer transparent data proxies as a service to manage connection pools effectively. Amazon RDS Proxy is such a service that sits between your application and your relational database to efficiently manage connections to the database and improve scalability.
Conclusion
Modern cloud-native architectures combined with the microservices principles enable the creation of highly scalable and independent applications. The large choice of data storage engines, cloud-hosted services, protocols, and data formats, gives the ultimate flexibility for delivering software at a fast pace. But all of that comes at a cost that becomes increasingly visible with the need for uniform real-time data access from emerging user groups with different needs. Keeping microservices data only for the microservice itself creates challenges that have no good technological and architectural answers yet. Data gateways, combined with cloud-native technologies offer features similar to API gateways but for the data layer that can help address these new challenges. The data gateways vary in specialization, but they tend to consolidate on providing uniform SQL-based access, enhanced security with data roles, caching, and abstraction over physical data stores.
Data has gravity, requires granular access control, is hard to scale, and difficult to move on/off/between cloud-native infrastructures. Having a data gateway component as part of the cloud-native tooling arsenal, which is hybrid and works on multiple cloud providers, supports different use cases is becoming a necessity.
This article was originally published on InfoQ here.
Published on Java Code Geeks with permission by Bilgin Ibryam, partner at our JCG program. See the original article here: Data Gateways in the Cloud Native Era Opinions expressed by Java Code Geeks contributors are their own. |
