Open-source collaboration, or how we finally added merge-on-refresh to Apache Lucene
The open-source software movement is a clearly a powerful phenomenon. A diverse (in time, geography, interests, gender (hmm not really, not yet, hrmph), race, skills, use-cases, age, corporate employer, motivation, IDEs (or,
Emacs (with all of its recursive parens)), operating system, …) group of passionate developers work together, using surprisingly primitive digital tooling and asynchronous communication channels, devoid of emotion and ripe for misinterpreting intents, to jointly produce something incredible, one tiny “progress not perfection” change at a time.
With enough passion and enough time and enough developers, a strong community, the end result is in a league all its own versus the closed source alternatives. This, despite developers coming and going, passionate “bike shedding” battles emerging and eventually fizzing out, major disruptions like joining the development of two related projects, and a decade later, doing just the opposite, or the Apache board stepping in when one corporation has too much influence on the Project Management Committee (PMC).
Many changes are simple: a developer notices a typo in javadoc, code comments or an exception message and pushes a fix immediately, not needing synchronous review. Others begin as a surprising spinoff while discussing how to fix a unit-test failure over email and then iterate over time to something remarkable, such as Lucene’s now powerful randomized unit-testing infrastructure. Some changes mix energy from one developer with strong engagement from others, such as the recent

pure-Java re-implementation of our Direct IO Directory implementation to reduce the impact of large backround merges to concurrent searching. Some problems are discovered and fixed thanks to massive hurricanes!
Vital collaboration sometimes happens outside the main project sources, such as the recent addition of “always on“ low-overhead Java Flight Recorder (JFR) profiling and flame charts to Lucene’s long running nightly benchmarks, now running on a the very concurrent 64/128 core AMD Ryzen 3990X Threadripper CPU. Some proposed changes are
carefully rejected for good reasons. Still others, too many unfortunately, seem to quietly die on the vine for no apparent reason.
And then there are truly exotic examples, like the new merge-on-refresh feature in Lucene 8.7.0, rare even to me and my 14+ years since joining the Apache Lucene developer community. One long scroll through all the comments on that linked issue ( LUCENE-8962) should give you a quick, rough, from-a-distance appreciation for the strange collaborative magic that produced this impactful new feature, including a big initial GitHub pull-request, many subsequent iterations, three attempts to commit the feature and two reverts due to unanticipated yet clear problems, the many random test failures, and finally one subtle, critical and nearly show-stopper bug and its clever solution.
The full story of this change, and the quiet impact of this feature, is so fascinating that I feel compelled to explain it here and now. Not least because this impressive collaboration happened right under our noses, as a collaboration between employees of at least two very different companies, largely as asynchronous emails and pull requests flying across our screens, buried in the 100s of other passionate Lucene related emails at the time.
It is hard to see this particular forrest from the trees. Let’s reconstruct!
Setting the stage
To begin, we must first learn a bit about Lucene to understand the context of this new feature. A Lucene index consists of multiple write-once segments. New documents, indexed into in-memory thread-private segments, are periodically written to disk as small initial segments. Each segment is its own self contained miniature Lucene index, consisting itself of multiple on-disk files holding the diverse parts of a Lucene index (inverted index postings, doc values or “forward index”,dimensional points, stored fields, deleted documents, etc.), read and written by Lucene’s Codec abstraction. Over time, too many segments inevitably sprout up like mushrooms, so Lucene periodically, nearly continuously, merges such segments into a larger and larger logarithmic staircase of segments in the background.
At search time, each query must visit all live segments to find and rank its matching hits, either sequentially or, more often these days thanks to massively concurrent hardware the CPU creators keep releasing, concurrently. This concurrent search, where multiple threads search for matches for your query, keeps our (Amazon‘s customer-facing product search’s) long-pole query latencies nice and low so you get your search results quickly! Unfortunately, segments naturally add some search CPU, HEAP and GC cost: the more segments in your index, the more cost for the same query, all else being equal. This is why Lucene users with mostly static indices might consider
force-merging their whole index down to a single segment.
If you are continuously indexing a stream of documents and would like to search those recently indexed documents in near-real-time, this segmented design is particularly brilliant: thank you Doug Cutting! In our case there is a relentless firehose of high-velocity catalog updates and we must make all of those updates searchable, quickly. The segmented design works well, providing an application-controlled compromise between indexing throughput, search performance, and the delay after indexing until documents become near-real-time searchable.
The per-segment query-time cost breaks down into two parts: 1) a small fixed cost for each segment, such as initializing a Scorer for that query and segment, looking up terms in the segment’s term dictionary, allocating objects, cloning classes for IO, etc., and also 2) a variable cost in proportion to how many documents the query matches in the segment. At Amazon, where we have now migrated 100% of customer-facing product search queries onto Apache Lucene, we have very high and peaky query rates, so the small fixed cost of even tiny segments can add up. We have already heavily invested in reducing the number of segments, including aggressively reclaiming deleted documents, by
carefully tuning TieredMergePolicy.
We happily accept higher indexing costs in exchange for lower search time costs because we use Lucene’s efficient Segment Replication feature to quickly propagate index updates across many replicas running on a great many AWS EC2 instances. With this design, each shard needs only a single indexer, regardless of how many replicas it has. This feature enables physical isolation of the processes and servers doing indexing from the replicas searching that index, and greatly lowers the total CPU cost of indexing relative to the CPU cost of searching. Heavy indexing events, like a long-running large merge or a sudden burst of documents to re-index, have near-zero impact on searching. This also gives us freedom to separately fine tune optimal AWS EC2 instance types to use for indexing versus searching, and yields a stream of incremental index snapshots (backups) stored in AWS S3 that we can quickly roll back to if disaster strikes.
An idea is born
Necessity is the mother of invention! The idea for merge-on-commit came from Michael Froh, a long-time developer now working with me on Amazon’s product search team. Michael, staring at our production metrics one day, noticed that each new index snapshot, incrementally replicated out to many replicas via AWS S3, contained quite a few minuscule segments. This is expected, because of Lucene IndexWriter’s highly concurrent “one indexing thread per segment” design: if you use eight concurrent indexing threads, for higher overall indexing throughput, each refresh will then write eight new segments. If you refresh frequently, e.g. Elasticsearch defaults to every second, these new segments will usually be very small and very numerous.
Lucene will typically merge away these small segments, after commit finishes, and after those segments were already replicated for searching. But Michael’s simple idea was to modify IndexWriter to instead quickly merge such tiny segments during its commit operation, such that after commit finishes, the commit point will reference already merged tiny segments, substantially reducing the segment count replicated for searching. commit is already a rather costly operation, so adding, say, up to five seconds (configurable via IndexWriterConfig) for these tiny segments to merge, is an acceptable latency price to pay if it means those eight newly flushed segments are merged down to one, reducing our per-query segment fixed cost. So we opened an issue (LUCENE-8962) in Lucene’s Jira to get a discussion started and to explore the idea.
Unfortunately, IndexWriter's concurrency is especially confusing: multiple complex classes, each with multiple shared concurrency constructs, make changes risky. We have a long-standing issue to improve the situation, but there has been little progress over the years (patches welcome!). After many pull request (PR) iterations, internal to Amazon, we settled on an implementation, reviewed and tested it carefully, pushed it to our world-wide production search fleet, and saw a substantial (~25%) reduction in average segment counts searched per-query, along with a big reduction in segment count variance, yay!:
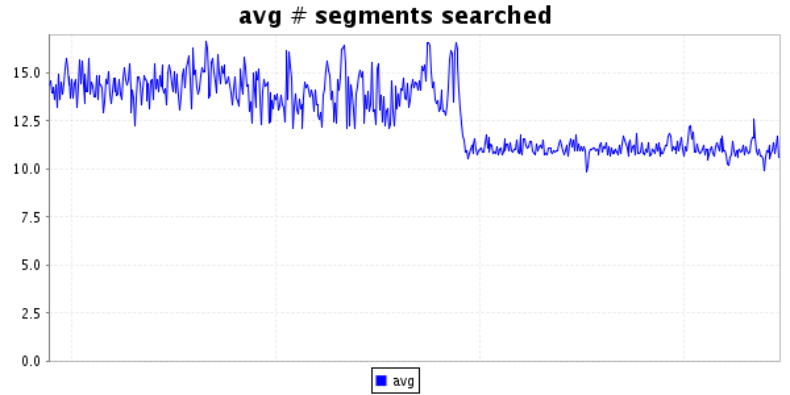
We also saw a small improvement in GC metrics, but no clearly measurable reduction to long-pole query latencies.
The iterations begin
Our approach worked only for commit, when in practice the feature might also be useful forrefresh, which is like commit minus the fsync for durability in case your computer or OS suddenly crashes. Unfortunately, these code paths are nearly entirely separate inside IndexWriter, so we aimed for “progress not perfection” and Michael opened an initial GitHub pull request that just worked for commit.
Alas, shortly thereafter, Lucene’s excellent randomized tests, running continuously on Apache’s public, and Elastic.co’s private, Jenkins build infrastructure, started failing in exotic ways, leading us to revert the change five days later. We found the root cause of those failures, and Michael Sokolov opened another pull request to try again. This time we
tried more carefully to “beast” Lucene’s unit tests before pushing (basically, run them over and over again on a
highly concurrent computer, beast3 to explore the random test space a bit). This uncovered even more exotic test failures, which we fixed and then re-iterated.
At this point Simon Willnauer suddenly engaged, with an initial comment on the now massive LUCENE-8962, and
reviewed this PR more closely, asking for the new IndexWriterEvents change to be split off into a separate followon issue which has now (months later) separately been committed thanks to Zach Chen and Dawid Weiss! Simon also questioned the overall approach and value of the feature, as well as some specific changes in the PR. I pleaded with Simon to consider how helpful this feature is.
Finally, Simon, frustrated by the approach, and hearing my plea, rolled his sleeves up and prototyped a compelling alternative implementation, yielding a more general simplification over the original approach. Simon’s cleaner approach paved the path to also eventually supporting merge-on-refresh, something we considered too difficult on the first PR (more on this later, a little epilogue). Lots of feedback and iterations and beasting ensued, and Simon iterated that PR to a committable pull request and then factored out a base infrastructure pull request first, and
pushed that first step.
There were also questions about how Lucene should default. This powerful feature is currently disabled by default, but we should consider enabling it by default, perhaps just during commit. Until then, brave Lucene users our there: it is your job to choose when to enable this feature for your usage!
The last subtle, brutal, scary atomicity bug
Simon then updated the 2nd pull request to use the newly pushed base infrastructure and pushed it after more substantial test beasting, and we thought we were at last done! But, the computers disagreed: Lucene’s randomized tests started failing in a different exotic way leading to lots of great discussion on the issue and finally Simon getting to the smoking gun root cause, a horrible discovery: there was a subtle yet fatal flaw in all of the attempts and fixes thus far!
The change broke Lucene’s atomicity guarantee for updateDocument in rare cases, forcing us to revert for a second time. At this point we were all rather dejected, after so much hard work, cross-team collaboration, iterations and beasting, as it was unclear exactly how we could fix this issue. Furthermore, this was a bug that was likely quietly impacting Amazon product search and our customers, since we heavily use and rely upon updateDocument to replace documents in the index as products in our catalog are frequently updated. Lucene’s atomicity ensures that the two separate operations done during updateDocument, delete and add, are never visible separately. When you refresh from another thread, you will either see the old document or the new one, but never both at the same time, and never neither. We take such a simple-sounding API guarantee for granted despite the very complex under-the-hood implementation.
But, finally, after sleeping on it, Simon boiled the problem down to a simple deterministic unit-test showing the bug and had an early idea on how to fix it! Simon went off and coded as usual at the speed of light, pushing his fix to a
feature branch for LUCENE-8962 (now deleted, how diligent). Many beasting and feedback iterations later, Simon opened one final PR, our collective 3rd attempt. Finally, Simon pushed the final implementation and backported to 8.6.0, without subsequent reverts! The feature finally lives! It was first released in Lucene 8.6.0.
And then there was refresh…
Lucene applications typically call refresh far more frequently than commit! refresh makes recently indexed documents searchable in near-real-time, while commit moves all index changes onto durable storage so your index will be intact even if the OS crashes or the computer loses its precious electricity.
Thanks to Simon finding a cleaner way to implement the original merge-on-commit feature, merge-on-refresh became surprisingly simple, relatively speaking, and Simon opened and iterated on this PR. We proceeded with our usual iterative feedback, beasting tests, and finally Simon pushed the new feature for Lucene 8.7.0. No reverts needed! Though, we probably should indeed have opened a separate dedicated issue since merge-on-refresh was in a later release (8.7.0).
Open-source sausage
This hidden story, right under our collective digital noses, of how these two powerful new Lucene features,merge-on-commit (in Lucene 8.6.0) and merge-on-refresh (in Lucene 8.7.0), were created serves as a powerful example of open-source sausage making at its best.
There are so many examples of strong open-source collaboration and lessons learned:
- Powerful changes emerge when diverse, cross-team, cross-corporation developers collaborate over open-source channels. If Amazon had built this feature and used it only internally, we might still have this subtle bug in
updateDocumentimpacting our customers. - Complex projects unfold right under our noses. Features like
merge-on-refreshtake many tries to complete. Open-source development is rarely in a straight line. - Good changes take time: the original issue was opened Sep 3 2019, merge-on-commit was finally pushed (3rd time) on June 27 2020, and
merge-on-refreshon August 24, 2020, and finally this blog post, on March 19, 2021 — 1.5 years total! - Feature branches (now since deleted) under source control are helpful for big changes that require collaboration across multiple developers, over non-trivial amounts of time.
- Iterative collaboration with harsh, raw and honest feedback that sometimes leads to complete rewrites by other developers to explore a different approach is normal.
- Reverting is perfectly fine and useful development tool — we used it twice here! Committing first to mainline, letting that bake for a few weeks, before backporting to a feature branch (8.x) is healthy.
- Complex features should be broken down into separable parts for easier iteration/consumption, especially when an initial proposed change is too controversial. In such cases we factor out separable, controversial parts into their own issues which are eventually developed later and perhaps committed. Such open-source crumbling can also happen later in the iterations as more clarity surfaces, as it did with Simon’s approach.
- Developers sometimes try to block changes because they might be too similar to other proposed changes, until the community can work out the way forward.
- Some bugs last a long time before being discovered! Our initial attempt broke Lucene’s atomicity and we did not catch this until very late (third try) in the iterations.
- When an exotic randomized unit test finally catches a failure, reproducible with a failing seed, we try to boil that precise failure down to small, self-contained deterministic (no randomness needed) unit test exposing the bug, then fix the bug and confirm the tests passes, and push both the new test case and the bug fix together.
- Randomized tests are powerful: given enough iterations they will uncover all sorts of fun, latent bugs. Lucene likely has many bugs waiting to be discovered by our randomized tests just by uncovering precisely the right failing seeds. This seems similar to ₿itcoin mining, without the monetary value!
- New features frequently begin life without being enabled by default, but discussions of how the new feature should default are important (it currently defaults to disabled).
- We make many mistakes! Complex open-source software is difficult to improve without also breaking things. We really should have opened a separate issue for both features.
And of course underlying all of the above is the strong passion of many diverse developers eager to continue improving Apache Lucene, bit by bit.
Patches welcome!
[I work at Amazon and the postings on this site are my own and do not necessarily represent Amazon’s positions]
Published on Java Code Geeks with permission by Michael Mc Candless , partner at our JCG program. See the original article here: Open-source collaboration, or how we finally added merge-on-refresh to Apache Lucene Opinions expressed by Java Code Geeks contributors are their own. |
