This series is about helping a team create a less brittle environment—more resilience. Part 1 was about individual work. This part is about shortening feedback loops.
Brief description of the problem at a recent client: Person A checked in code that broke an “unrelated” part of the system. I’ll call this checking in code in Email that broke Search. (Yes, I changed the names of the functionality because the names don’t matter.)
The managers didn’t understand. Neither did the team. However, they now had a production support problem that they needed to fix.
They had one piece of feedback: the checkin broke “unrelated” code. It was time to see their feedback loops.
See Your Feedback Loops
Every project (or effort) has at least one feedback loop. That’s when you release to customers.
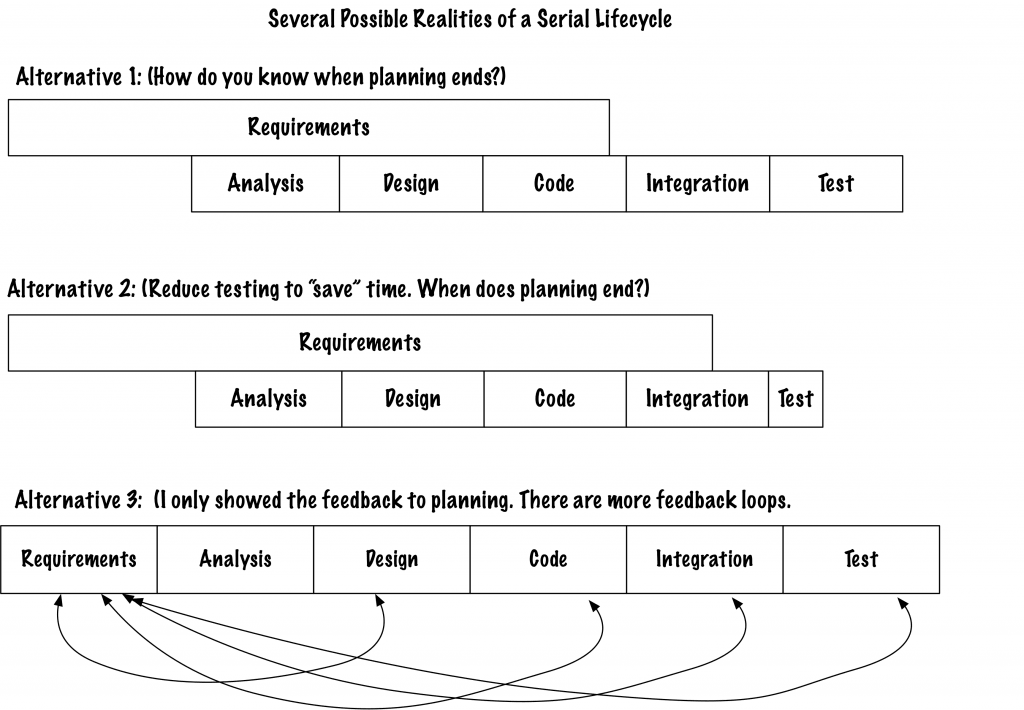
If you use a waterfall approach, you more likely have the undesired feedback loops, as in the image, “Several Possible Realities of a Serial Lifecycle.”
The more often you release internally, the more often you can get early feedback.
The more often you release to customers, the more validated feedback you can get. Production support issues are validated feedback. You might not like that feedback, but that’s customer feedback.
In this case, the project team had no automated tests. The team called the product people “product owners.” (They weren’t, but that’s a different problem.) These product people executed manual tests. Worse, they only tested the happy paths.
The product people didn’t know how to test the possible error paths. They didn’t know enough about the insides of the product to look for unwanted interactions.
Neither did the developers. These developers had no built-in feedback mechanisms.
Automated Tests Are About Feedback
A gajillion years ago, when I wrote code for a living, I wrote my tests after I wrote the code. I admit it.
I was extremely good at writing tests that ignored my errors. Yes, I would test everything except the places I had made mistakes. I became extremely good at reading octal or hex dumps (depending on the machine and language). (There was a time when I could read the Fortran stack trace and know exactly where I had screwed up. Oh, the bad old days.)
We have other tools now. We can use TDD, BDD, ATDD and get feedback before we write code. See these definitions:
I happen to like David Bernstein’s book, Beyond Legacy Code (Amazon) and on the Prags, as a way to integrate reasonable technical practices into your work now. (You might read the updated Pragmatic Programmer or any of the other test-driven books available. Heck, read them all to learn and practice.)
I learned about test-driven development in all its various forms after I stopped writing code professionally. However, I use the ideas of specification by example when I write, even though I write in a natural language (English).
You’ve noticed I often tell stories in my posts and books. Those are examples. I use them to help you realize the context and when that context does and does not apply to you. Just as important, the example grounds my writing and offers me feedback as I write.
I’m not perfect. I’m sure I go off on tangents in blog posts that leave you saying, “Huh?” Even so, the examples help give me feedback as I write. With any luck, I bring you along with me, even if I head off on a tangent.
This team decided to visualize their feedback loops.
How Long Are Your Feedback Loops?
You might think your feedback loops are pretty short. They might be. Have you measured your value stream to actually see your cycle time? See a “blank” value stream map in Measure Cycle Time, Not Velocity.
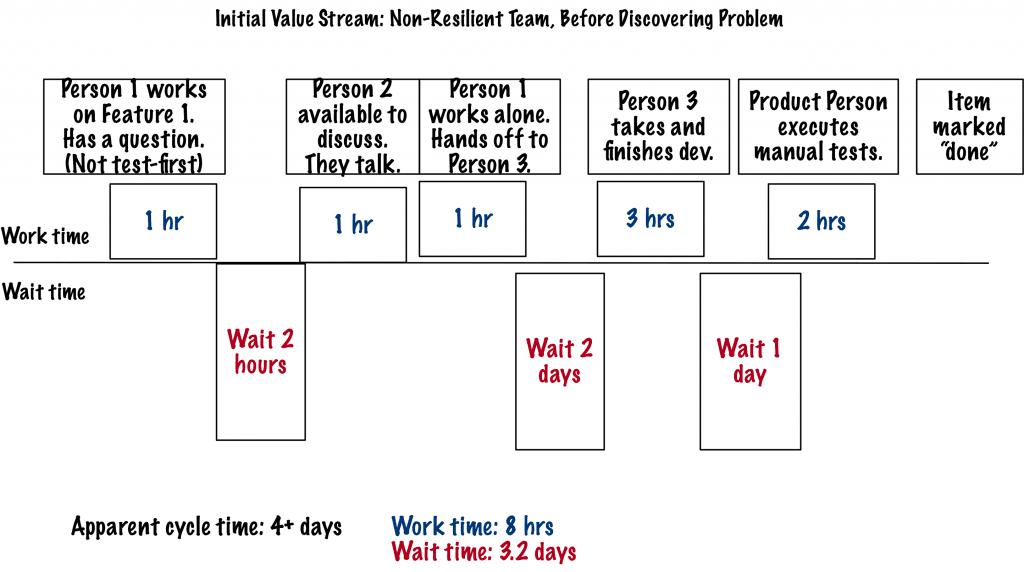
Here’s what this team’s value stream map looked like for just one feature. They hadn’t discovered the problem in this value stream.
Note that their work time is 1/4th the time they spent waiting.
But, three days after they checked in this “done” work, they discovered this problem where the Email checkin affected the Search.
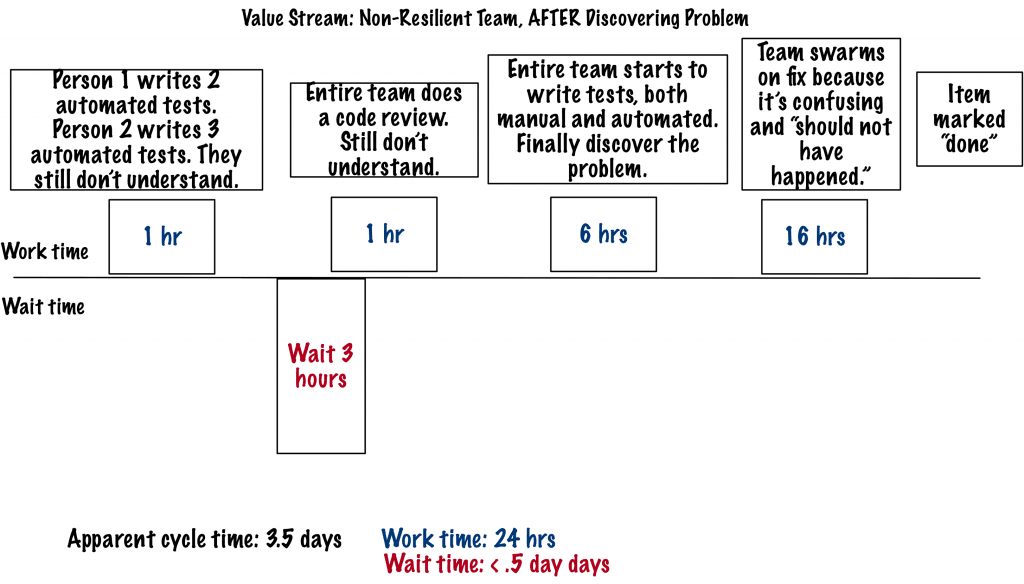
When they realized they had a problem with this checkin, they started to write tests and do a code review.
The team took another 3.5 days—on top of the previous 4+ days—to complete this work.
And, all their other work was delayed by these 3.5 days.
They were way behind now. All because they didn’t have enough short feedback loops.
More Frequent Feedback Helps Build Resilience
The more frequent your feedback, the more resilient your actions can be. This team wrote tests when they were under pressure, with a production support problem. They didn’t do a code review until they were stuck.
Tests—especially pervasive, small tests—can create resilience in a team. Even if you don’t work as a team (Part 1), tests can help you build resilience.
Tests provide support for change.
Here’s how I think about this:
- Create small chunks of work.
- Create pervasive automated tests so you know how to change the code when you need to. (Yes, there is a need for manual tests, and those often take much more time to run. I’m talking about automated tests here.)
- Measure how many feedback loops you have and their duration. (Consider measuring your cycle time.)
How did this team work themselves out of their hole(s)?
- First, they used user stories to define the work.
- They defined acceptance criteria for ATDD.
- They used (with some reluctance) a combination of TDD and BDD. They didn’t all agree on what to do. However, they started to write tests first. That helped them with the design, not the code.
- They measured their cycle time. After some practice, they managed to get their cycle time down to under a day.
The more you can do to shorten your feedback loops, the more resilience your team has.
The series:
- Build Team Resilience: Work Together (Part 1)
- Build Team Resilience: Shorten Feedback Loops (Part 2)
- Build Team Resilience: Work “Anywhere” and “Anytime” (Part 3)
- Build Team Resilience Summary (Part 4)
Published on Java Code Geeks with permission by Johanna Rothman , partner at our JCG program. See the original article here: Build Team Resilience: Shorten Feedback Loops (Part 2) Opinions expressed by Java Code Geeks contributors are their own. |
