Back when I was a manager, my senior management wanted to separate the “new” work from the “maintenance” work. I suggested that every new line after the first line of code was maintenance. The managers poo-poohed me. My concern: How would the “new” developers learn from their mistakes?
I lost that discussion and I managed a team called “continuing engineering,” CE. Their job: fight the fires so development wasn’t interrupted.
I hired people who wanted to fight fires. (Yes, they enjoyed that work.) And, they didn’t want to make “big” design decisions. Definitely no architecture.
CE was a small and mighty team of two people. They supported the customers because the 70+ developers focused on “new” work.
We were pretty successful for the first three months. A couple of “new” developers told me privately they were upset they didn’t have the time to work right. They were supposed to work fast.
The CE team did what we would now call refactoring as they fixed problems. They removed duplication in the code. They also fixed idiocies in the user interface.
CE successfully reduced the backlog of customer irritants. We didn’t have to fight as many fires. We relaxed a little with the fire-fighting and turned our attention to performance and reliability issues.
And, then, a funny thing occurred. At about the 4-month mark, the CE backlog grew. Why were we getting so many more incidents to resolve? I did a little investigation:
- The “new” devs were asked to work faster and faster. They didn’t get a chance to finish the work right.
- We had fixed problems that uncovered new problems.
- The “new” devs re-introduced problems into the codebase that we had fixed.
Time for Management Intervention. (That was me.)
Show the System
At the time, I didn’t know about value stream maps, measuring cycle time, or any of the tools I have now. I did know about Fault Feedback Ratio although I wasn’t as nice about the name as I am now.
I also measured this data:
- Cost to fix a defect
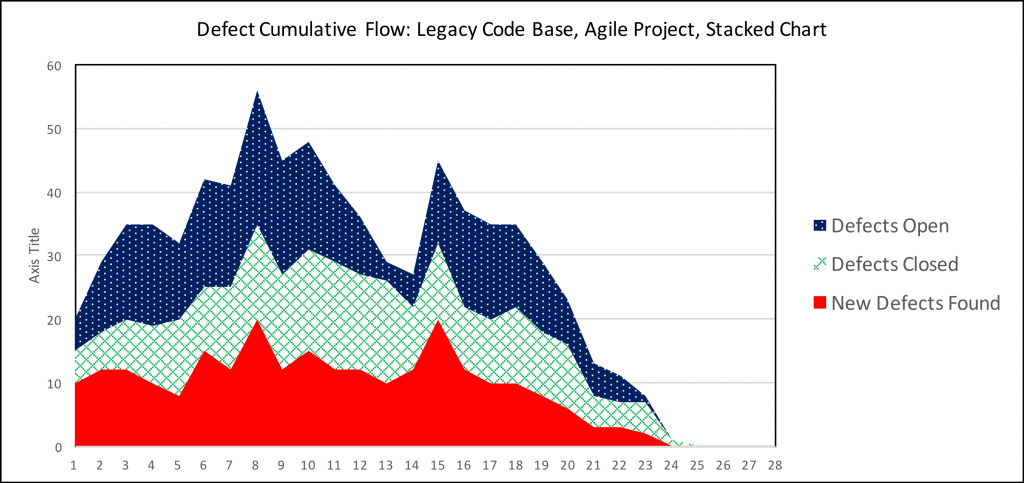
- Defect Cumulative Flow (the image above). (That image is from Create Your Succesful Agile Project.) Note that when we had more defects open than we could fix in a given week, the problems got a lot worse.
- Escaped defects (from development to customers)
Now, I could reason about the data and explain the issues to my managers.
We had a big problem: we had no feedback loops from CE to the “New” devs. The people working on the “new” work didn’t know what CE had done. In addition, the “new” devs were under tremendous pressure to finish fast, not correctly. (That’s because the so-called project managers were incented on meeting dates, not finishing features. And, those people did not push back on management’s idiotic requests.)
I was not happy about being right. We had a big problem.
Options for Managing “New” and “Maintenance” Work
I don’t see much difference between “new” and “maintenance” work. Once you’ve written a line of code (or a paragraph in a book), you figure out how to integrate any new lines into the current system.
It’s possible you know another approach. If you do, please let me know. But, for me, it’s about integrating changes with what’s already there.
I have a client now with this exact problem. A huge backlog of fixes and customer irritants. A huge backlog of new features. Management hungry for more throughput. The client is considering a maintenance group.
I’m not fond of that option. The client’s teams try to do code review, but they have so much pressure to deliver, they’re having trouble finding time for review.
Here are several other options:
- Pair on all work, so you get the benefit of integrating code review with the development work.
- Mob on all work so you reduce the team’s WIP and get immediate code and test review.
- Manage the project portfolio so the teams aren’t overloaded with work.
- Rank all new and maintenance work on a single backlog. Have not more than two items at one time for a team. (I discussed this a little in Might Three Backlogs Be Better Than One?)
The entire organization needs to see all the work. The managers need to see the volume of work, which is why I advocate backlogs you can see and pull from for a given team. Then, everyone should Clean Your Backlogs.
The teams need to see a little into the future so they don’t cut off their options too prematurely.
Notice that the teams can change a little about how they work. And, a lot of this problem is from management. Especially the “How much” instead of “How little” thinking.
What We Did
I got my management to reduce our organizational WIP and manage the project portfolio. I also worked with the project managers who were insisting that fast trumped well. I showed our data and didn’t quite yell at them, but I am sure I was insistent. I was probably louder than they were, too.
We had cross-functional teams. We delivered about once a month to our customers. We had a lot of good stuff in place.
I didn’t know about mobbing at the time. However, I advocated swarming and pairing and that was quite effective.
And, after about three months, we were back on track. We kept the CE group, but we started to act as investigators for problems that “shouldn’t have happened.” That was fine.
Should You Separate “New” Work from “Maintenance”?
I’m not a fan of separating work along the lines of “new” or “maintenance.” I find that separation suspect as a way to separate the work.
I much prefer that the people who create the problems fix those problems. Consider the options I suggested above.
If you do separate the work, make sure you have feedback loops between all the people. And, good luck. Oh, if you have an alternative to my ideas, I would love to hear it.
Published on Java Code Geeks with permission by Johanna Rothman , partner at our JCG program. See the original article here: Effects of Separating “New” Work vs “Maintenance” Work Opinions expressed by Java Code Geeks contributors are their own. |
