The big data challenge
The concept of big data is understood differently in the variety of domains where companies face the need to deal with increasing volumes of data. In most of these scenarios the system under consideration needs to be designed in such a way so that it is capable of processing that data without sacrificing throughput as data grows in size. This essentially leads to the necessity of building systems that are highly scalable so that more resources can be allocated based on the volume of data that needs to be processed at a given point in time.
Building such a system is a time-consuming and complex activity and for that reason a third-party frameworks and libraries can be used to provide the scalability requirements out of the box. There are already a number of good choices that can be used in Java applications and this article we will discuss briefly some of the most popular ones:
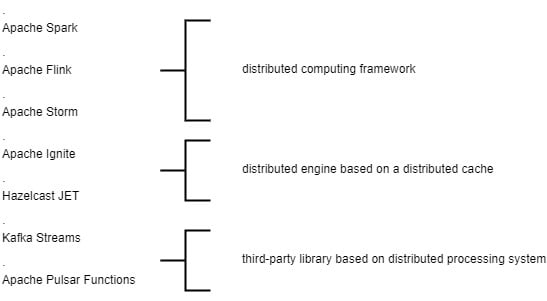
The frameworks in action
We are going to demonstrate each of the frameworks by implementing a simple pipeline for processing of data from devices that measure the air quality index for a given area. For simplicity we will assume that numeric data from the devices is either received in batches or in a streaming fashion. Throughout the examples we are going to use the THRESHOLD constant to denote the value above which we consider an area being polluted.
Apache Spark
In Spark we need to first convert the data into a proper format. We are going to use Datasets but we can also choose DataFrames or RDDs (Resilient Distributed Datasets) as an alternative for the data representation. We can then apply a number of Spark transformations and actions in order to process the data in a distributed fashion.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 | public long countPollutedRegions(String[] numbers) { // runs a Spark master that takes up 4 cores SparkSession session = SparkSession.builder(). appName("AirQuality"). master("local[4]"). getOrCreate(); // converts the array of numbers to a Spark dataset Dataset numbersSet = session.createDataset(Arrays.asList(numbers), Encoders.STRING()); // runs the data pipeline on the local spark long pollutedRegions = numbersSet.map(number -> Integer.valueOf(number), Encoders.INT()) .filter(number -> number > THRESHOLD).count(); return pollutedRegions; } |
If we want to change the above application to read data from an external source, write to an external data source and run it on a Spark cluster rather than a local Spark instance we would have the following execution flow:
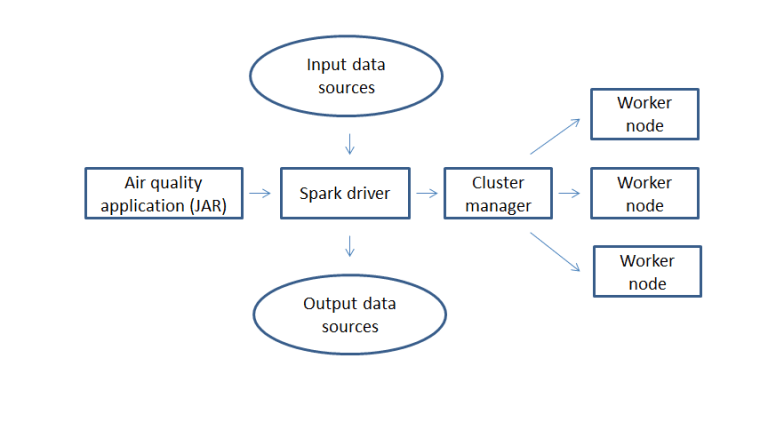
The Spark driver might be either a separate instance or part of the Spark cluster.
Apache Flink
Similarly to Spark we need to represent the data in a Flink DataSet and then apply the necessary transformations and actions over it:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 | public long countPollutedRegions(String[] numbers) throws Exception { // creates a Flink execution environment with proper configuration StreamExecutionEnvironment env = StreamExecutionEnvironment. createLocalEnvironment(); // converts the array of numbers to a Flink dataset and creates // the data pipiline DataStream stream = env.fromCollection(Arrays.asList(numbers)). map(number -> Integer.valueOf(number)) .filter(number -> number > THRESHOLD).returns(Integer.class); long pollutedRegions = 0; Iterator numbersIterator = DataStreamUtils.collect(stream); while(numbersIterator.hasNext()) { pollutedRegions++; numbersIterator.next(); } return pollutedRegions; } |
If we want to change the above application to read data from an external source, write to an external data source and run it on a Flink cluster we would have the following execution flow:
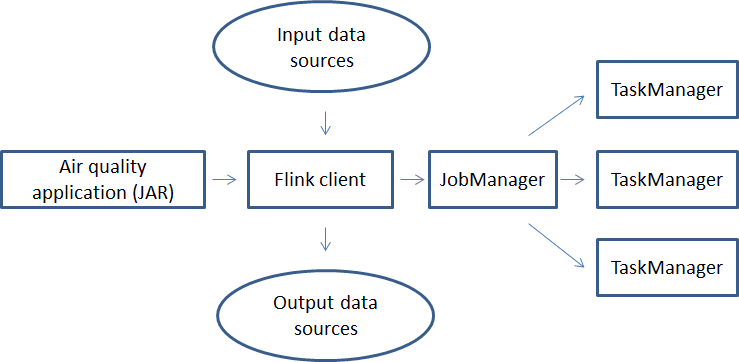
The Flink client where the application is submitted to the Flink cluster is either the Flink CLI utility or JobManager’s UI.
Apache Storm
In Storm the data pipeline is created as a topology of Spouts (the sources of data) and Bolts (the data processing units). Since Storm typically processes unbounded streams of data we will emulate the processing of an array of air quality index numbers as bounded stream:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | public void countPollutedRegions(String[] numbers) throws Exception { // builds the topology as a combination of spouts and bolts TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("numbers-spout", new StormAirQualitySpout(numbers)); builder.setBolt("number-bolt", new StormAirQualityBolt()). shuffleGrouping("numbers-spout"); // prepares Storm conf and along with the topology submits it for // execution to a local Storm cluster Config conf = new Config(); conf.setDebug(true); LocalCluster localCluster = null; try { localCluster = new LocalCluster(); localCluster.submitTopology("airquality-topology", conf, builder.createTopology()); Thread.sleep(10000); localCluster.shutdown(); } catch (InterruptedException ex) { localCluster.shutdown(); } } |
We have one spout that provides a data source for the array of air quality index numbers and one bolt that filters only the ones that indicate polluted areas:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | public class StormAirQualitySpout extends BaseRichSpout { private boolean emitted = false; private SpoutOutputCollector collector; private String[] numbers; public StormAirQualitySpout(String[] numbers) { this.numbers = numbers; } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("number")); } @Override public void open(Map paramas, TopologyContext context, SpoutOutputCollector collector) { this.collector = collector; } @Override public void nextTuple() { // we make sure that the numbers array is processed just once by // the spout if(!emitted) { for(String number : numbers) { collector.emit(new Values(number)); } emitted = true; } }} |
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | public class StormAirQualityBolt extends BaseRichBolt { private static final int THRESHOLD = 10; private int pollutedRegions = 0; @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("number")); } @Override public void prepare(Map params, TopologyContext context, OutputCollector collector) { } @Override public void execute(Tuple tuple) { String number = tuple.getStringByField("number"); Integer numberInt = Integer.valueOf(number); if (numberInt > THRESHOLD) { pollutedRegions++; } }} |
We are using a LocalCluster instance for submitting to a local Storm cluster which is convenient for development purposes but we want to submit the Storm topology to a production cluster. In that case we would have the following execution flow:
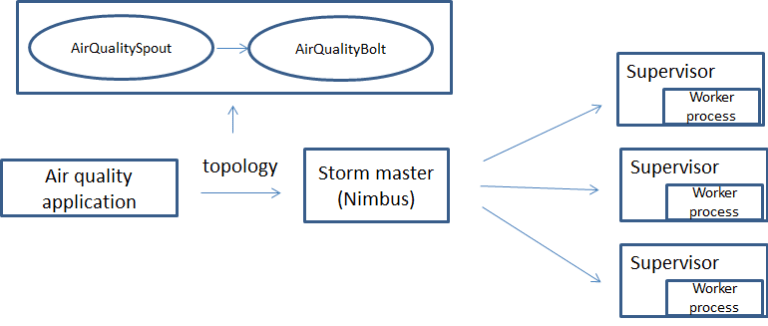
Apache Ignite
In Ignite we need first to put the data in the distributed cache before running the data processing pipeline which is the former of an SQL query executed in a distributed fashion over the Ignite cluster:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | public long countPollutedRegions(String[] numbers) { IgniteConfiguration igniteConfig = new IgniteConfiguration(); CacheConfiguration cacheConfig = new CacheConfiguration(); // cache key is number index in the array and value is the number cacheConfig.setIndexedTypes(Integer.class, String.class); cacheConfig.setName(NUMBERS_CACHE); igniteConfig.setCacheConfiguration(cacheConfig); try (Ignite ignite = Ignition.start(igniteConfig)) { IgniteCache cache = ignite.getOrCreateCache(NUMBERS_CACHE); // adds the numbers to the Ignite cache try (IgniteDataStreamer streamer = ignite.dataStreamer(cache.getName())) { int key = 0; for (String number : numbers) { streamer.addData(key++, number); } } // performs an SQL query over the cached numbers SqlFieldsQuery query = new SqlFieldsQuery("select * from String where _val > " + THRESHOLD); FieldsQueryCursor<List> cursor = cache.query(query); int pollutedRegions = cursor.getAll().size(); return pollutedRegions; }} |
If we want to run the application in an Ignite cluster it will have the following execution flow:
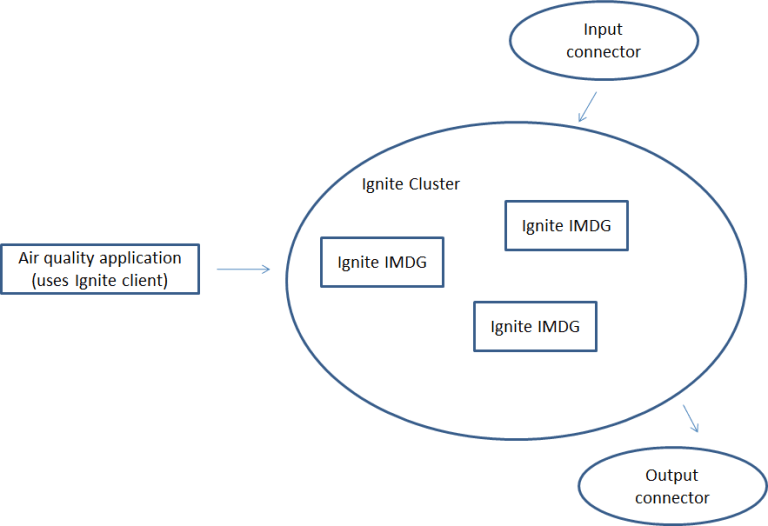
Hazelcast Jet
Hazelcast Jet works on top of Hazelcast IMDG and similarly to Ignite if we want to process data we need first to put it in the Hazelcast IMDG cluster:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | public long countPollutedRegions(String[] numbers) { // prepares the Jet data processing pipeline Pipeline p = Pipeline.create(); p.drawFrom(Sources.list("numbers")). map(number -> Integer.valueOf((String) number)) .filter(number -> number > THRESHOLD).drainTo(Sinks.list("filteredNumbers")); JetInstance jet = Jet.newJetInstance(); IList numbersList = jet.getList("numbers"); numbersList.addAll(Arrays.asList(numbers)); try { // submits the pipeline in the Jet cluster jet.newJob(p).join(); // gets the filtered data from Hazelcast IMDG List filteredRecordsList = jet.getList("filteredNumbers"); int pollutedRegions = filteredRecordsList.size(); return pollutedRegions; } finally { Jet.shutdownAll(); } } |
Note however that Jet also provides integration without of external data sources and data does not need to be stored in the IMDG cluster. You can also do the aggregation without first storing the data into a list (review the full example in Github that contains the improved version). Thanks to Jaromir and Can from Hazelcast engineering team for the valuable input.
If we want to run the application in a Hazelcast Jet cluster it will have the following execution flow:
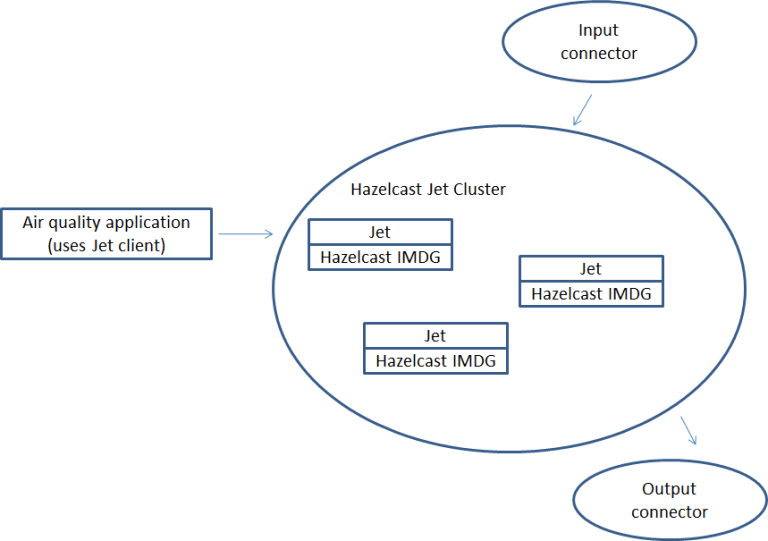
Kafka Streams
Kafka Streams is a client library that uses Kafka topics as sources and sinks for the data processing pipeline. To make use of the Kafka Streams library for our scenario we would be putting the air quality index numbers in a numbers Kafka topic:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | public long countPollutedRegions() { List result = new LinkedList(); // key/value pairs contain string items final Serde stringSerde = Serdes.String(); // prepares and runs the data processing pipeline final StreamsBuilder builder = new StreamsBuilder(); builder.stream("numbers", Consumed.with(stringSerde, stringSerde)) .map((key, value) -> new KeyValue(key, Integer.valueOf(value))). filter((key, value) -> value > THRESHOLD) .foreach((key, value) -> { result.add(value.toString()); }); final Topology topology = builder.build(); final KafkaStreams streams = new KafkaStreams(topology, createKafkaStreamsConfiguration()); streams.start(); try { Thread.sleep(10000); } catch (InterruptedException e) { e.printStackTrace(); } int pollutedRegions = result.size(); System.out.println("Number of severely polluted regions: " + pollutedRegions); streams.close(); return pollutedRegions; } private Properties createKafkaStreamsConfiguration() { Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "text-search-config"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); return props; } |
We will have the following execution flow for our Kafka Stream application instances:
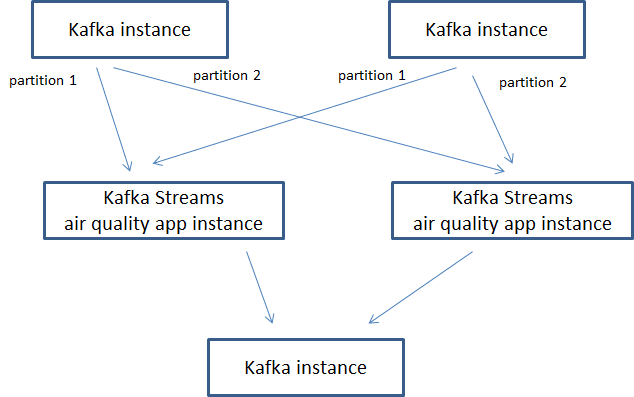
Pulsar Functions
Apache Pulsar Functions are lightweight compute processes that work in a serverless fashion along with an Apache Pulsar cluster. Assuming we are streaming our air quality index in a Pulsar cluster we can write a function to count the number of indexes that exceed the given threshold and write the result back to Pulsar as follows:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 | public class PulsarFunctionsAirQualityApplication implements Function { private static final int HIGH_THRESHOLD = 10; @Override public Void process(String input, Context context) throws Exception { int number = Integer.valueOf(input); if(number > HIGH_THRESHOLD) { context.incrCounter("pollutedRegions", 1); } return null; }} |
The execution flow of the function along with a Pulsar cluster is the following:
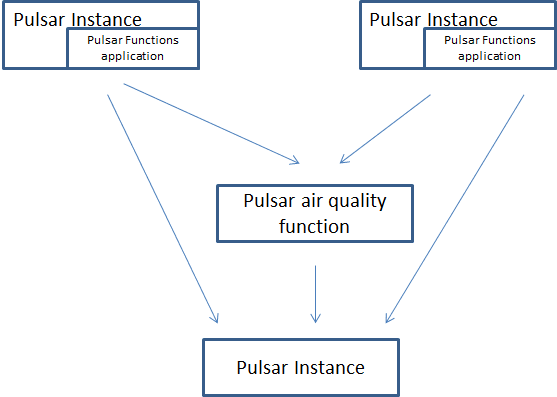
The Pulsar function can run either in the Pulsar cluster or as a separate application.
Summary
In this article we reviewed briefly some of the most popular frameworks that can be used to implement big data processing systems in Java. Each of the presented frameworks is fairly big and deserves a separate article on its own. Although quite simple our air quality index data pipeline demonstrates the way these frameworks operate and you can use that as a basis for expanding your knowledge in each one of them that might be of further interest. You can review the complete code samples here.
Published on Java Code Geeks with permission by Martin Toshev, partner at our JCG program. See the original article here: Popular frameworks for big data processing in Java Opinions expressed by Java Code Geeks contributors are their own. |
