Introduction:
In this tutorial, we’ll introduce you to Kubernetes and will discuss its architecture.
As a prerequisite, it’s good to have some basic knowledge of the container world.
Kubernetes & its Architecture:
Kubernetes, popularly known as K8s, is an open-source container orchestration engine for microservices-based containerized applications.
A K8s cluster comprises of a master and multiple worker nodes:
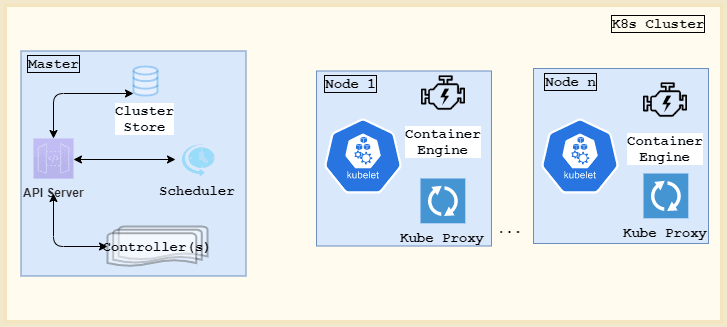
The master node is responsible for allocating work to all other configured nodes in the cluster.
Kubernetes Master:
A K8s master comprises of the following key components:
- kube-apiserver: We can think of the Kubernetes API Server as the only face of our K8s cluster. It exposes REST APIs and acts as a front-end interface to the entire control plane. It can consume the cluster’s desired state in the form of a JSON or YAML files
- kube-scheduler: assigns work to the cluster nodes
- kube-controller-manager: exposes a set of controllers including ingress, nodes, and namespace controllers
- Cluster Store: a persistent store responsible for storing the cluster’s desired state and other configurations
Kubernetes Nodes:
Let’s now talk about the Kubernetes worker nodes.
Every node will have:
- a Kubelet: A Kubelet watches the API server and is responsible for instantiating pods on a node. It also reports of any node state changes directly to the master
- Container Runtime Engine: We need a CRE(container runtime engine) to be able to pull images and start/stop containers. Docker is the most preferred container product in the market
- and, a kube-proxy: responsible for cluster networking and load-balancing among various pods running on a node
Kubectl:
The kubectl command-line utility helps us trigger commands to the API Server. For instance, to create or update a resource on our cluster, we’ll have:
kubectl apply -f deployment.yaml
where deployment.yaml is a file with our intended resource specifications.
Common Terminologies:
Now that we understand the architecture of a Kubernetes cluster, let’s look at some frequently used terminologies:
Namespaces:
With namespaces, we can logically split a physical cluster into many virtual clusters. This feature comes handy when we have multiple users or teams using our cluster resources. It enables us to have a more logical grouping of K8s objects.
Pods:
We can think of a pod as the smallest deployable unit in a K8s cluster. They get scheduled on the cluster nodes and are created/destroyed on demand.
A pod can be composed of one or more containers. All the containers running inside a single pod share the same IP address, network namespace, cgroups, etc. In most usual cases, we usually have a pod comprising of a single container.
ReplicaSets:
A replica set is a K8s object that defines and maintains the expected number of pod replicas at any point in time. If one of the pod goes down, another is brought up to keep up with the set expectations.
Deployments:
A K8s deployment is another layer of abstraction over ReplicaSets. Once we define a deployment manifest, we don’t need to explicitly define ReplicaSets and pods.
K8s deployments can manage and update replica sets. It also supports rollbacks.
Services:
Once a pod dies, the same pod can never be brought up again. The replacement pod that’s brought up will have a different IP address. And so, it’s hard to establish communication in that way.
A Kubernetes service is an abstraction acting as a gateway for a logical set of pods. With it, a client pod now just needs to know of the exposed service.
Conclusion:
In this tutorial, we looked at the Kubernetes architecture and explored a few important terminologies.
Published on Java Code Geeks with permission by Shubhra Srivastava, partner at our JCG program. See the original article here: Kubernetes: An Introduction Opinions expressed by Java Code Geeks contributors are their own. |

thanks
Glad it helped!