Apache Kafka is being increasingly integrated into a variety of systems and solutions, from filtering and processing large amounts of data real-time, to logging and creating metric data into a centralized handler from different sources. Using CData Sync, such solutions can easily be applied to any CRM, ERP or Analytics software.
Configuring Apache Kafka Destination for CData Sync
Setting up the Kafka destination in CData Sync is straightforward. Simply provide the “Server” and “Port,” then the replicate command can just take over — no additional configuration is required. To set up such a connection, first navigate to the Connections page, then click the Destinations tab, and select Kafka.
Specify the Server and Port properties. If authentication is enabled, specify the “User” and the “Password” properties as well. Click “Save Changes” and “Test Connection” to save your changes and ensure CData Sync can connect to the Kafka Server.
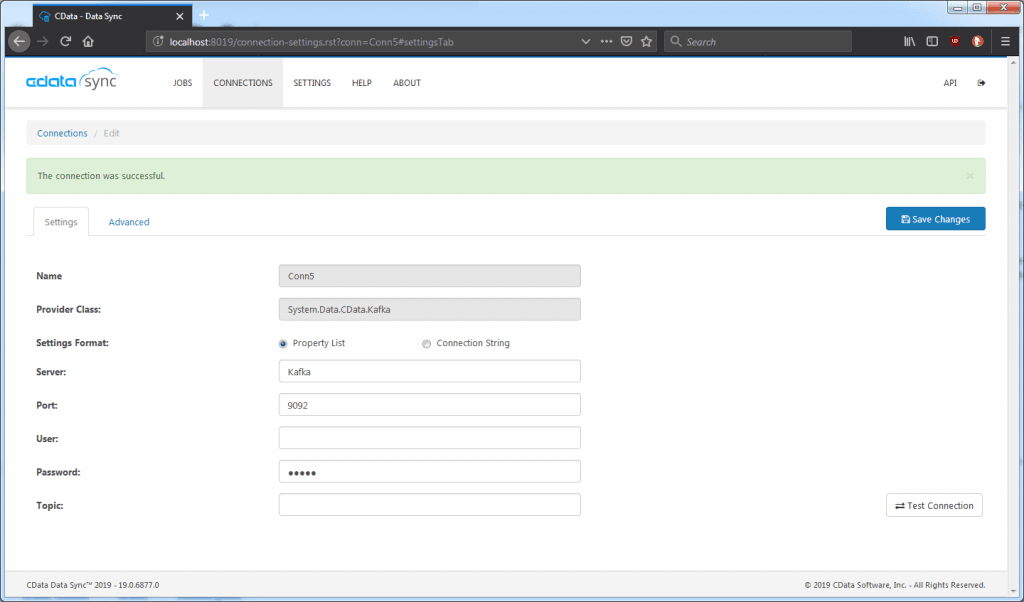
Some other properties are available and are categorized in the advanced tab:
- Enable Idempotence: Ensures messages are delivered only once. In certain scenarios, it is possible that the producer produces duplicate messages. To verify, the client can compare the number of results consumed against the “Records Affected” status after executing the job.
- Serialization Format: Specifies the format for produced messages; available values are JSON, XML, and CSV.
- Topic: If specified, the property will override the table name as the target topic for the replication.
How Incremental Updates Work
CData Sync makes incremental updates seamless. No configuration is required by the server, and all the necessary properties come pre-configured, depending on the Source and the source table.
Unlike other database tools like SQL Server, Kafka does not support a reliable way to store states. CData Sync uses a local SQLite Database to get around this issue. It will store the last time a table was replicated and use that timestamp to filter the latest records. Most enterprise systems provide a system column to specify the date a record was last updated, which can suffice for this purpose.
For example, the Accounts table in QuickBooks Online contains such a column. Replicating the table:

And running another replicate after modifying three records:

Some tables do not have an automatically updated column that holds the date the record was last updated. In such cases, there is no choice but to fully replicate the results from the start. Kafka provides a timestamp field attached to the messages, which can be used to distinguish the newer results.
The departments table in QuickBooks Online has no column to specify the last update time; replicating this table results in:

And running the replication one more time while adding two new records produces:

Optimizing Queries
There are different ways to manage the message size produced by CData Sync. Optimization may be required, depending on the Kafka server’s configuration, or be worth considering simply to give replication performance a small boost.
Compression Type: Specifies how the produced data is compressed. Available options are gzip, lz4, snappy, or none. Specifying a compression type other than “none” will reduce the message payload.
Maximum Batch Size: Specifies the maximum batch size (in bytes) to be sent in a single request. Batches are filled with whole messages. The batch can be sent ahead of time without being filled in case the batch has been waiting for some time. Lowering this value may reduce performance but may be necessary if the produced messages exceed the server’s maximum allowed message size.
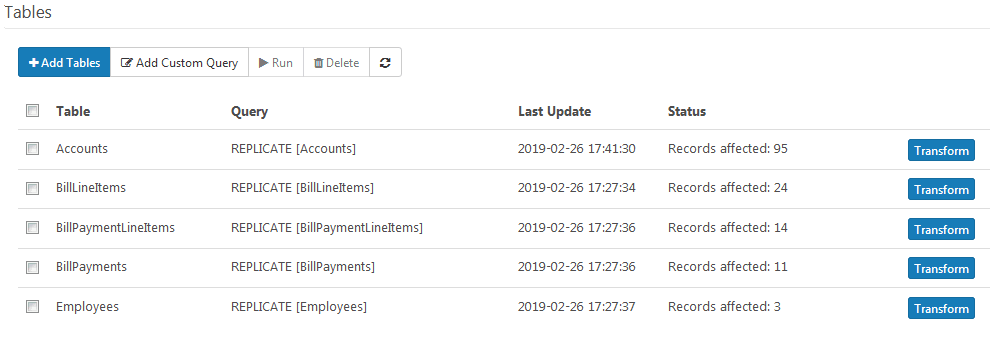
Exclude Columns: If a single record is too large in itself, the transform functionality provides a way to omit certain columns from the output message. This is most commonly used on aggregate columns. To exclude a column, navigate to the job and click the transform button adjacent to the desired table:
Next, deselect the aggregate column:
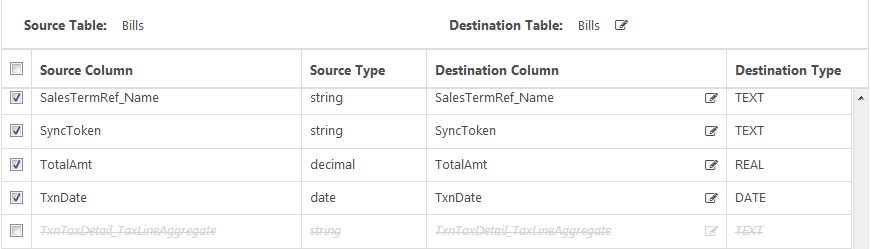
Finally, click “OK” to save.
Setting Up CData Sync to Manage Data Feeds
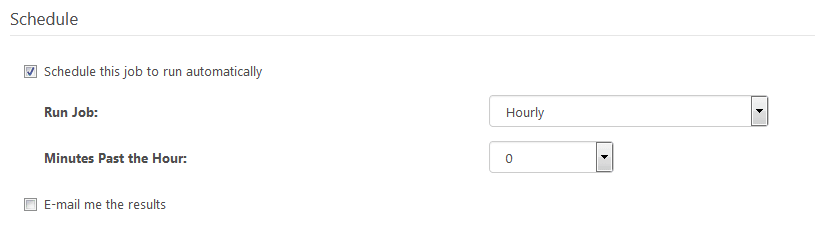
By using Scheduled Jobs, it is possible to set up completely automatic record ingestion, which can be used by Kafka consumers to always be up to date with new entries. The time can be adjusted depending on the need of the specific data set.
To schedule a job, select the desired job. Under the “Schedule” section, check the “Schedule this job to run automatically” box. Last, select the appropriate interval.
Conclusion
CData Sync and Apache Kafka can be a powerful combination; it is possible to replicate from any data source to Kafka consumers to support a range of requirements, from analytics to logging. Automatically detecting new records and scheduling jobs ensures a steady flow of new data to its subscribers. Compression, transformations, and other optimizations allow further control over data format, volume, and frequency. Download a free, 30-day trial of CData Sync and start streaming big data into Apache Kafka today!

