Development and IT Ops teams commonly find themselves in a game of tug-of-war between two key objectives: driving innovation and maintaining reliable (i.e. stable) software.
To drive innovation, we’re seeing the emergence of CI/CD practices and the rise of automation. To maintain reliability software, DevOps practices and Site Reliability Engineering are being adopted to ensure the stability of software in fast-paced dev cycles. Still, most organizations are finding that accelerating the delivery of software is easier than ensuring that it’s reliable.
The average release frequency at the enterprise level is about once a month (with many releasing more frequently), but when it comes to maintaining reliable software, our capabilities haven’t been improving quickly enough. One SRE Director at a Fortune 500 financial services company even told us they can’t deploy a new release without introducing at least one major issue.
These issues go beyond just the immediate loss of service. They hurt productivity, derail future product features, and jeopardize the customer experience – all while increasing infrastructure expenses. All this begs the question, how can we measure, understand and improve our capabilities when it comes to software reliability?
The Agility-Reliability Paradox
Enterprise development and IT Ops teams have various goals that they work towards, most of which fall under two main categories: driving innovation and maintaining application reliability (e.g. software quality). Too often, the pressure to out-innovate competitors comes at the expense of quality and reliability, where reliability is the probability of a piece of software operating without failure. As a result, most IT organizations experience significant code-level failures on a regular basis.
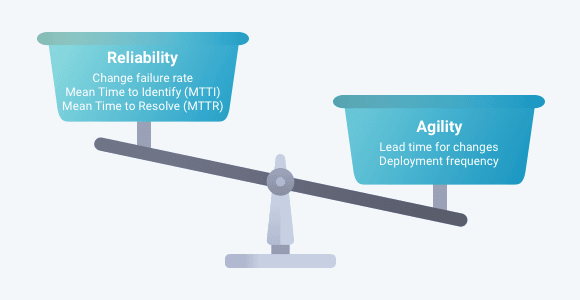
Derek D’Alessandro, a catalyst for DevOps adoption and technological change in the industry, has some unique insights regarding the effects of accelerated introduction of changes into our systems. In a post examining the different modes of change that teams can adopt, he says:
It is easy to see the benefit of individual changes. The trick to incremental change is measuring and planning out lots of small changes to ensure they all work together and are all headed in appropriate directions. This is an area in which we often create divergence in our systems, technologies or processes. The divergence sneaks up on us and we only discover it when things become unstable and start to topple, or cross integrations are too complex because it’s not built with a solid architecture.
Although this was taken from a post examining necessary steps for successfully adopting incremental and fundamental changes, the overall point that Derek makes is valid to this greater discussion of the Agility-Reliability Paradox. Namely, shipping new features and driving innovation is great, but not when it is detrimental to the reliability of our systems.
After many years of implementing new workflows to support faster releases, enterprise organizations are beginning to realize that new strategies are needed to ensure not only accelerated, but consistent and reliable delivery of code. The target is not just to ship code faster anymore, but also to close new and widening reliability gaps.
The Pillars of Continuous Reliability
After speaking with hundreds of engineering organizations in various stages of their reliability journeys, OverOps developed the concept of Continuous Reliability to help identify and further define the need for organizations to focus on reliability and stability in their systems.
Continuous Reliability
NOUN
The notion of balancing speed, complexity and quality by taking a continuous, proactive approach to reliability across the software delivery life cycle through data-driven quality gates and feedback loops.
Achieving Continuous Reliability means not only introducing more automation and data into your workflow, but also building a culture of accountability within your organization. This includes making reliability a priority beyond the confines of operations roles, and enforcing deeper collaboration and sharing of data across different teams in the software delivery lifecycle.
Continuous Reliability is dependent on two core capabilities: data collection and data analysis.
1. Data Collection
Reliability initiatives most often succeed or fail based on the quality of the data that engineering teams rely on. This quality is based on the methods used to capture the data as well as the depth of context they provide.
Many organizations struggle not only to identify every technical failure that occurs, but also to access enough data about known failures to investigate and resolve them. This includes insight into which deployment or microservice an error came from, historical context around when an issue was first or last seen, correlation with system metrics, insight into the source code and state of related variables and more. It is common for engineering teams to rely on manual and shallow data sources like log files when troubleshooting errors, which often demand an unrealistic amount of foresight to actually be useful.
2. Data Analysis
Even if you can capture all the data in the world, it’s only as meaningful as your ability to understand and leverage it in a timely manner. This is fairly obvious when we look again at log files. Sorting through millions of log statements by hand is not efficient or effective, which is why we use log analyzers to sort and analyze our logs for us.
There are many types of analysis we can perform to ensure reliability, though, going far beyond the log files. Static and dynamic analysis can be run on our code, machine learning and artificial intelligence can be applied to our system metrics… you get the picture.
Organizations with strong analysis (and data collection) capabilities are able to surface patterns and automatically prioritize issues based on code-level data and real-time analysis. This analysis serves as a foundation for implementing feedback loops from defining custom quality gates that prevent poor quality releases from ever making it to production.
First Steps to Continuous Reliability
When it comes to application reliability, it can be hard to know where to start. That’s why we put together a Continuous Reliability Maturity Model.
Using this model, engineering leaders will be able to chart a course to reach their goals for reliable and efficient execution. As organizations progress in their reliability maturity, they increase their signal to noise ratio, automate more processes and improve team culture. Finally, they are able to reap the benefits of productivity gains and a better customer experience, improving the overall bottom line for the business.
Read our full post about the Continuous Reliability Maturity Model!
Published on Java Code Geeks with permission by Tali Soroker, partner at our JCG program. See the original article here: Continuous Reliability: How to Move Fast and NOT Break Things Opinions expressed by Java Code Geeks contributors are their own. |
