DynamoDB has been a bit of a buzzword recently, so after years working on relational and document databases I decided to give it a try. A lot of the assumptions I had made about DynamoDb before working with it turned out to be false, so I am hoping that this series of blog posts will help you decide if DynamoDB is appropriate for your next project.
In this series of posts we will dive into DynamoDB and discover some of its quirks, which can differ a little from other databases. In this first post we will talk about what DynamoDB is and how it’s approach to primary keys works.
In the next post we will examine one of the most confusing aspects for people coming to DynamoDB from other databases – data retrieval – which works a little differently. We will see that, with a little help from indexes, we can achieve the most common use cases.
The third and final part of this series will be focused on availability and scalability which are two big advantages of DynamoDB as AWS handles them for us.
Before getting started let’s see where DynamoDB lives inside the database categories.
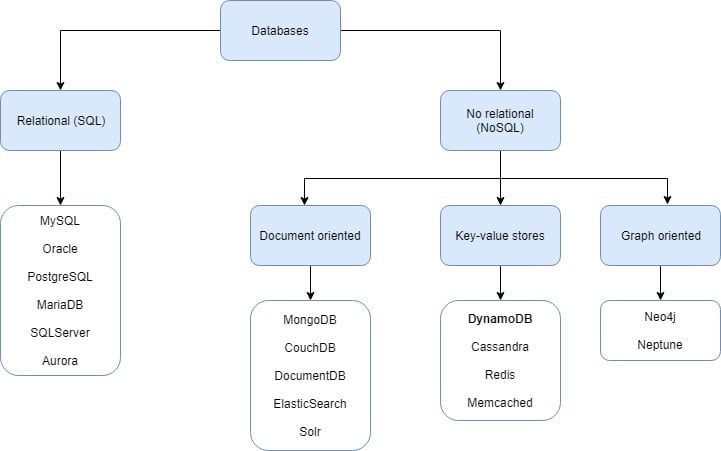
What is DynamoDB?
DynamoDB is a NoSQL, highly-available, low latency, scalable database that supports both key-value and document store data models. It follows a serverless approach, meaning that it is offered as a service, so the infrastructure is fully managed by AWS and works out-of-the-box with little configuration. This frees the user from managing instances, applying security patches and other infrastructure-related tasks. In addition, pricing can be very reasonable as it follows a pay-per-use model instead of charging for pre-provisioned computing resources.
Unlike most relational databases and also some NoSQL ones like MongoDB, DynamoDB lacks of the concept of instance. This means that the user works on tables directly. Moreover, tables are schemaless meaning that the objects stored in a table are not required to have the same attributes, providing more flexibility to the user.
DynamoDB shines when providing high performance for large workloads as it handles read and write throughput independently. Because of this, it is aimed at analytical operations but it can still work as a cheap, quick, low configuration solution for simple CRUD applications.
For ease of use, AWS provides an SDK for several languages including as Java, .NET, Node.js, PHP, Python, Ruby, Go, C++ and JavaScript for browsers and IoT devices. In addition to all that, requests can be made using JSON over HTTP.
What is it not?
Although it is capable of handling documents, don’t think of DynamoDB as a like-for-like replacement for MongoDB. It is built around the key-value data store model, so it bears more similarity to Redis or Memcached.
A key difference is that by default not all attributes of a document can be efficiently queried, only those that belong to a primary key or an index. This is because it’s high performance comes from searching for a specific element by its key, rather than filtering on other attributes. Moreover, DynamoDB does not support querying embedded data structures, nor does it provide full-text search or other features like MapReduce or date functions.
The DynamoDB Primary Key Approach
Like many databases, DynamoDB requires you to define a primary key that uniquely identifies an element in a table. DynamoDB uses primary keys slightly differently from some other databases as the key has a direct impact on how data is physically stored, which in turn is critical for it’s performance, as will be explained in the second part of this series. Similar to relational databases, the primary key can be simple or composite, the latter being compound of two attributes.
DynamoDB uses it’s own naming convention for keys. A simple key is referred to as a partition key, and when using a composite key the first part is called (and behaves as) a partition key, and the second part is the sort key.
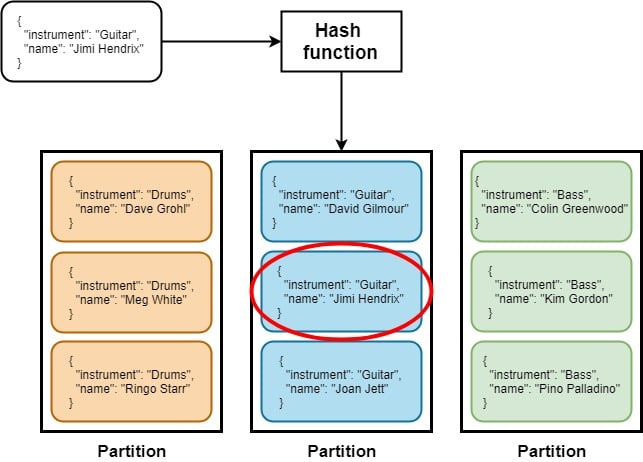
DynamoDB will create a physical partition on an SSD disk for each partition key. When retrieving data this value will be used as the input to a hash function, the result of which determines which partition the data is stored in.
When using a composite primary key, the second part is referred to as the sort key. This means that items will be stored together in the same partition and ordered by the sort key.
As a result, when using composite keys it is good practice to choose high-cardinality partition keys so physical partitions can be as small as possible, which gives maximum efficiency when querying data.
As an example see how it works when looking for Jimi:
Tune in for the second post of the series when we will talk about data retrieval and indexing. If meanwhile you want to give it a try please check An introduction to DynamoDB and its SDK post by my colleague Andre Torres for a hands-on introduction to DynamoDB SDK in Kotlin.
Published on Java Code Geeks with permission by Bartomeu Galmes, partner at our JCG program. See the original article here: DynamoDB explained – Part 1 Opinions expressed by Java Code Geeks contributors are their own. |
