Tuple is very powerful construct in programming language, it allows to create sequence of finite elements. Elements in tuple can be of different type and very easy to declare like (“something”,1,new Date())
Nice thing about tuple is you have to only decided on data type of element not the name.
Computer science has 2 hard problem : Cache invalidation and naming things.
Tuple helps with naming problem.
Nothing comes for free and every thing has some trade off. In this blog i will share dark side of tuple. I will take Scala tuple for example.
What are different ways to implement tuple ?
Class with object array
This is first option that comes to my mind, it is good for flexibility but bad for performance like
- type checks are expensive
- and has overhead of array index checking.
- parameter are of object type so puts memory pressure on both read and write.
- expensive to make immutable. We will talk about immutable later.
- no types so serialization will be big overhead
Class with fixed number of parameter.
This is better than the first one but it also has few issues
- Parameter are of object type so puts memory pressure
- Mutable unless framework or library generates code or maintain fixed layout objects like (Tuple, Tuple2, Tuple3…)
- Serialization overhead due to object type.
Scala is using fixed number of parameter approach.
In absence of Tuple poor man choice was to create class with N number of instance variable and give them proper type, scala has Case class which is based on old school thought.
Lets compare Tuple vs Case class. I will take tuple with 4 parameter and 2 of these are primitive type(Int & Double).
Tuple : (String,String,Int,Double)
Case class : case class Trade(symbol: String, exchange: String, qty: Int, price: Double)
Structure wise both are same and can be replace each other.
Memory Test
Benchmark create N instance of tuple/case class and putting it in collection and measure memory allocation.
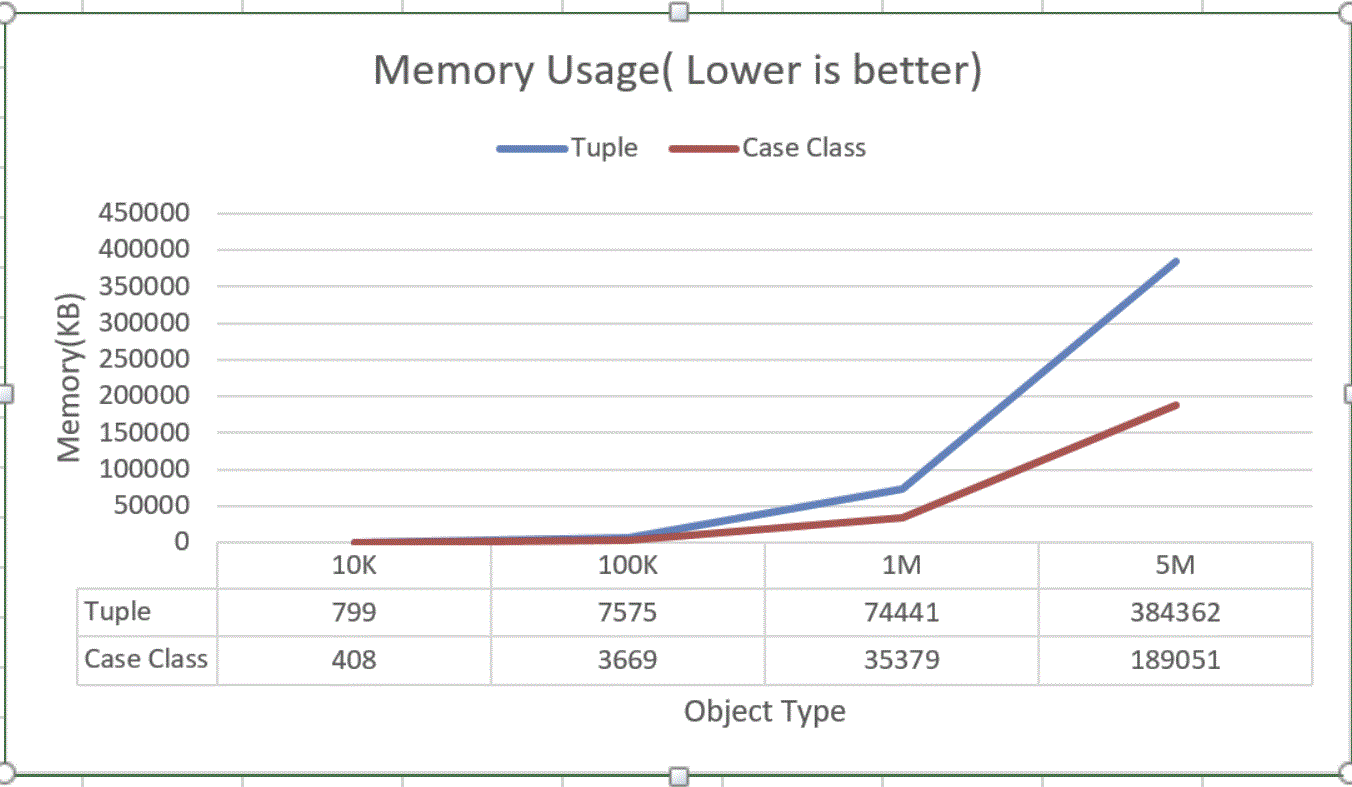
Memory usage for Tuple is double, for 5 Million object tuple takes 384 MB and case class takes just 189 MB.
Read performance test
In this test objects are allocated once and it is accessed to do basic aggregation.
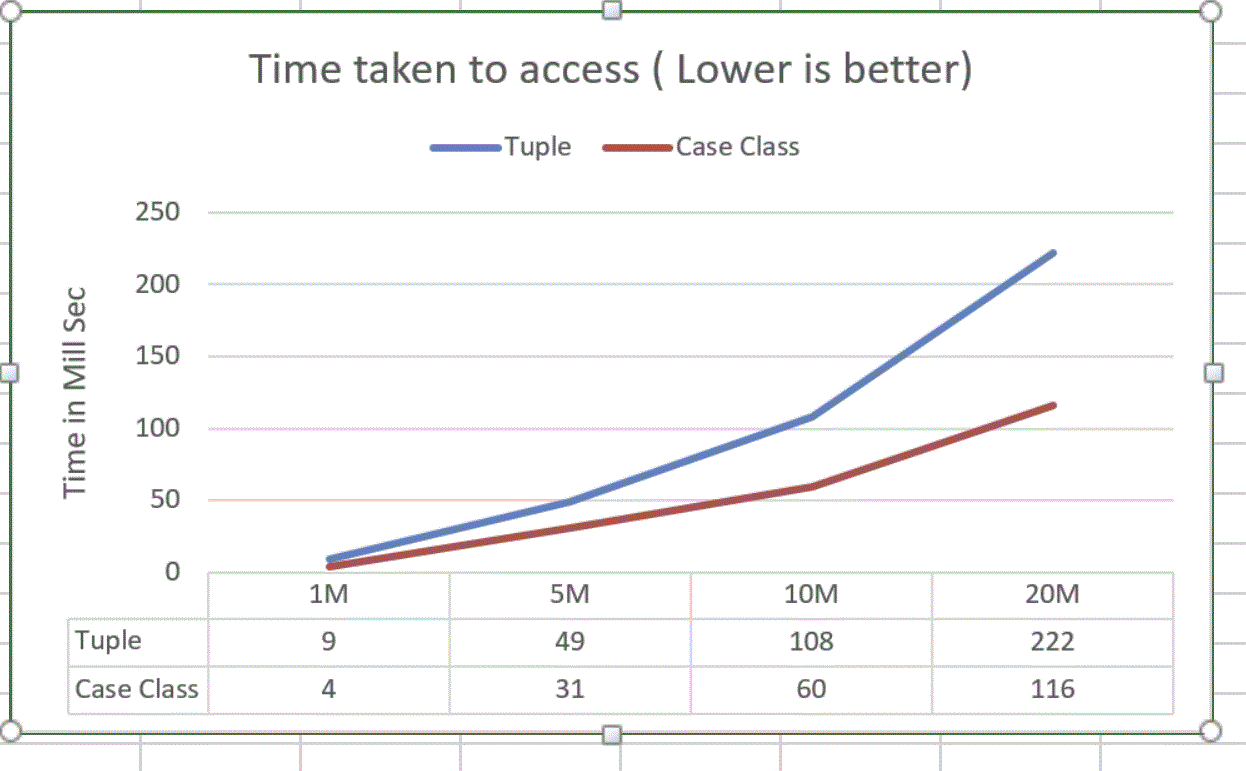
This chart show time taken to do sum on Double value for 1 Million,5 Million etc object.
Read from tuple is slow, it takes double the time.
One thing that is not shown in this chart is memory pressure created during read. Tuple put memory pressure during read.
These numbers shows that Tuple is not good both from memory and cpu usage.
Lets deep dive into the code that is generated for both tuple and case class to understand why we see these numbers.
I will put java code that is generated by Scala compiler.
/*
Code for (String,String,Int,Double)
*/
public class Tuple4<T1, T2, T3, T4> implements Product4<T1, T2, T3, T4>, Serializable
{
private final T1 _1;
public T1 _1(){return (T1)this._1;}
public T2 _2(){
return (T2)this._2;
}
public T3 _3(){
return (T3)this._3;
}
public T4 _4(){
return (T4)this._4;
}
}Scala does well to mark values final so it gets some read efficiency from that but all that is thrown away by creating object type and doing runtime type casting every time value is requested.
Case class code
/*
Code for
case class Trade(symbol: String, exchange: String, qty: Int, price: Double)
*/
public class Trade implements Product, Serializable
{
private final String symbol;
public double price(){
return this.price;
}
public int qty(){
return this.qty;
}
public String exchange(){
return this.exchange;
}
public String symbol(){
return this.symbol;
}
}For caseclass code scala is still using primitive type and that gives all the memory & cpu efficiency .
Spark is very popular large scale data processing framework and lot of production code is written using Tuple.
Tuple based transformation puts lots of load on GC and has impact on CPU utilization.
Since tuple is all based on Object type so it has effect on network transfer also.
Type info is very important for optimization and that is the reason why Spark 2 is based on Dataset which has compact representation.
So next time looking for quick improvement change Tuple to case class.
Code used for benchmarking is available @ githib
| Published on Java Code Geeks with permission by Ashkrit Sharma, partner at our JCG program. See the original article here: Scala Tuple performance Opinions expressed by Java Code Geeks contributors are their own. |
