In the previous article we created a simple indexing code that hammers ElasticSearch with thousands of concurrent requests. The only way to monitor the performance of our system was an old-school logging statement:
.window(Duration.ofSeconds(1))
.flatMap(Flux::count)
.subscribe(winSize -> log.debug("Got {} responses in last second", winSize));It’s fine, but on a production system, we’d rather have some centralized monitoring and charting solution for gathering various metrics. This becomes especially important once you have hundreds of different applications in thousands of instances. Having a single graphical dashboard, aggregating all important information, becomes crucial. We need two components in order to collect some metrics:
- publishing metrics
- collecting and visualizing them
Publishing metrics using Dropwizard Metrics
In Spring Boot 2 Dropwizard Metrics were replaced by Micrometer. This article uses the former, the next one will show the latter solution in practice. In order to take advantage of Dropwizard Metrics we must inject MetricRegistry or specific metrics into our business classes.
import com.codahale.metrics.Counter;
import com.codahale.metrics.MetricRegistry;
import com.codahale.metrics.Timer;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
@Component
@RequiredArgsConstructor
class Indexer {
private final PersonGenerator personGenerator;
private final RestHighLevelClient client;
private final Timer indexTimer;
private final Counter indexConcurrent;
private final Counter successes;
private final Counter failures;
public Indexer(PersonGenerator personGenerator, RestHighLevelClient client, MetricRegistry metricRegistry) {
this.personGenerator = personGenerator;
this.client = client;
this.indexTimer = metricRegistry.timer(name("es", "index"));
this.indexConcurrent = metricRegistry.counter(name("es", "concurrent"));
this.successes = metricRegistry.counter(name("es", "successes"));
this.failures = metricRegistry.counter(name("es", "failures"));
}
private Flux<IndexResponse> index(int count, int concurrency) {
//....
}
}So much boilerplate in order to add some metrics!
indexTimermeasures the time distribution (mean, median and various percentiles) of indexing requestsindexConcurrentmeasures how many requests are currently pending (requests sent, no response received yet); metric goes up and down over timesuccessandfailurescounts the total number of successful and failed indexing requests accordingly
We will get rid of the boilerplate in a second, but first, let’s see how it plays in our business code:
private Mono<IndexResponse> indexDocSwallowErrors(Doc doc) {
return indexDoc(doc)
.doOnSuccess(response -> successes.inc())
.doOnError(e -> log.error("Unable to index {}", doc, e))
.doOnError(e -> failures.inc())
.onErrorResume(e -> Mono.empty());
}This helper method above increments the number of successes and failures every time request completes. Moreover, it logs and swallows errors so that a single error or timeout does not interrupt the whole import process.
private <T> Mono<T> countConcurrent(Mono<T> input) {
return input
.doOnSubscribe(s -> indexConcurrent.inc())
.doOnTerminate(indexConcurrent::dec);
}Another method above increments the indexConcurrent metric when new request is sent and decrements it once result or error arrives. This metrics keeps going up and down, showing the number of in-flight requests.
private <T> Mono<T> measure(Mono<T> input) {
return Mono
.fromCallable(indexTimer::time)
.flatMap(time ->
input.doOnSuccess(x -> time.stop())
);
}The final helper method is the most complex. It measures the total time of indexing, i.e. the time between the request being sent and the response received. As a matter of fact, it’s quite generic, it simply calculates the total time between a subscription to arbitrary Mono<T> and when it completes. Why does it look so weird? Well, the basic Timer API is very simple
indexTimer.time(() -> someSlowCode())
It simply takes a lambda expression and measures how long did it took to invoke it. Alternatively you can create small Timer.Context object that remembers when it was created. When you call Context.stop() it reports this measurement:
final Timer.Context time = indexTimer.time(); someSlowCode(); time.stop();
With asynchronous streams it’s much harder. Starting of a task (denoted by subscription) and completion typically happens across thread boundaries in different places in code. What we can do is create (lazily) a new Context object (see: fromCallable(indexTimer::time)) and when wrapped stream completes, complete the Context (see: input.doOnSuccess(x -> time.stop()). This is how you compose all these methods:
personGenerator
.infinite()
.take(count)
.flatMap(doc ->
countConcurrent(measure(indexDocSwallowErrors(doc))), concurrency);That’s it, but polluting business code with so many low-level details of metric collecting seems odd. Let’s wrap these metrics with a specialized component:
@RequiredArgsConstructor
class EsMetrics {
private final Timer indexTimer;
private final Counter indexConcurrent;
private final Counter successes;
private final Counter failures;
void success() {
successes.inc();
}
void failure() {
failures.inc();
}
void concurrentStart() {
indexConcurrent.inc();
}
void concurrentStop() {
indexConcurrent.dec();
}
Timer.Context startTimer() {
return indexTimer.time();
}
}Now we can use a little it bit more high-level abstraction:
class Indexer {
private final EsMetrics esMetrics;
private <T> Mono<T> countConcurrent(Mono<T> input) {
return input
.doOnSubscribe(s -> esMetrics.concurrentStart())
.doOnTerminate(esMetrics::concurrentStop);
}
//...
private Mono<IndexResponse> indexDocSwallowErrors(Doc doc) {
return indexDoc(doc)
.doOnSuccess(response -> esMetrics.success())
.doOnError(e -> log.error("Unable to index {}", doc, e))
.doOnError(e -> esMetrics.failure())
.onErrorResume(e -> Mono.empty());
}
}In the next article we will learn how to compose all these methods even better. And avoid some boilerplate.
Publishing and visualizing metrics
Collecting metrics on its own is not enough. We must publish aggregated metrics periodically so that other systems can consume, process and visualize them. One such tool is Graphite and Grafana. But before we dive into configuring them, let’s first publish metrics to the console. I find this especially useful when troubleshooting metrics or during development.
import com.codahale.metrics.MetricRegistry;
import com.codahale.metrics.Slf4jReporter;
@Bean
Slf4jReporter slf4jReporter(MetricRegistry metricRegistry) {
final Slf4jReporter slf4jReporter = Slf4jReporter.forRegistry(metricRegistry.build();
slf4jReporter.start(1, TimeUnit.SECONDS);
return slf4jReporter;
}This simple code snippet takes an existing MetricRegistry and registers Slf4jReporter. Once every second you’ll see all metrics printed to your logs (Logback, etc.):
type=COUNTER, name=es.concurrent, count=1
type=COUNTER, name=es.failures, count=0
type=COUNTER, name=es.successes, count=1653
type=TIMER, name=es.index, count=1653, min=1.104664, max=345.139385, mean=2.2166538118720576,
stddev=11.208345077801448, median=1.455504, p75=1.660252, p95=2.7456, p98=5.625456, p99=9.69689, p999=85.062713,
mean_rate=408.56403102372764, m1=0.0, m5=0.0, m15=0.0, rate_unit=events/second, duration_unit=milliseconds
But that’s just or troubleshooting, in order to publish our metrics to an external Graphite instance, we need a GraphiteReporter:
import com.codahale.metrics.MetricRegistry;
import com.codahale.metrics.graphite.Graphite;
import com.codahale.metrics.graphite.GraphiteReporter;
@Bean
GraphiteReporter graphiteReporter(MetricRegistry metricRegistry) {
final Graphite graphite = new Graphite(new InetSocketAddress("localhost", 2003));
final GraphiteReporter reporter = GraphiteReporter.forRegistry(metricRegistry)
.prefixedWith("elastic-flux")
.convertRatesTo(TimeUnit.SECONDS)
.convertDurationsTo(TimeUnit.MILLISECONDS)
.build(graphite);
reporter.start(1, TimeUnit.SECONDS);
return reporter;
}Here I’m reporting to localhost:2003 where my Docker image with Graphite + Grafana happens to be. Once every second all metrics are sent to this address. We can later visualize all these metrics on Grafana:
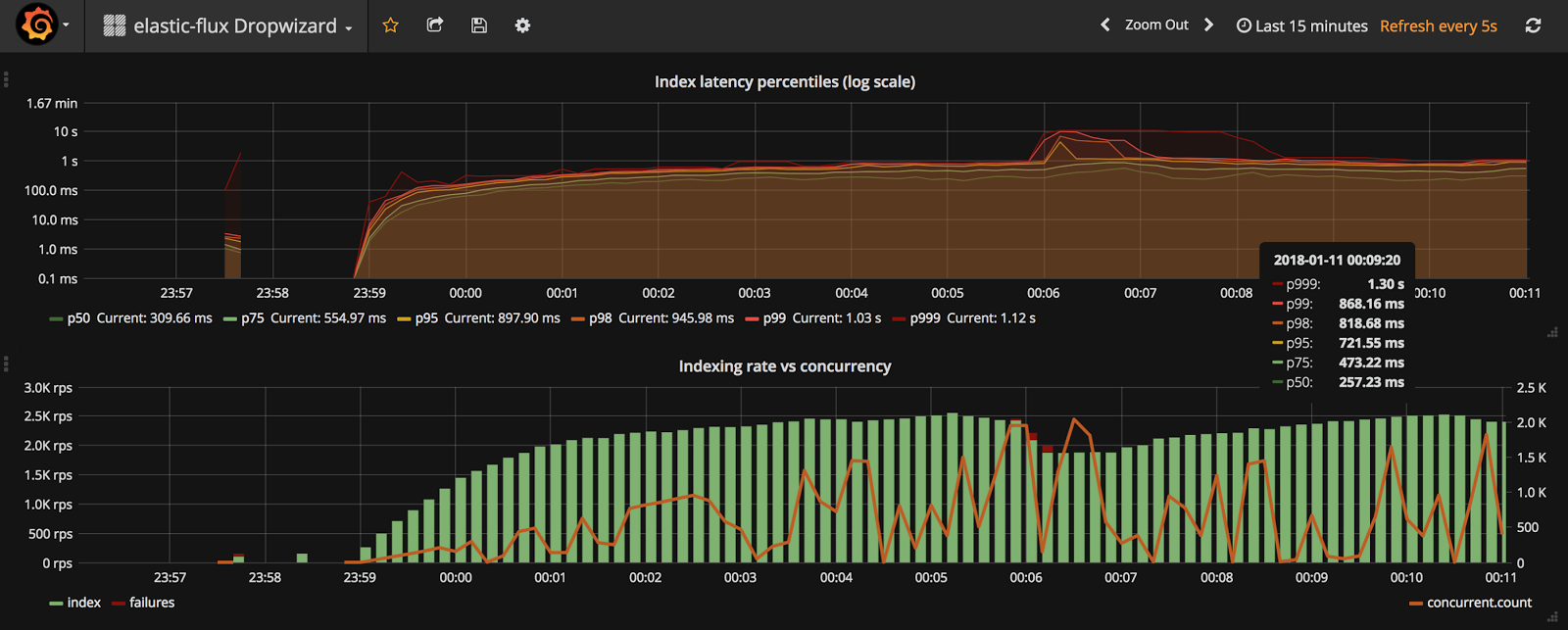
The top diagram displays the indexing time distribution (from 50th to 99.9th percentile). Using this diagram you can quickly discover what is the typical performance (P50) as well as (almost) worst case performance (P99.9). The logarithmic scale is unusual but in this case allows us to see both low and high percentiles. The bottom diagram is even more interesting. It combines three metrics:
- rate (requests per second) of successful index operations
- rate of failed operations (red bar, stacked on top of the green one)
- current concurrency level (right axis): number of in-flight request
This diagram shows the system throughput (RPS), failures and concurrency. Too many failures or unusually high concurrency level (many operations pending for response) might be a sign of some issues with your system. The dashboard definitionis available in the GitHub repository.
In the next article, we will learn how to migrate from Dropwizard Metrics to Micrometer. A very pleasant experience!
| Published on Java Code Geeks with permission by Tomasz Nurkiewicz, partner at our JCG program. See the original article here: Monitoring and measuring reactive application with Dropwizard Metrics Opinions expressed by Java Code Geeks contributors are their own. |
