1. Overview
In this tutorial, we will be building an application that takes HTML as an input and creates a Microsoft Excel Workbook with a RichText representation of the HTML that was provided. To generate the Microsoft Excel Workbook, we will be using Apache POI. To analyze the HTML, we will be using Jericho.
The full source code for this tutorial is available on Github.
2. What is Jericho?
Jericho is a java library that allows analysis and manipulation of parts of an HTML document, including server-side tags, while reproducing verbatim any unrecognized or invalid HTML. It also provides high-level HTML form manipulation functions. It is an open source library released under the following licenses: Eclipse Public License (EPL), GNU Lesser General Public License (LGPL), and Apache License.
I found Jericho to be very easy to use for achieving my goal of converting HTML to RichText.
3. pom.xml
Here are the required dependencies for the application we are building. Please take note that for this application we have to use Java 9. This is because of a java.util.regex appendReplacement method we use that has only been available since Java 9.
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.9.RELEASE</version> <relativePath /> <!-- lookup parent from repository --> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>9</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.7</version> </dependency> <dependency> <groupId>org.springframework.batch</groupId> <artifactId>spring-batch-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.15</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.15</version> </dependency> <!-- https://mvnrepository.com/artifact/net.htmlparser.jericho/jericho-html --> <dependency> <groupId>net.htmlparser.jericho</groupId> <artifactId>jericho-html</artifactId> <version>3.4</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> <optional>true</optional> </dependency> <!-- legacy html allow --> <dependency> <groupId>net.sourceforge.nekohtml</groupId> <artifactId>nekohtml</artifactId> </dependency> </dependencies>
4. Web page – Thymeleaf
We use Thymeleaf to create a basic webpage that has a form with a textarea. The source code for Thymeleaf page is available here on Github. This textarea could be replaced with a RichText Editor if we like, such as CKEditor. We just must be mindful to make the data for AJAX correct, using an appropriate setData method. There is a previous tutorial about CKeditor titled AJAX with CKEditor in Spring Boot.
5. Controller
In our controller, we Autowire JobLauncher and a Spring Batch job we are going to create called GenerateExcel. Autowiring these two classes allow us to run the Spring Batch Job GenerateExcel on demand when a POST request is sent to “/export”.
Another thing to note is that to ensure that the Spring Batch job will run more than once we include unique parameters with this code: addLong(“uniqueness”, System.nanoTime()).toJobParameters(). An error may occur if we do not include unique parameters because only unique JobInstances may be created and executed, and Spring Batch has no way of distinguishing between the first and second JobInstance otherwise.
@Controller
public class WebController {
private String currentContent;
@Autowired
JobLauncher jobLauncher;
@Autowired
GenerateExcel exceljob;
@GetMapping("/")
public ModelAndView getHome() {
ModelAndView modelAndView = new ModelAndView("index");
return modelAndView;
}
@PostMapping("/export")
public String postTheFile(@RequestBody String body, RedirectAttributes redirectAttributes, Model model)
throws IOException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException {
setCurrentContent(body);
Job job = exceljob.ExcelGenerator();
jobLauncher.run(job, new JobParametersBuilder().addLong("uniqueness", System.nanoTime()).toJobParameters()
);
return "redirect:/";
}
//standard getters and setters
}6. Batch Job
In Step1 of our Batch job, we call the getCurrentContent() method to get the content that was passed into the Thymeleaf form, create a new XSSFWorkbook, specify an arbitrary Microsoft Excel Sheet tab name, and then pass all three variables into the createWorksheet method that we will be making in the next step of our tutorial :
@Configuration
@EnableBatchProcessing
@Lazy
public class GenerateExcel {
List<String> docIds = new ArrayList<String>();
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
WebController webcontroller;
@Autowired
CreateWorksheet createexcel;
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.tasklet(new Tasklet() {
@Override
public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception, JSONException {
String content = webcontroller.getCurrentContent();
System.out.println("content is ::" + content);
Workbook wb = new XSSFWorkbook();
String tabName = "some";
createexcel.createWorkSheet(wb, content, tabName);
return RepeatStatus.FINISHED;
}
})
.build();
}
@Bean
public Job ExcelGenerator() {
return jobBuilderFactory.get("ExcelGenerator")
.start(step1())
.build();
}
}We have covered Spring Batch in other tutorials such as Converting XML to JSON + Spring Batch and Spring Batch CSV Processing.
7. Excel Creation Service
We use a variety of classes to create our Microsoft Excel file. Order matters when dealing with converting HTML to RichText, so this will be a focus.
7.1 RichTextDetails
A class with two parameters: a String that will have our contents that will become RichText and a font map.
public class RichTextDetails {
private String richText;
private Map<Integer, Font> fontMap;
//standard getters and setters
@Override
public int hashCode() {
// The goal is to have a more efficient hashcode than standard one.
return richText.hashCode();
}7.2 RichTextInfo
A POJO that will keep track of the location of the RichText and what not:
public class RichTextInfo {
private int startIndex;
private int endIndex;
private STYLES fontStyle;
private String fontValue;
// standard getters and setters, and the like7.3 Styles
A enum to contains HTML tags that we want to process. We can add to this as necessary:
public enum STYLES {
BOLD("b"),
EM("em"),
STRONG("strong"),
COLOR("color"),
UNDERLINE("u"),
SPAN("span"),
ITALLICS("i"),
UNKNOWN("unknown"),
PRE("pre");
// standard getters and setters7.4 TagInfo
A POJO to keep track of tag info:
public class TagInfo {
private String tagName;
private String style;
private int tagType;
// standard getters and setters7.5 HTML to RichText
This is not a small class, so let’s break it down by method.
Essentially, we are surrounding any arbitrary HTML with a div tag, so we know what we are looking for. Then we look for all elements within the div tag, add each to an ArrayList of RichTextDetails , and then pass the whole ArrayList to the mergeTextDetails method. mergeTextDetails returns RichtextString, which is what we need to set a cell value:
public RichTextString fromHtmlToCellValue(String html, Workbook workBook){
Config.IsHTMLEmptyElementTagRecognised = true;
Matcher m = HEAVY_REGEX.matcher(html);
String replacedhtml = m.replaceAll("");
StringBuilder sb = new StringBuilder();
sb.insert(0, "<div>");
sb.append(replacedhtml);
sb.append("</div>");
String newhtml = sb.toString();
Source source = new Source(newhtml);
List<RichTextDetails> cellValues = new ArrayList<RichTextDetails>();
for(Element el : source.getAllElements("div")){
cellValues.add(createCellValue(el.toString(), workBook));
}
RichTextString cellValue = mergeTextDetails(cellValues);
return cellValue;
}As we saw above, we pass an ArrayList of RichTextDetails in this method. Jericho has a setting that takes boolean value to recognize empty tag elements such as
: Config.IsHTMLEmptyElementTagRecognised. This can be important when dealing with online rich text editors, so we set this to true. Because we need to keep track of the order of the elements, we use a LinkedHashMap instead of a HashMap.
private static RichTextString mergeTextDetails(List<RichTextDetails> cellValues) {
Config.IsHTMLEmptyElementTagRecognised = true;
StringBuilder textBuffer = new StringBuilder();
Map<Integer, Font> mergedMap = new LinkedHashMap<Integer, Font>(550, .95f);
int currentIndex = 0;
for (RichTextDetails richTextDetail : cellValues) {
//textBuffer.append(BULLET_CHARACTER + " ");
currentIndex = textBuffer.length();
for (Entry<Integer, Font> entry : richTextDetail.getFontMap()
.entrySet()) {
mergedMap.put(entry.getKey() + currentIndex, entry.getValue());
}
textBuffer.append(richTextDetail.getRichText())
.append(NEW_LINE);
}
RichTextString richText = new XSSFRichTextString(textBuffer.toString());
for (int i = 0; i < textBuffer.length(); i++) {
Font currentFont = mergedMap.get(i);
if (currentFont != null) {
richText.applyFont(i, i + 1, currentFont);
}
}
return richText;
}As mentioned above, we are using Java 9 in order to use StringBuilder with the java.util.regex.Matcher.appendReplacement. Why? Well that’s because StringBuffer slower than StringBuilder for operations. StringBuffer functions are synchronized for thread safety and thus slower.
We are using Deque instead of Stack because a more complete and consistent set of LIFO stack operations is provided by the Deque interface:
static RichTextDetails createCellValue(String html, Workbook workBook) {
Config.IsHTMLEmptyElementTagRecognised = true;
Source source = new Source(html);
Map<String, TagInfo> tagMap = new LinkedHashMap<String, TagInfo>(550, .95f);
for (Element e : source.getChildElements()) {
getInfo(e, tagMap);
}
StringBuilder sbPatt = new StringBuilder();
sbPatt.append("(").append(StringUtils.join(tagMap.keySet(), "|")).append(")");
String patternString = sbPatt.toString();
Pattern pattern = Pattern.compile(patternString);
Matcher matcher = pattern.matcher(html);
StringBuilder textBuffer = new StringBuilder();
List<RichTextInfo> textInfos = new ArrayList<RichTextInfo>();
ArrayDeque<RichTextInfo> richTextBuffer = new ArrayDeque<RichTextInfo>();
while (matcher.find()) {
matcher.appendReplacement(textBuffer, "");
TagInfo currentTag = tagMap.get(matcher.group(1));
if (START_TAG == currentTag.getTagType()) {
richTextBuffer.push(getRichTextInfo(currentTag, textBuffer.length(), workBook));
} else {
if (!richTextBuffer.isEmpty()) {
RichTextInfo info = richTextBuffer.pop();
if (info != null) {
info.setEndIndex(textBuffer.length());
textInfos.add(info);
}
}
}
}
matcher.appendTail(textBuffer);
Map<Integer, Font> fontMap = buildFontMap(textInfos, workBook);
return new RichTextDetails(textBuffer.toString(), fontMap);
}We can see where RichTextInfo comes in to use here:
private static Map<Integer, Font> buildFontMap(List<RichTextInfo> textInfos, Workbook workBook) {
Map<Integer, Font> fontMap = new LinkedHashMap<Integer, Font>(550, .95f);
for (RichTextInfo richTextInfo : textInfos) {
if (richTextInfo.isValid()) {
for (int i = richTextInfo.getStartIndex(); i < richTextInfo.getEndIndex(); i++) {
fontMap.put(i, mergeFont(fontMap.get(i), richTextInfo.getFontStyle(), richTextInfo.getFontValue(), workBook));
}
}
}
return fontMap;
}Where we use STYLES enum:
private static Font mergeFont(Font font, STYLES fontStyle, String fontValue, Workbook workBook) {
if (font == null) {
font = workBook.createFont();
}
switch (fontStyle) {
case BOLD:
case EM:
case STRONG:
font.setBoldweight(Font.BOLDWEIGHT_BOLD);
break;
case UNDERLINE:
font.setUnderline(Font.U_SINGLE);
break;
case ITALLICS:
font.setItalic(true);
break;
case PRE:
font.setFontName("Courier New");
case COLOR:
if (!isEmpty(fontValue)) {
font.setColor(IndexedColors.BLACK.getIndex());
}
break;
default:
break;
}
return font;
}We are making use of the TagInfo class to track the current tag:
private static RichTextInfo getRichTextInfo(TagInfo currentTag, int startIndex, Workbook workBook) {
RichTextInfo info = null;
switch (STYLES.fromValue(currentTag.getTagName())) {
case SPAN:
if (!isEmpty(currentTag.getStyle())) {
for (String style : currentTag.getStyle()
.split(";")) {
String[] styleDetails = style.split(":");
if (styleDetails != null && styleDetails.length > 1) {
if ("COLOR".equalsIgnoreCase(styleDetails[0].trim())) {
info = new RichTextInfo(startIndex, -1, STYLES.COLOR, styleDetails[1]);
}
}
}
}
break;
default:
info = new RichTextInfo(startIndex, -1, STYLES.fromValue(currentTag.getTagName()));
break;
}
return info;
}We process the HTML tags:
private static void getInfo(Element e, Map<String, TagInfo> tagMap) {
tagMap.put(e.getStartTag()
.toString(),
new TagInfo(e.getStartTag()
.getName(), e.getAttributeValue("style"), START_TAG));
if (e.getChildElements()
.size() > 0) {
List<Element> children = e.getChildElements();
for (Element child : children) {
getInfo(child, tagMap);
}
}
if (e.getEndTag() != null) {
tagMap.put(e.getEndTag()
.toString(),
new TagInfo(e.getEndTag()
.getName(), END_TAG));
} else {
// Handling self closing tags
tagMap.put(e.getStartTag()
.toString(),
new TagInfo(e.getStartTag()
.getName(), END_TAG));
}
}7.6 Create Worksheet
Using StringBuilder, I create a String that is going to written to FileOutPutStream. In a real application this should be user defined. I appended my folder path and filename on two different lines. Please change the file path to your own.
sheet.createRow(0) creates a row on the very first line and dataRow.createCell(0) creates a cell in column A of the row.
public void createWorkSheet(Workbook wb, String content, String tabName) {
StringBuilder sbFileName = new StringBuilder();
sbFileName.append("/Users/mike/javaSTS/michaelcgood-apache-poi-richtext/");
sbFileName.append("myfile.xlsx");
String fileMacTest = sbFileName.toString();
try {
this.fileOut = new FileOutputStream(fileMacTest);
} catch (FileNotFoundException ex) {
Logger.getLogger(CreateWorksheet.class.getName())
.log(Level.SEVERE, null, ex);
}
Sheet sheet = wb.createSheet(tabName); // Create new sheet w/ Tab name
sheet.setZoom(85); // Set sheet zoom: 85%
// content rich text
RichTextString contentRich = null;
if (content != null) {
contentRich = htmlToExcel.fromHtmlToCellValue(content, wb);
}
// begin insertion of values into cells
Row dataRow = sheet.createRow(0);
Cell A = dataRow.createCell(0); // Row Number
A.setCellValue(contentRich);
sheet.autoSizeColumn(0);
try {
/////////////////////////////////
// Write the output to a file
wb.write(fileOut);
fileOut.close();
} catch (IOException ex) {
Logger.getLogger(CreateWorksheet.class.getName())
.log(Level.SEVERE, null, ex);
}
}8. Demo
We visit localhost:8080.
We input some text with some HTML:
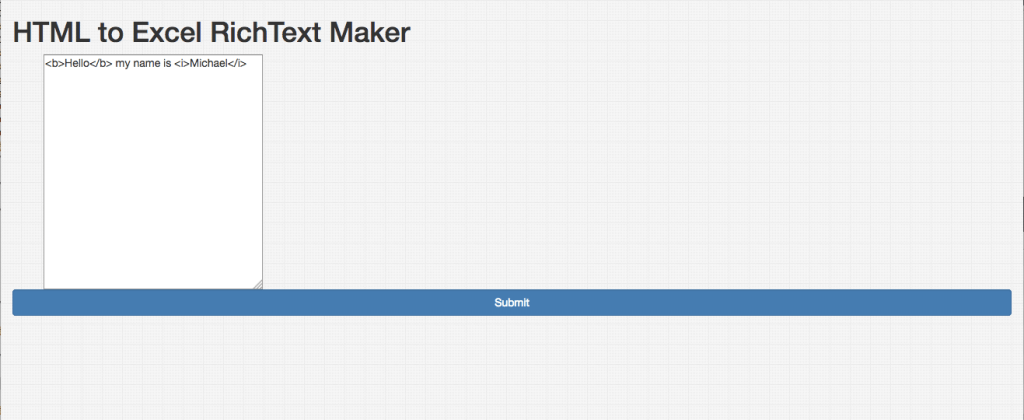
We open up our excel file and see the RichText we created:

9. Conclusion
We can see it is not trivial to convert HTML to Apache POI’s RichTextString class; however, for business applications converting HTML to RichTextString can be essential because readability is important in Microsoft Excel files. There’s likely room to improve upon the performance of the application we build, but we covered the foundation of building such an application .
The full source code is available on Github.
| Published on Java Code Geeks with permission by Michael Good, partner at our JCG program. See the original article here: Converting HTML to RichTextString for Apache POI Opinions expressed by Java Code Geeks contributors are their own. |
