I am certainly late with jumping on the trendy train, but today we are going to talk about GraphQL, a very interesting approach to build REST(ful) web services and APIs. In my opinion, it would be fair to restate that REST(ful) architecture is built on top of quite reasonable principles and constraints (although the debates over that are never ending in the industry).
So … what is GraphQL? By and large, it is yet another kind of the query language. But what makes it interesting, it is designed to give the clients (f.e., the frontends) the ability to express their needs (f.e., to the backends) in terms of data they are expecting. Frankly speaking, GraphQL goes much further than that but this is the one of its most compelling features.
GraphQL is just a specification, without any particular requirements to the programming language or technology stack but, not surprisingly, it got the widespread acceptance in modern web development, both on client-side (Apollo, Relay) and server-side (the class of APIs often called BFFs these days). In today’s post we are going to give GraphQL a ride, discuss where it could be a good fit and why you may consider adopting it. Although there quite a few options on the table, Sangria, terrific Scala-based implementation of GraphQL specification, would be the foundation we are going to build atop.
Essentially, our goal is to develop a simple user management web API. The data model is far from being complete but good enough to serve its purpose. Here is the User class.
case class User(id: Long, email: String, created: Option[LocalDateTime],
firstName: Option[String], lastName: Option[String], roles: Option[Seq[Role.Value]],
active: Option[Boolean], address: Option[Address])The Role is a hardcoded enumeration:
object Role extends Enumeration {
val USER, ADMIN = Value
}While the Address is another small class in the data model:
case class Address(street: String, city: String, state: String, zip: String, country: String)
In its core, GraphQL is strongly typed. That means, the application specific models should be somehow represented in GraphQL. To speak naturally, we need to define schema. In Sangria, schema definitions are pretty straightforward and consist of three main categories, borrowed from GraphQL specification: object types, query types and mutation types. All of these we are going to touch upon, but the object type definitions sounds like a logical point to start with.
val UserType = ObjectType(
"User",
"User Type",
interfaces[Unit, User](),
fields[Unit, User](
Field("id", LongType, Some("User id"), tags = ProjectionName("id") :: Nil,
resolve = _.value.id),
Field("email", StringType, Some("User email address"),
resolve = _.value.email),
Field("created", OptionType(LocalDateTimeType), Some("User creation date"),
resolve = _.value.created),
Field("address", OptionType(AddressType), Some("User address"),
resolve = _.value.address),
Field("active", OptionType(BooleanType), Some("User is active or not"),
resolve = _.value.active),
Field("firstName", OptionType(StringType), Some("User first name"),
resolve = _.value.firstName),
Field("lastName", OptionType(StringType), Some("User last name"),
resolve = _.value.lastName),
Field("roles", OptionType(ListType(RoleEnumType)), Some("User roles"),
resolve = _.value.roles)
))In many respects, it is just direct mapping from the User to UserType. Sangria can easy you off from doing that by providing macros support so you may get the schema generated at compile time. The AddressType definition is very similar, let us skip over it and look on how to deal with enumeration, like Roles.
val RoleEnumType = EnumType(
"Role",
Some("List of roles"),
List(
EnumValue("USER", value = Role.USER, description = Some("User")),
EnumValue("ADMIN", value = Role.ADMIN, description = Some("Administrator")
))Easy, simple and compact … In traditional REST(ful) web services the metadata about the resources is not generally available out of the box. However, several complimentary specifications, like JSON Schema, could fill this gap with a bit of work.
Good, so types are there, but what are these queries and mutations? Query is a special type within GraphQL specification which basically describes how you would like to fetch the data and the shape of it. For example, there is often a need to get user details by its identifier, which could be expressed by following GraphQL query:
query {
user(id: 1) {
email
firstName
lastName
address {
country
}
}
}You can literally read it as-is: lookup the user with identifier 1 and return only his email, first and last names, and address with the country only. Awesome, not only GraphQL queries are exceptionally powerful, but they are giving the control of what to return back to the interested parties. Priceless feature if you have to support a diversity of different clients without exploding the amount of API endpoints. Defining the query types in Sangria is also a no-brainer, for example:
val Query = ObjectType(
"Query", fields[Repository, Unit](
Field("user", OptionType(UserType), arguments = ID :: Nil,
resolve = (ctx) => ctx.ctx.findById(ctx.arg(ID))),
Field("users", ListType(UserType),
resolve = Projector((ctx, f) => ctx.ctx.findAll(f.map(_.name))))
))There are two queries in fact which the code snippet above describes. The one we have seen before, fetching user by identifier, and another one, fetching all users. Here is a quick example of latter:
query {
users {
id
email
}
}Hopefully you would agree that no explanations needed, the intent is clear. Queries arguably are the strongest argument in favor of adopting GraphQL, the value proposition is really tremendous. With Sangria you do have access to the fields which clients want back, so the data store could be told to return only these subsets, using projections, selects, or similar concepts. To be closer to reality, our sample application stores data in MongoDB so we could ask it to return only fields the client is interested in.
def findAll(fields: Seq[String]): Future[Seq[User]] = collection.flatMap(
_.find(document())
.projection(
fields
.foldLeft(document())((doc, field) => doc.merge(field -> BSONInteger(1)))
)
.cursor[User]()
.collect(Int.MaxValue, Cursor.FailOnError[Seq[User]]())
)If we get back to the typical REST(ful) web APIs, the approach most widely used these days to outline the shape of the desired response is to pass a query string parameter, for example /api/users?fields=email,firstName,lastName, …. However, from the implementation perspective, not many frameworks support such features natively, so everyone has to come up with their own way. Regarding the querying capabilities, in case you happen to be the user of terrific Apache CXF framework, you may benefit from its quite powerful search extension, which we have talked about some time ago.
If queries usually just fetch data, mutations are serving the purpose of the data modification. Syntactically they are very similar to queries but their interpretation is different. For example, here is one of the ways we could add new user to the application.
mutation {
add(email: "a@b.com", firstName: "John", lastName: "Smith", roles: [ADMIN]) {
id
active
email
firstName
lastName
address {
street
country
}
}
}In this mutation a new user John Smith with email a@b.com and ADMIN role assigned is going to be added to the system. As with queries, client is always in control which data shape it needs from server when mutation completes. Mutations could be think of as the calls for action and resemble a lot method invocations, for example the activation of the user may be done like that:
mutation {
activate(id: 1) {
active
}
}In Sangria, mutations are described exactly like queries, for example the ones we have looked at before have the following type definition:
val Mutation = ObjectType(
"Mutation", fields[Repository, Unit](
Field("activate", OptionType(UserType),
arguments = ID :: Nil,
resolve = (ctx) => ctx.ctx.activateById(ctx.arg(ID))),
Field("add", OptionType(UserType),
arguments = EmailArg :: FirstNameArg :: LastNameArg :: RolesArg :: Nil,
resolve = (ctx) => ctx.ctx.addUser(ctx.arg(EmailArg), ctx.arg(FirstNameArg),
ctx.arg(LastNameArg), ctx.arg(RolesArg)))
))With that, our GraphQL schema is complete:
val UserSchema = Schema(Query, Some(Mutation))
That’s great, however … what we can do with it? Just in time question, please welcome GraphQL server. As we remember, there is no attachment to particular technology or stack, but in the universe of web APIs you can think of GraphQL server as a single endpoint which is bound to POST HTTP verb. And, once we started to talk about HTTP and Scala, who could do better job than amazing Akka HTTP, luckily Sangria has a seamless integration with it.
val route: Route = path("users") {
post {
entity(as[String]) { document =>
QueryParser.parse(document) match {
case Success(queryAst) =>
complete(Executor.execute(SchemaDefinition.UserSchema, queryAst, repository)
.map(OK -> _)
.recover {
case error: QueryAnalysisError => BadRequest -> error.resolveError
case error: ErrorWithResolver => InternalServerError -> error.resolveError
})
case Failure(error) => complete(BadRequest -> Error(error.getMessage))
}
}
} ~ get {
complete(SchemaRenderer.renderSchema(SchemaDefinition.UserSchema))
}
}You may notice that we also expose our schema under GET endpoint as well, what it is here for? Well, if you are familiar with Swagger which we have talked about a lot here, it is a very similar concept. The schema contains all the necessary pieces, enough for external tools to automatically discover the respective GraphQL queries and mutations, along with the types they are referencing. GraphiQL, an in-browser IDE for exploring GraphQL, is one of those (think about Swagger UI in the REST(ful) services world).
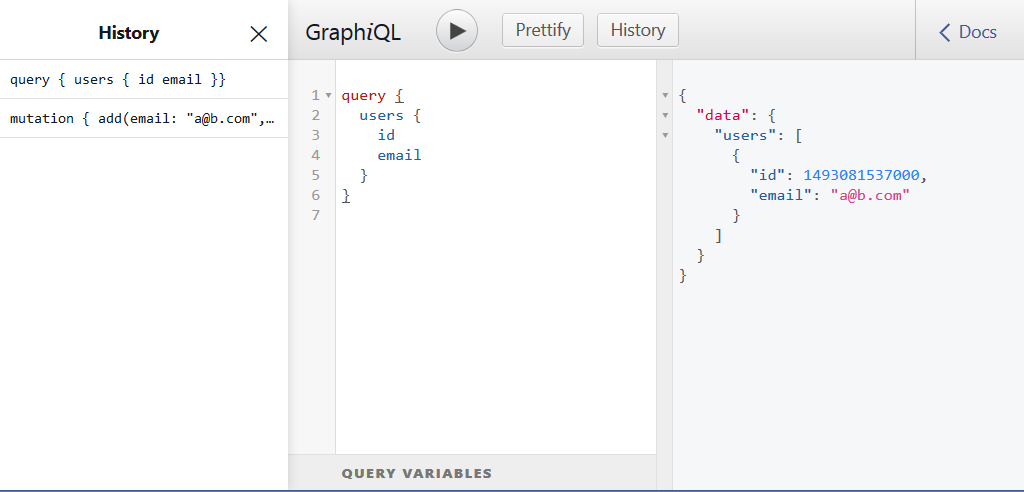
We are mostly there, our GraphQL server is ready, let us run it and send off a couple of queries and mutations, to get the feeling of it:
[info] Running com.example.graphql.Boot INFO akka.event.slf4j.Slf4jLogger - Slf4jLogger started INFO reactivemongo.api.MongoDriver - No mongo-async-driver configuration found INFO reactivemongo.api.MongoDriver - [Supervisor-1] Creating connection: Connection-2 INFO r.core.actors.MongoDBSystem - [Supervisor-1/Connection-2] Starting the MongoDBSystem akka://reactivemongo/user/Connection-2
Very likely our data store (we are using MongoDB run as Docker container) has no users at the moment so it sounds like a good idea to add one right away:
$ curl -vi -X POST http://localhost:48080/users -H "Content-Type: application/json" -d " \
mutation { \
add(email: \"a@b.com\", firstName: \"John\", lastName: \"Smith\", roles: [ADMIN]) { \
id \
active \
email \
firstName \
lastName \
address { \
street \
country \
} \
} \
}"
HTTP/1.1 200 OK
Server: akka-http/10.0.5
Date: Tue, 25 Apr 2017 01:01:25 GMT
Content-Type: application/json
Content-Length: 123
{
"data":{
"add":{
"email":"a@b.com",
"lastName":"Smith",
"firstName":"John",
"id":1493082085000,
"address":null,
"active":false
}
}
}It seems to work perfectly fine. The response details will be always wrapped into data envelop, no matter what kind of query or mutation you are running, for example:
$ curl -vi -X POST http://localhost:48080/users -H "Content-Type: application/json" -d " \
query { \
users { \
id \
email \
} \
}"
HTTP/1.1 200 OK
Server: akka-http/10.0.5
Date: Tue, 25 Apr 2017 01:09:21 GMT
Content-Type: application/json
Content-Length: 98
{
"data":{
"users":[
{
"id":1493082085000,
"email":"a@b.com"
}
]
}
}Exactly as we ordered… Honestly, working with GraphQL feels natural, specifically when data querying is involved. And we didn’t even talk about fragments, variables, directives, and a lot of other things.
Now it comes to the question: should we abandon all our practices, JAX-RS, Spring MVC, … and switch to GraphQL? I honestly believe that this is not the case, GraphQL is a good fit to address certain kind of problems, but by and large, traditional REST(ful) web services, combined with Swagger or any other established API specification framework, are here to stay.
And please be warned, along with the benefits, GraphQL comes at a price. For example, HTTP caching and cache control won’t apply anymore, HATEOAS does not make much sense either, unified responses no matter what you are calling, reliability as everything is behind single facade, … With that in mind, GraphQL is indeed a great tool, please use it wisely!
The complete project source is available on Github.
| Reference: | When following REST(ful) principles might look impractical, GraphQL could come on the resque from our JCG partner Andrey Redko at the Andriy Redko {devmind} blog. |
