Previously we set up a Scala application in order to execute a simple word count on hadoop.
What comes next is uploading our application to HDInsight.
So we shall proceed in creating a Hadoop cluster on HDInsight.
Then we will create the hadoop cluster.
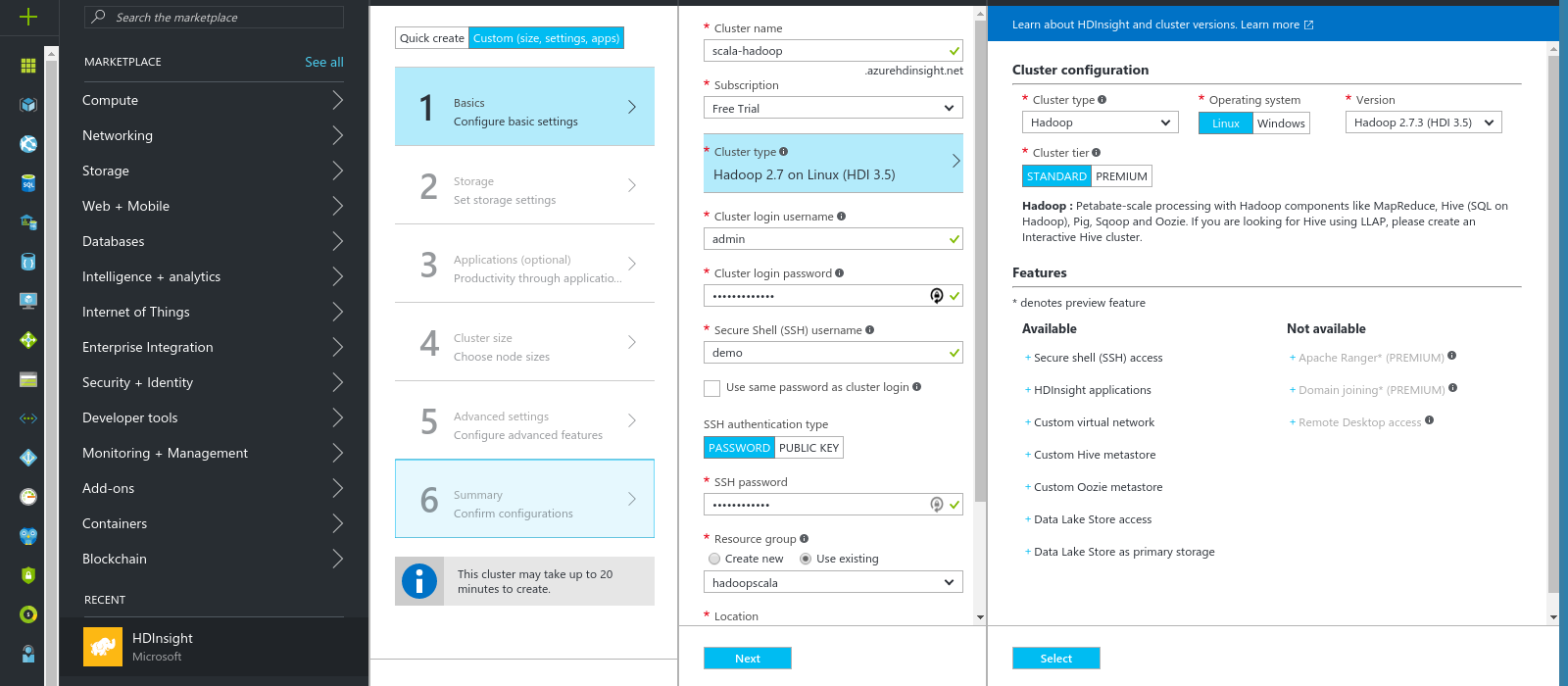
As you can see we specify the admin console credentials and the ssh user to login to the head node.
Our hadoop cluster will be backed by an azure storage account.
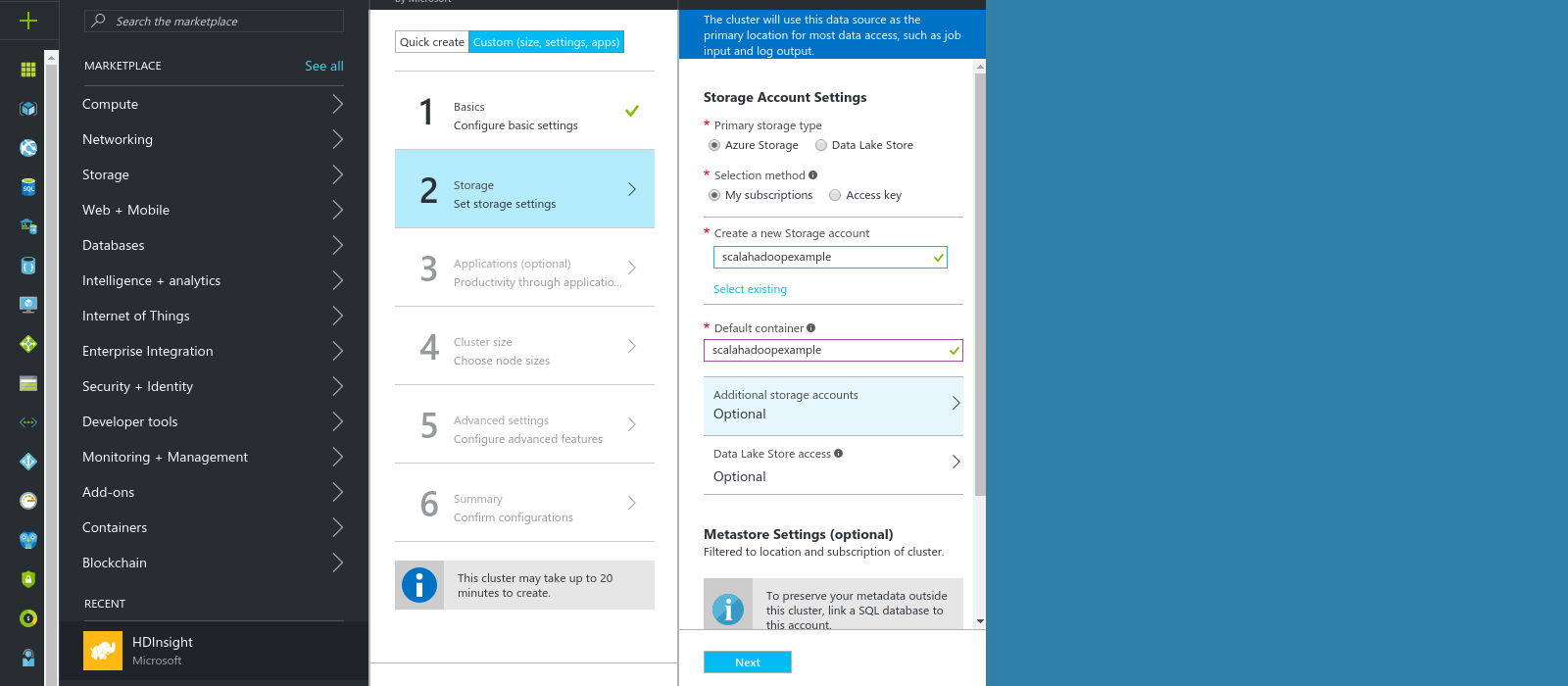
Then it is time to upload our text files to the azure storage account.
For more information on managing a storage account with azure cli check the official guide. Any text file will work.
azure storage blob upload mytext.txt scalahadoopexample example/data/input.txt
Now we can ssh to our Hadoop node.
First let’s run the examples that come packaged with the HInsight hadoop cluster.
hadoop jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapreduce-examples.jar wordcount /example/data/input.txt /example/data/results
Check the results
hdfs dfs -text /example/data/results/part-r-00000
And then we are ready to scp the scala code to our hadoop node and issue as wordcount.
hadoop jar ScalaHadoop-assembly-1.0.jar /example/data/input.txt /example/data/results2
And again check the results
hdfs dfs -text /example/data/results2/part-r-00000
That’s it! HDinsight makes it pretty straight forward!
| Reference: | Run Scala implemented Hadoop Jobs on HDInsight from our JCG partner Emmanouil Gkatziouras at the gkatzioura blog. |
