Perfecting Lambda Architecture with Oracle Data Integrator (and Kafka / MapR Streams)
“Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch– and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation. The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce.” – Wikipedia

Previously, I’ve wrote some blogs covering many use-cases for using Oracle Data Integrator (ODI) for batch processing on top of MapR distribution and for using Oracle GoldenGate (OGG) to stream transactional data into MapR Streams and other Hadoop components. While combining both products perfectly fit for the lambda architecture, the latest release of ODI (12.2.1.2.6) has many new great features, including the ability to deal with Kafka streams as source and target from ODI itself. This feature has tremendous advantages to anyone already having or planning to have a lambda architecture, by simplifying the way we process and handle both batch and fast data within the same logical design, under one product. Now if we combine OGG streaming capabilities and ODI batch/streaming capabilities, the possibilities are endless.
In this blog I’m going to show you how to configure MapR Streams (aka Kafka) on Oracle Data Integrator with Spark Streaming to create a true lambda architecture: a fast layer complementing the batch and serving layer.
I will skip the “hailing and praising” part for ODI in this post, but I only want to highlight one point: the mappings designed for this blog, just like every other mapping you would design, since the very first release of ODI, are going to run with native code on your Hadoop/Spark cluster, 100%, out of the box, with you coding zero line or worry about how and where.

I’ve done this on MapR so I can do a “two birds one stone”; showing you MapR Streams steps and Kafka. Since both aren’t so much different in concept, or API implementation, you can easily apply the same steps if you are using Kafka.
If you are unfamiliar with MapR Streams and/or Kafka concepts, I suggest that you spend some time reading about them. The following content assume that you know what MapR Streams and Kafka are (and of course, ODI). Otherwise, you’ll still get a great idea on the possible capabilities.
Preparations
MapR Streams (aka Kafka) Related Preparations
Obviously, we need to have MapR Streams paths and topics created. Unlike Kafka, MapR uses its own APIs via the “maprcli” command line utility to create and define topics. Hence, this step would be slightly different if you are using commodity Kafka. The web has plenty of examples on how to create and configure Kafka topics and server, so you aren’t alone.
For the sake of this demo, I’ve created one path and two topics under that path. We’ll let ODI consume from one of those topics (registrations) and produce to another (registrations2). That way, you’ll see how that works in action via ODI.
Creating a MapR Streams path called “users-stream” and a topic called “registrations”:

Creating the second topic, “registrations2”, on the same path I defined previously:
![]()
Hadoop Related Preparations
Not a lot of preparations here since I’m using a personal pre-configured VM with MapR installed and running. However, some steps were needed to get ODI mappings complete successfully. If you interested to know how I got ODI to work on MapR distribution, you may want to refer to this blog post.
- Spark: I’ve tested this on Spark 1.6.1, and you should too. At least not go to any lower version. Moreover, you need to have a specific label release for Spark build. I started my tests with label 1605 (this is a MapR release convention), and my jobs failed. Digging into the reason, I found that the PySpark libraries are NOT up-to-date with MapR Streams APIs. They could work with commodity Kafka, but not MapR’s. Here is a link to the RPM I’ve used.
- Spark Logging: Under spark path, there is a “config” folder which contains different configuration files. We’re interested here in only one to modify, if needed. The file name is “log4j.properties”. You need to make sure that the “rootCategory” parameter is set to INFO, otherwise you’ll get an exception when you run any of ODI mappings that are submitted to Spark:

- Hadoop Credential Store: ODI will refer to Hadoop credential store when certain password is needed in any of the jobs submitted. That way, we don’t include any clear passwords in parameter/property files, or in the code itself. In this demo, we’ll be using MySQL at some point, so I needed to create a store and add an alias for MySQL password. First you need to make sure that there is an entry in core-site.xml for the credential store, then actually create an alias for the password value:

The previous image is a snippet of my “site-core.xml” showing you the credential store I added. The next step would be to verify that the store is there, and then create an alias for the password value:

You won’t need to restart any of hadoop components after those changes, even after editing core-site.xml.
Note: If you hit “os process exception”, such as 137, make sure you’ve got enough free memory available.
ODI Related Preparations
The usual preparations that you would do in ODI. I’ll show the relevant ones to this blog.
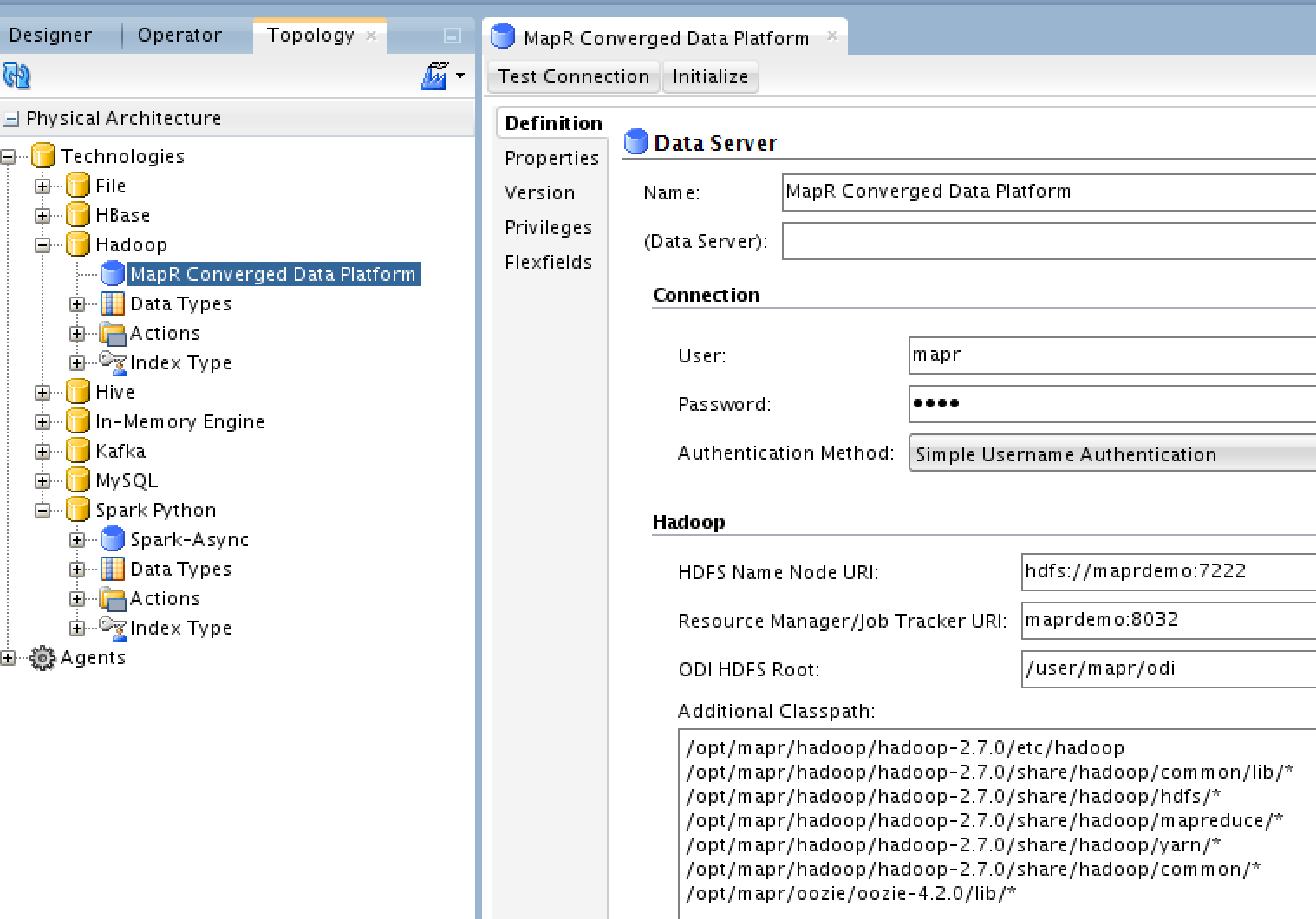
Hadoop Data Server
The following configuration is specific to MapR’s. If you are using some other distribution, you need to enter the relevant port numbers, and paths:
Spark-Python Data Server
With this release of ODI, 12.2.1.2.6, you need to create multiple Spark data servers if you want to use Spark Streaming and general Spark server/cluster. In this demo, I’ve created only Spark Streaming server, and called it Spark-Async.
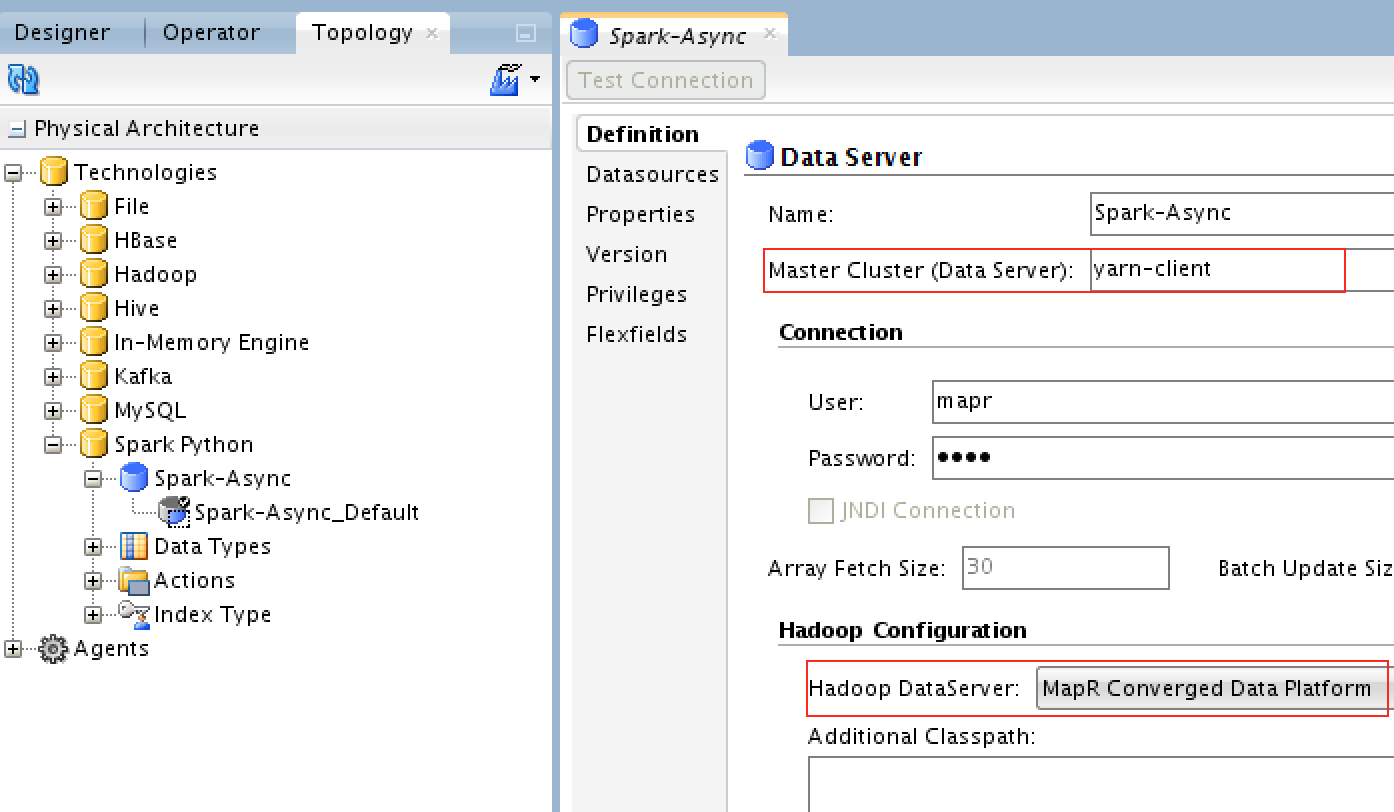
You would need to change the “Master Cluster” value to what you actually have and use: yarn-client or yarn-cluster, and select the Hadoop DataServer which we created previously.
Now the interesting part of the configuration here is the properties for the Spark-Async data server:

I’ve highlighted the most important ones that you need to pay attention to. ASYNC is used because we are going to use Spark Streaming. The rest of the properties are performance related.
Kafka Data Server
Here we’ll define the MapR Streams data server:
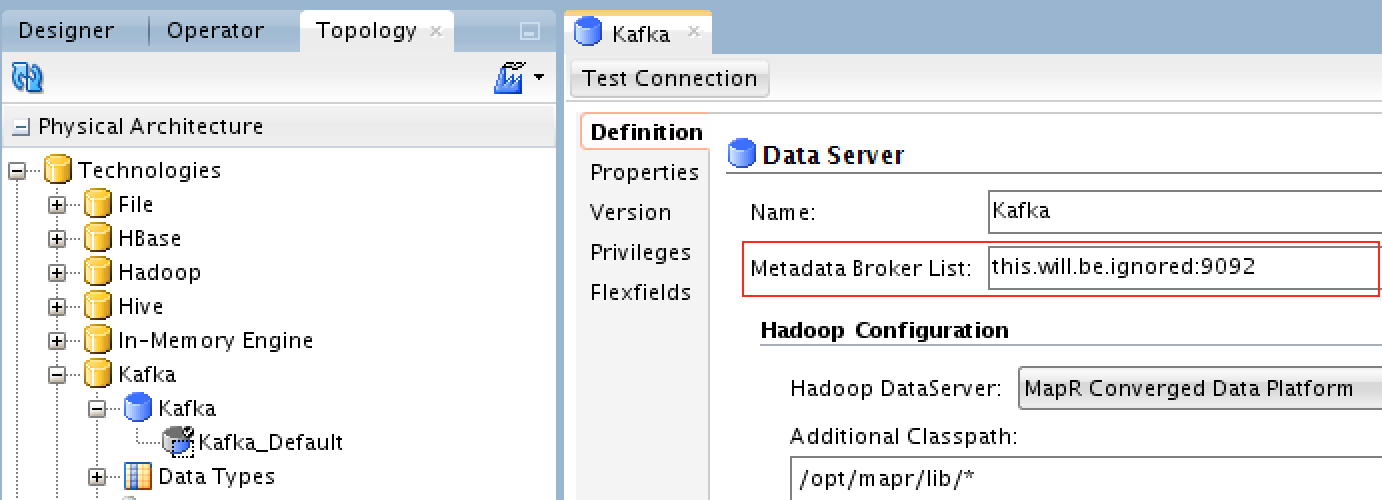
The metadata broker has a “dummy” address to comply with the Kafka API only. MapR Streams client will do the needed for you to connect to MapR Streams. You may NOT test the data server here, because there is no such Kafka Server running on MapR. So safely, ignore the test connection here because it’ll fail (and that’s OK).
For properties, you need to define the following:
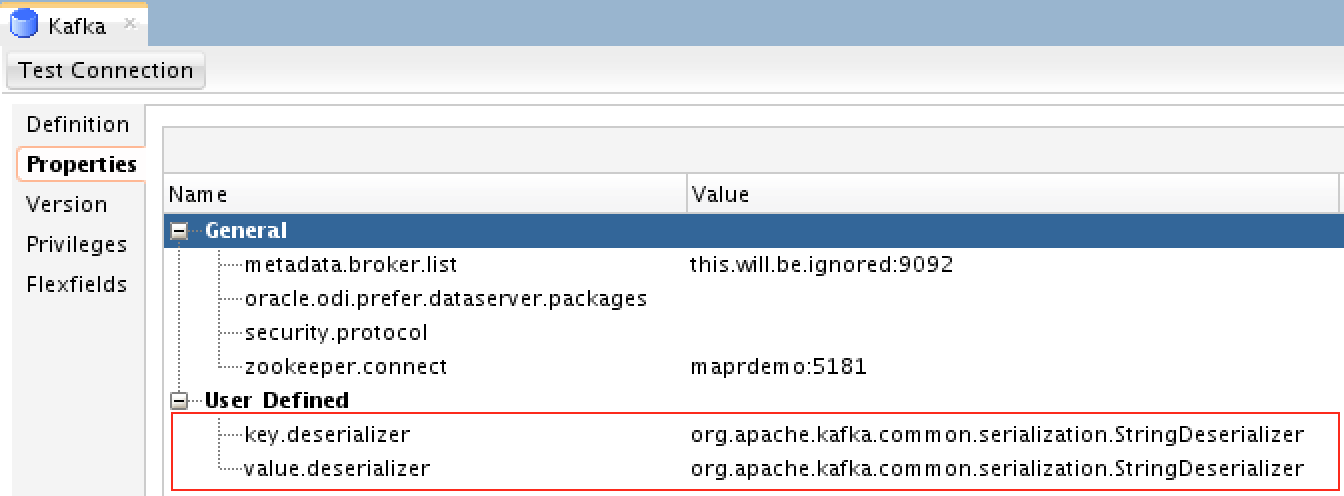
You need to manually define the “key.deserializer” and “value.deserializer”. Both are needed by MapR Streams and jobs would fail if they are not defined.
ODI Mappings Design
I’ve done my tests here to cover five use-cases. However, I’ll cover only one fully, and highlight the others to save you from reading redundant and common-sense steps.
1) MapR Streams (Kafka) => Spark Streaming => MapR Streams (Kafka):
In this mapping, we’ll read streaming data from one of the topics we created earlier, apply some function (simple one) and then produce results to another topic. Here is the logical design of the mapping:

The MapR_Streams_Registrations1 model is something I defined by duplicating one of the models I have reverse-engineered for MySQL (structure is the same), but of course the technology selected would be Kafka in this case. You’ll be able to select what is format of the streaming data: Avro, JSON, Parquet or Delimited:
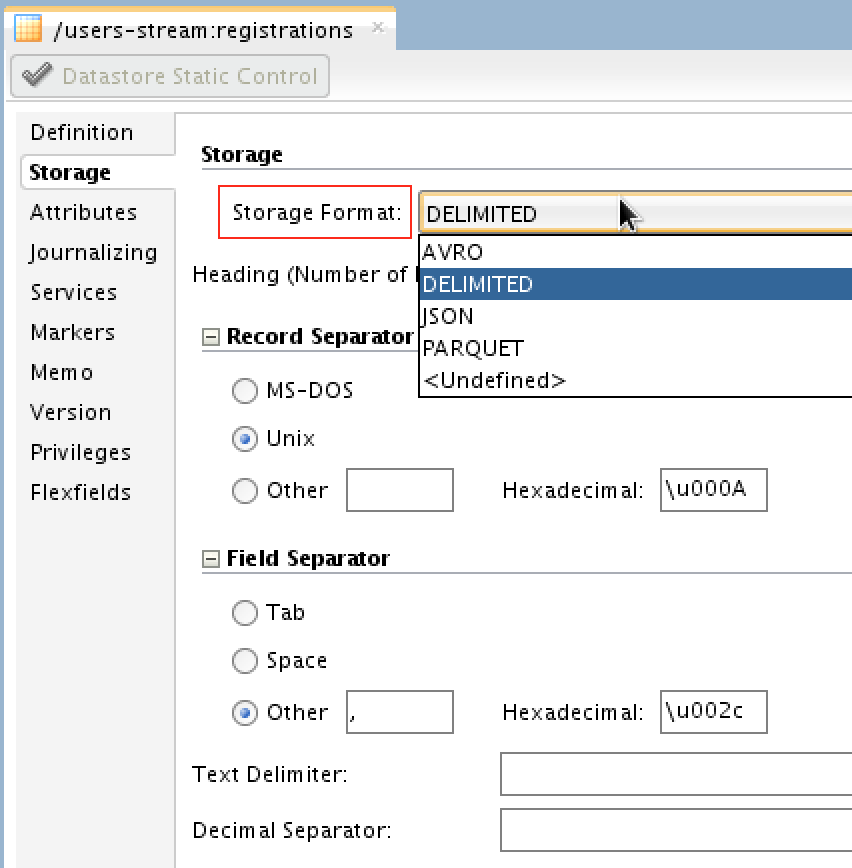
And here is how the physical design looks like:
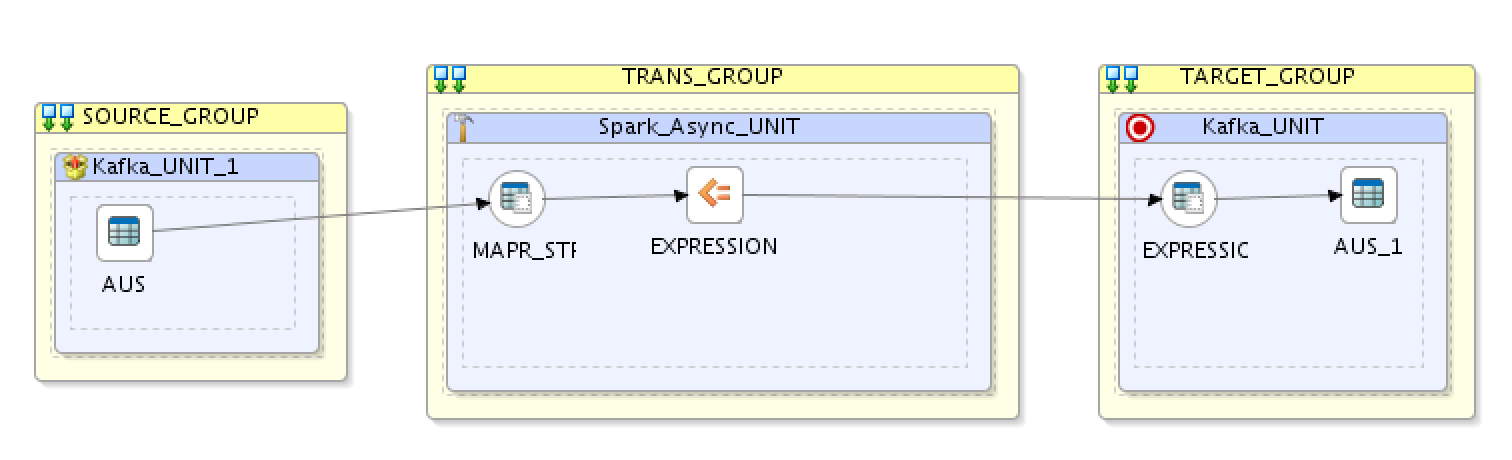
- SOURCE_GROUP: This is our MapR Streams topic “registrations”
- TRANS_GROUP: This is our Spark Async Server
- TARGET_GROUP: This is our MapR Streams topic “registrations2”
The properties for the physical implementation are:

You NEED to select the staging location as Spark Async AND enable “Streaming”.
To load streaming data from our topic, registrations, to Spark Streaming, we need to select the proper LKM, which is LKM Kafka to Spark:
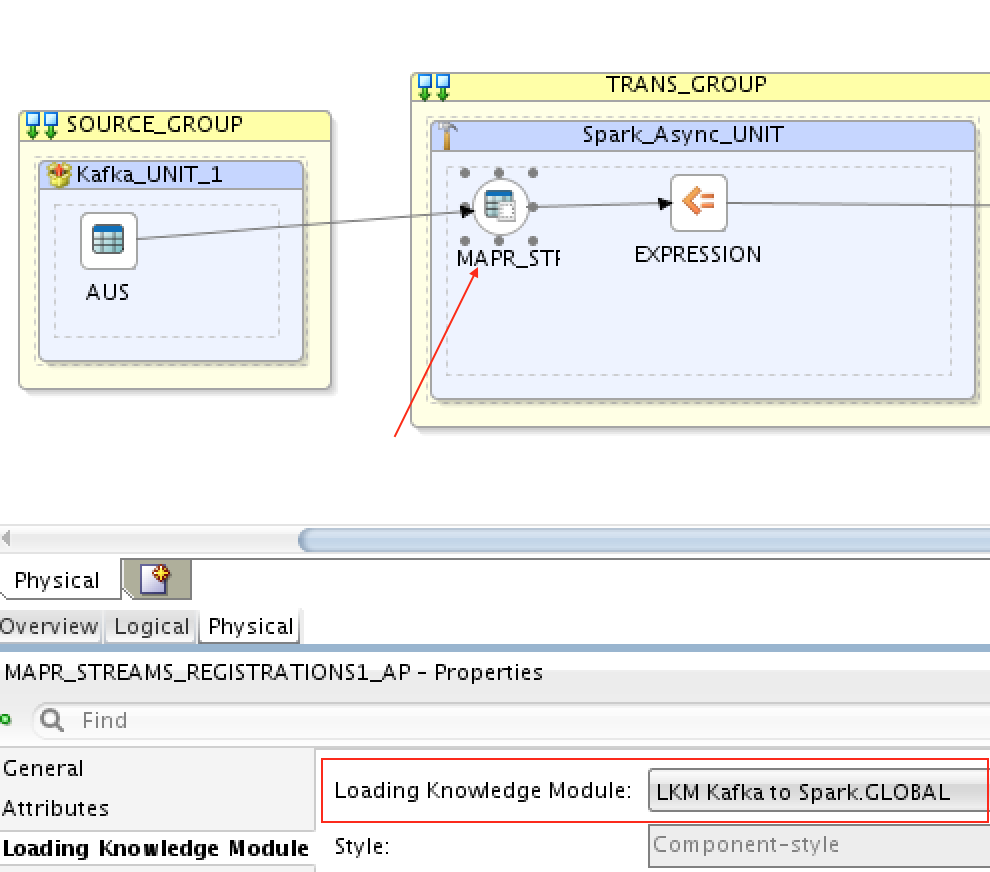
And then to load from Spark Streaming to MapR Stream target topic, registrations2, we need to select LKM Spark to Kafka:

2) MapR-FS (HDFS) => Spark Streaming => MapR Streams (Kafka):
I won’t show you much here except for the knowledge modules used. To load from MapR-FS (HDFS) to Spark Streaming, I’ve used LKM File to Spark:
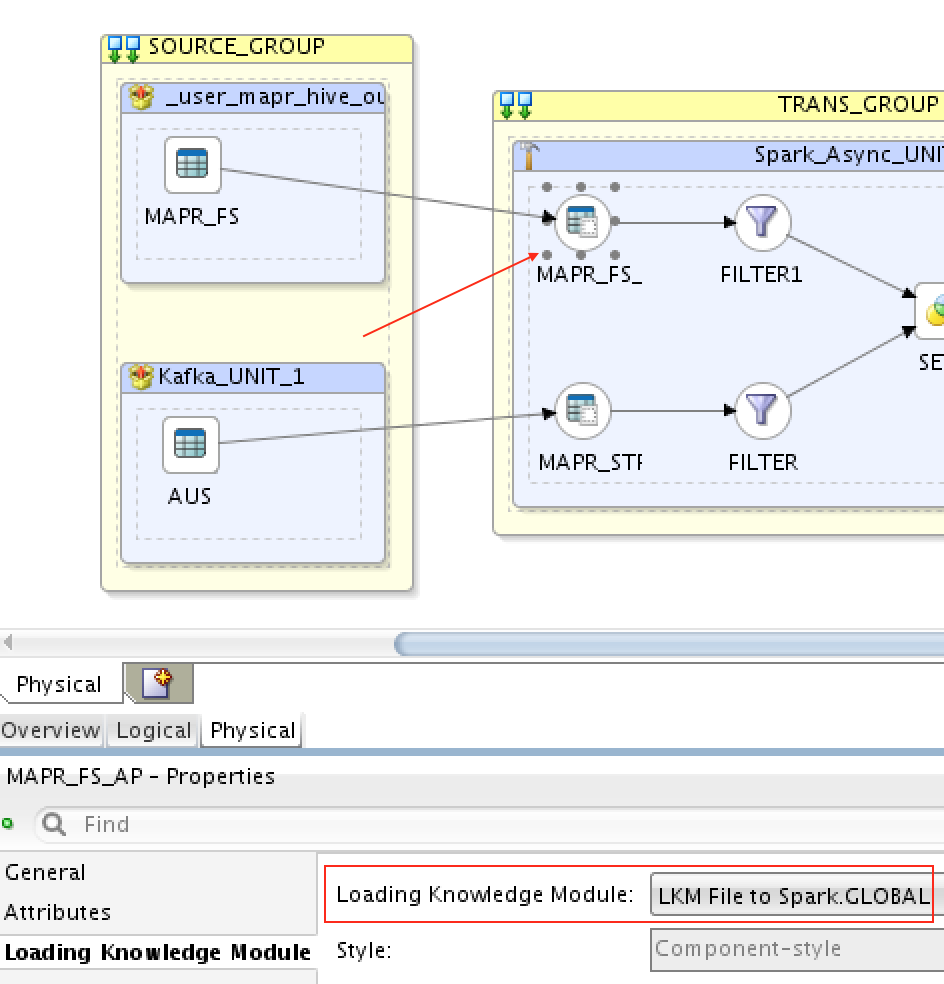
And to load from Spark Streaming to MapR Streams, I’ve used LKM Spark to Kafka like I did in previous mapping.
Note: The LKM File to Spark will act as a stream, a file stream (obviously). ODI will only pick up any updated/new files, NOT static ones.
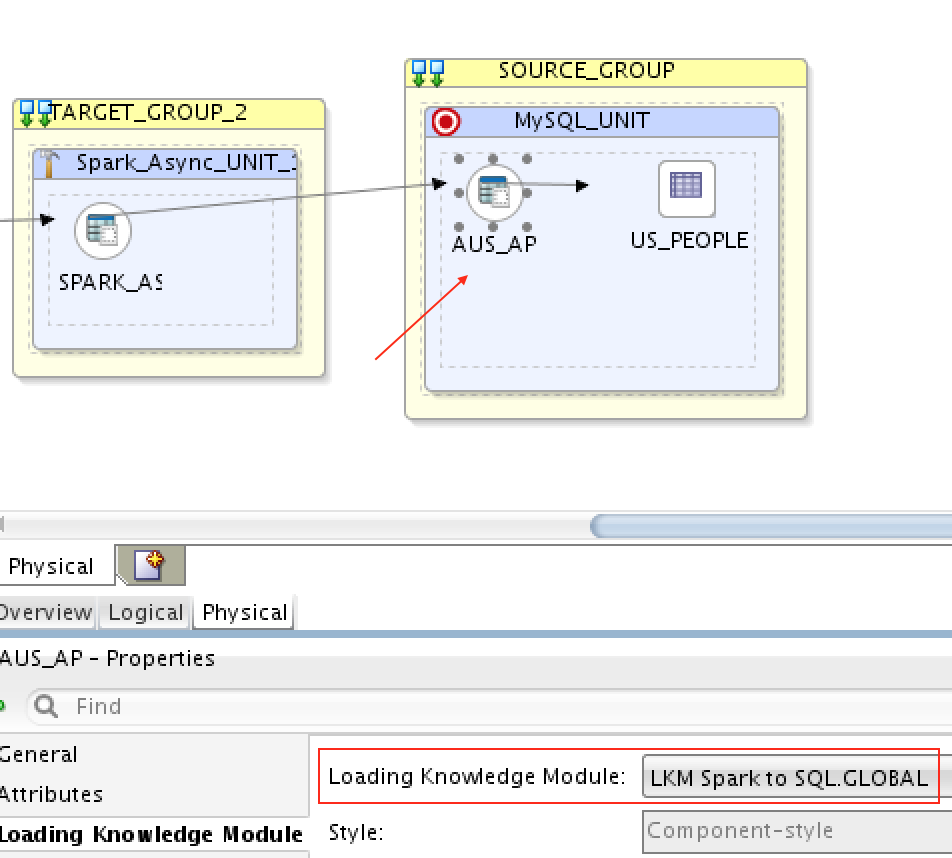
3) MapR Streams (Kafka) => Spark Streaming => MySQL:
To load from MapR Streams (Kafka) to Spark Streaming, I’ve used LKM Kafka to Spark like I did in the first mapping. And then to load from Spark Streaming to MySQL, I’ve used LKM Spark to SQL:
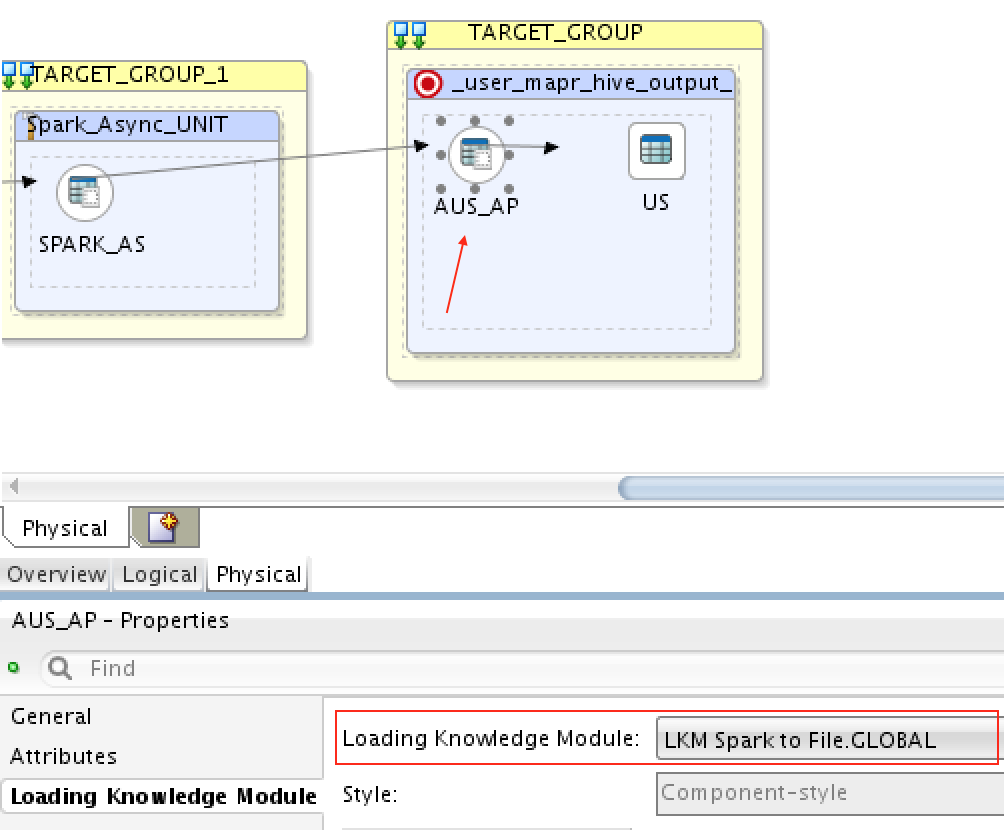
4) MapR Streams (Kafka) => Spark Streaming => MapR-FS (HDFS)
To load from MapR Streams to Spark Streaming, I’ve used LKM Kafka to Spark like we did before, and then to load from Spark Stream to MapR-FS (HDFS), I’ve used LKM Spark to File:
5) MapR Streams (Kafka) & Oracle DB => Spark Streaming => MySQL
This is another interesting use case, where you can actually join Kafka stream with SQL source on the spot. This ONLY (currently) works for the lookup component:
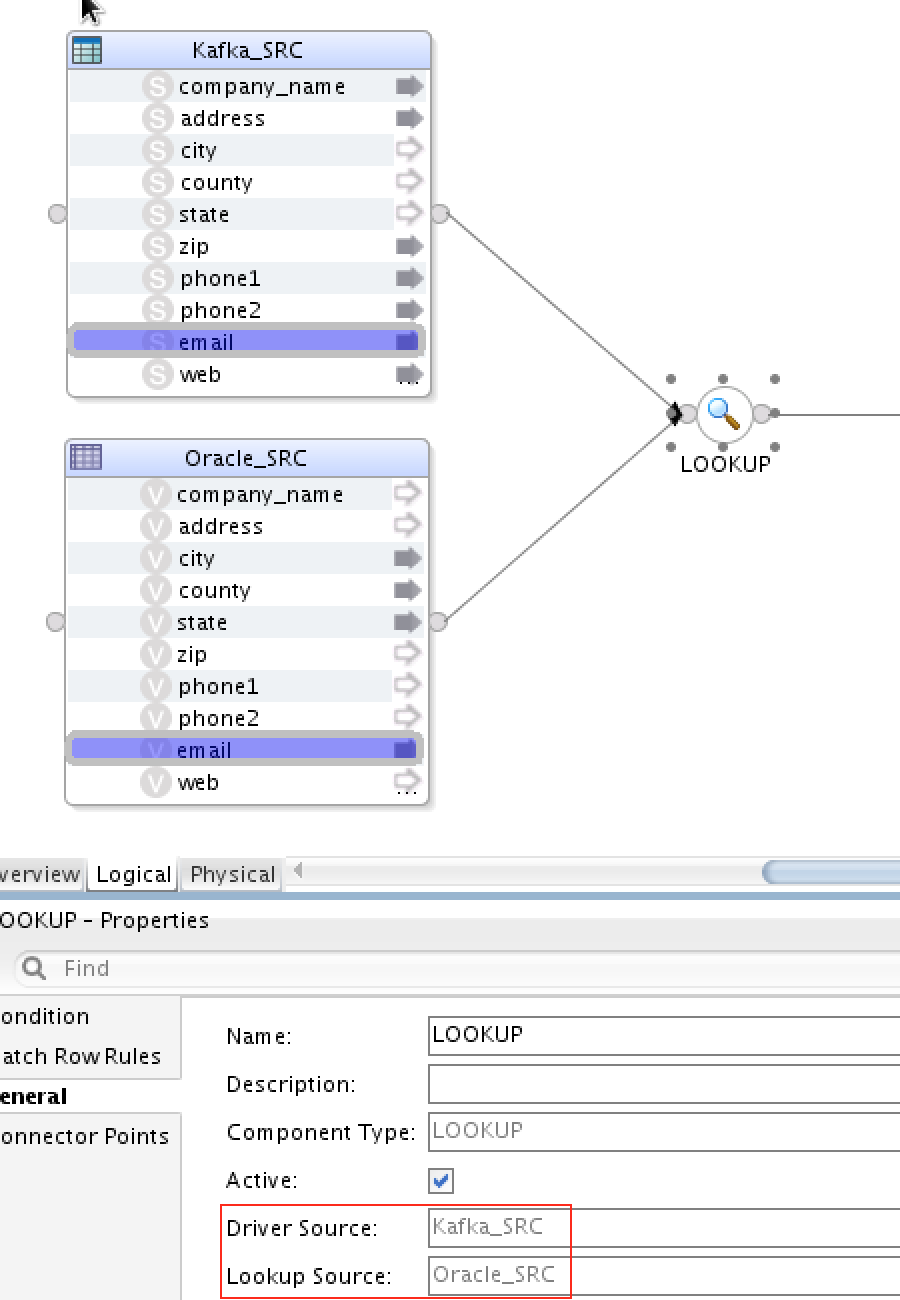
Notice that the Driver Source has to be Kafka (or MapR Streams in our case), and the Lookup Source has to be a SQL database. I’ve used pretty much the same LKMs as previous mappings: LKM SQL to Spark, LKM Kafka to Spark and LKM Spark to SQL.
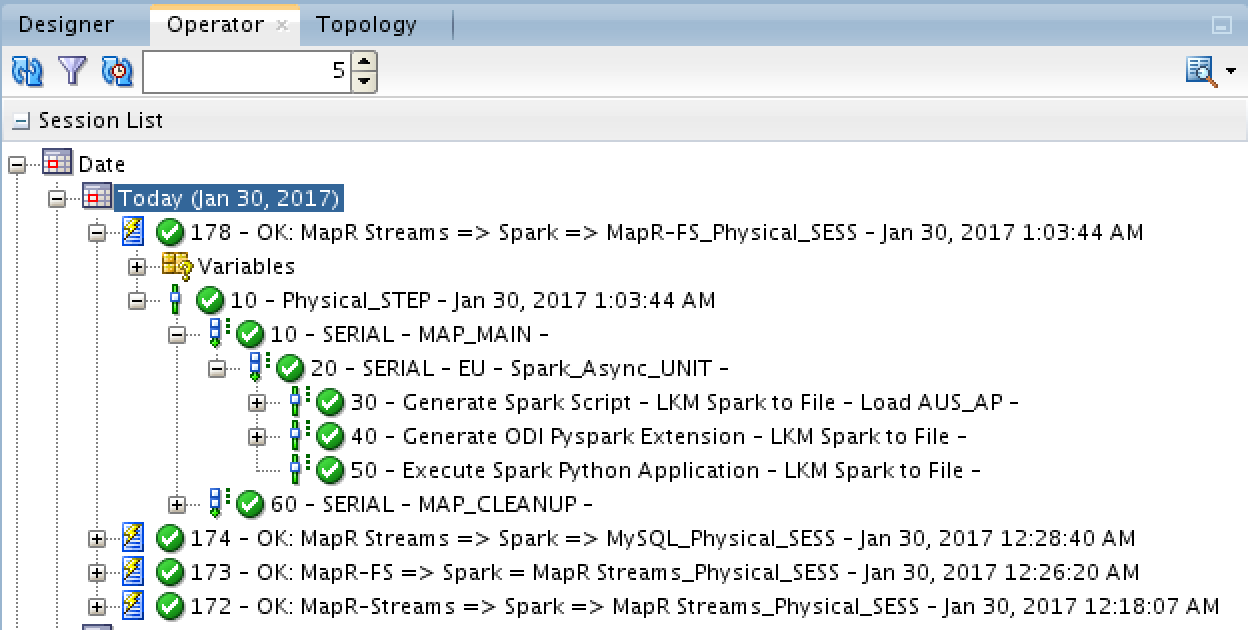
The Execution
I’ll show you the execution steps for the first use-case only, which is MapR Streams (Kafka) => Spark Streaming => MapR Streams (Kafka). To simulate the case, I’ve created a Kafka producer console and another Kafka consumer console so I can monitor the results. Looking at the producer below, I’ve pasted some records:
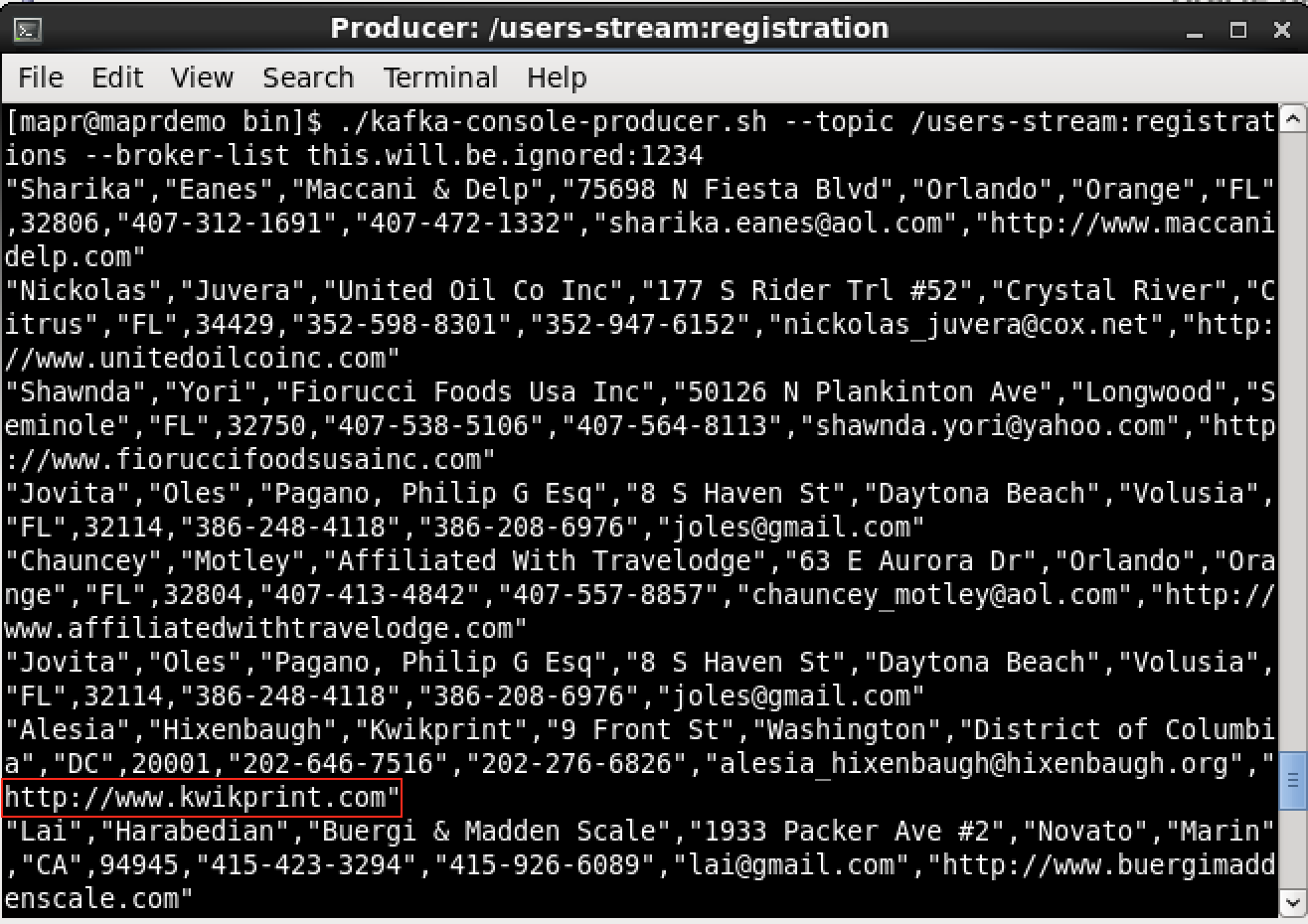
I’ve highlighted one of the URLs just to make sure you notice that it’s in lower case. Waiting a few seconds, Spark will process those messages and send them to the target MapR Streams topic:

Notice that all the URLs have been uppercased. Success!
Going through the mappings, the results were as expected. I’m not going to show the testing steps for them since they are just as simple. The idea here is to show you how to configure ODI with MapR Streams (Kafka).
Last Words
It worth mentioning that while any of the mappings are being executed, you’ll be able to drill into the logs and see what’s happening (the code generated, etc…). Moreover, you’ll get a link to the job history URL to access it on Spark UI:
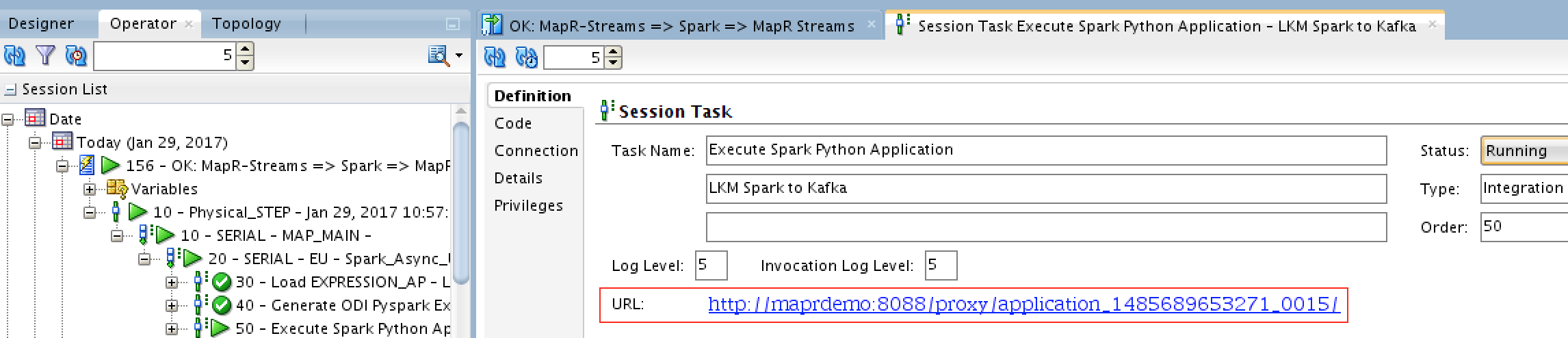
Opening the link will take us to Spark UI:

If you want to control how long your streaming job will survive, you need to increase the “spark.streaming.timeout” property of the Spark-Async data server OR override it from mapping configuration itself. You may also want to create an ODI package that has a loop and other useful components to serve your business needs.
Conclusion
ODI can handle both layers in the lambda architecture: batch and fast layers. This is not only a great feature which ODI added to its very long list of comprehensive capabilities, but also one that would increase productivity and efficiency in designing data pipelines from one unified, easy to use, interface. It was also clear that ODI can easily work with MapR Streams just like it would with commodity Kafka, thanks to MapR for having their binaries compatible with Kafka APIs, and ODI for not being one framework dependant. This assures you that ODI is truly open and modular E-LT tool unlike others.
Some other relevant posts:
- Oracle Data Integrator & MapR Converged Data Platform: CHECK!
- Streaming Transactional Data into MapR Streams using Oracle GoldenGate
- MapR-FS Real-Time Transactional Data Ingestion using Oracle GoldenGate
- Reverse Engineer MapR-DB with ODI
Disclaimer
The thoughts, practices and opinions expressed here are those of the author alone and do not necessarily reflect the views of Oracle.
| Reference: | Perfecting Lambda Architecture with Oracle Data Integrator (and Kafka / MapR Streams) from our JCG partner Issam Hijazi at the Mapr blog. |

hi, can do this only using kafka. Because using hadoop and spark makes it more complex