Parallel Database Streams
In my previous post, I wrote about processing database content in parallel using parallel streams and Speedment. Parallel streams can, under many circumstances, be significantly faster than the usual sequential database streams.

Speedment is an open-source Stream ORM Java Toolkit and Runtime Java tool that wraps an existing database and its tables into Java 8 streams. We can use an existing database and run the Speedment tool and it will generate POJO classes that corresponds to the tables we have selected using the tool. One distinct feature with Speedment is that it supports parallel database streams and that it can use different parallel strategies to further optimize performance.By default, parallel streams are executed on the common ForkJoinPool where they potentially might compete with other tasks. In this post we will learn how we can execute parallell database streams on our own custom
ForkJoinPool, allowing a much better control of our execution environment.
Getting Started With Speedment
Head out to open-souce Speedment on GitHub and learn how to get started with a Speedment project. Connecting the tool to an existing database is really easy. Read my
previous post for more information on how the database table and PrimeUtil class looks like for the examples below.
Executing on the Default ForkJoinPool
Here is the application that I talked about in my previous post that will scan a database table in parallel for undetermined prime number candidates and then it will determine if they are primes or not and update the table accordingly. This is how it looks:
Manager<PrimeCandidate> candidatesHigh = app.configure(PrimeCandidateManager.class)
.withParallelStrategy(ParallelStrategy.computeIntensityHigh())
.build();
candidatesHigh.stream()
.parallel() // Use a parallel stream
.filter(PrimeCandidate.PRIME.isNull()) // Only consider nondetermined prime candidates
.map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) // Sets if it is a prime or not
.forEach(candidatesHigh.updater()); // Apply the Manager's updaterFirst, we create a stream over all candidates (using a parallel strategy named ParallelStrategy.computeIntensityHigh()) where the ‘prime’ column is null using the stream().filter(PrimeCandidate.PRIME.isNull()) method. Then, for each such prime candidate pc, we either set the ‘prime’ column to true if pc.getValue() is a prime or false if pc.getValue() is not a prime. Interestingly, the pc.setPrime() method returns the entity pc itself, allowing us to easily tag on multiple stream operations. On the last line, we update the database with the result of our check by applying the candidatesHigh.updater() function.
Again, make sure to check out my previous post on the details and benefits of parallel strategies. In short, Java’s default parallel strategy works well for low computational demands because it places a large amount of initial work items on each thread. Speedment’s parallel strategies works much better for medium to high computational demands whereby a small amount of work items are laid out on the participating threads.
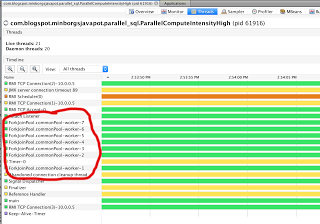
The stream will determine prime numbers fully parallel and the execution threads will use the common ForkJoinPool as can be seen in this picture (my laptop has 4 CPU cores and 8 CPU threads):
Use a Custom Executor Service
As we learned in the beginning of this post, parallel streams are executed by the common
ForkJoinPool by default. But, sometimes we want to use our own Executor, perhaps because we are afraid of flooding the common
ForkJoinPool, so that other tasks cannot run properly. Defining our own executor can easily be done for Speedment (and other stream libraries) like this:
final ForkJoinPool forkJoinPool = new ForkJoinPool(3);
forkJoinPool.submit(() ->
candidatesHigh.stream()
.parallel()
.filter(PrimeCandidate.PRIME.isNull())
.map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue())))
.forEach(candidatesHigh.updater());
);
try {
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
} catch (InterruptedException ie) {
ie.printStackTrace();
}The application code is unmodified, but wrapped into a custom ForkJoinPool that we can control ourselves. In the example above, we setup a thread pool with just three worker threads. The worker threads are not shared with the threads in the common ForkJoinPool.
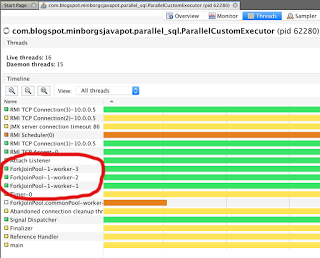
Here is how the threads looks like using the custom executor service:
This way we can control both the actual ThreadPool itself and precisely how work items are laid out in that pool using a parallel strategy!
Keep up the heat in your pools!
| Reference: | Work with Parallel Database Streams using Custom Thread Pools from our JCG partner Per Minborg at the Minborg’s Java Pot blog. |
