What is CockroachDB?
CockroachDB is a project I’ve been keeping an eye on for a while now with great interest. It’s a an open-source, Apache 2 licensed, database (Github link) that heavily draws inspiration from the Google Spanner whitepaper. At it’s core its a key-value store that scales horizontally. What makes it really interesting for us though, is that 1) it supports SQL by using the Postgres wire protocol and 2) has full ACID semantics and distributed transactions. If you’re interested in how they achieve this, make sure to read the technical posts at the CockroachLabs blog (I admit, sometimes it’s not for the faint-of-heart ;-)). Do note that it is still a distributed system and thus follows the CAP theorem, more specifically it is a CP system.

It’s still early days, as you’ll read in their FAQ, as many things are not optimized yet. However, now that they recently added basic support for joins, I figured I should give it a spin with the Flowable engine. In this post I’ll show how easy it is to run the Flowable v6 process engine on CockroachDB.
(Sidenote: I love the name! For people that don’t understand it: cockroaches are one of the few creatures on earth that can survive something like a nuclear blast. Quite a resilient little animal … something you’d like for your data too �� )
Setup
The getting started docs on the CockroachDb website are quite clear, but for clarity here are the steps I followed:
- Download latest CockroachDB tarball (or whatever your system needs)
- Untar and start first node:
- ./cockroachdb start
- Start a second node:
- ./cockroach start –store=node2 –port=26258 –http-port=8081 –join=localhost:26257
- Start a third node:
- ./cockroach start –store=node3 –port=26259 –http-port=8082 –join=localhost:26257
Hurray, you’ve now got a cluster of three nodes running, which will happily replicate data among each other. There is a nice admin app which is running on 8080 and gives an overview of the cluster:
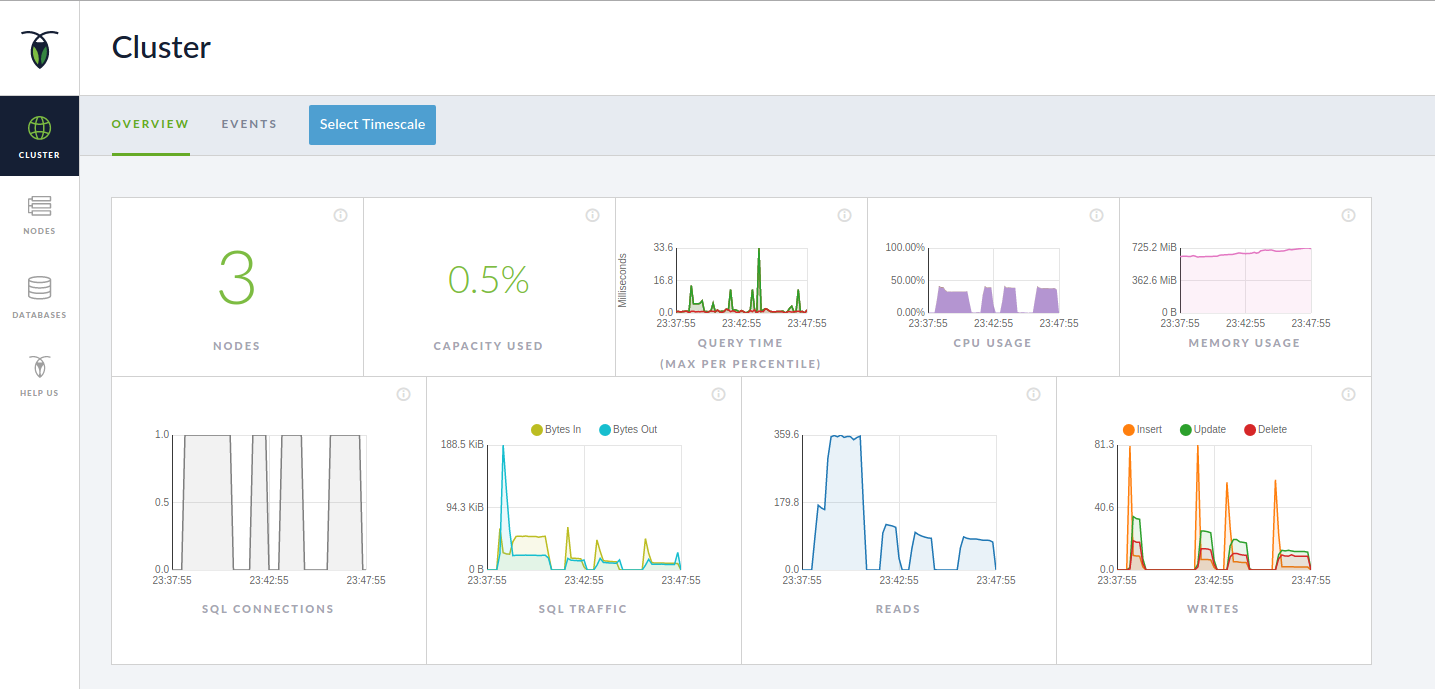
Next step: we need a database for the Flowable engine. Creating the database and granting permissions to the default user (maxroach) is done via the CockroachDB SQL shell:
./cockroachdb sql > CREATE DATABASE flowable; > GRANT ALL ON DATABASE flowable TO maxroach;
Sadly, CockroachDB hasn’t implemented the JDBC metadata feature yet, which we use in the Flowable engine for automatically creating the database schema. Also, I couldn’t quite get foreign keys to work properly in a few cases, so I copy/pasted the Flowable SQL scripts and removed those. The file is uploaded on Github.
Also, this means that currently you need to create the database schema “manually”. If you’re using a bash terminal, you can download the script above from github and feed it to the CockroachDB SQL shell as follows. Alternatively, you can paste it into the SQL shell.
sql=$(wget https://raw.githubusercontent.com/jbarrez/flowable-cockroachdb-demo/master/engine-schema.sql -q -O -) ./cockroach sql –database=flowable –user=maxroach -e “$sql”
Flowable on CockroachDB
The database is now ready. Time to boot up a Flowable engine using this database as data store. All source code is available on Github: https://github.com/jbarrez/flowable-cockroachdb-demo
![]()
As CockroachDB uses the Postgres wire protocol, we simply need to add the Postgres JDBC driver to the pom.xml:
<dependency> <groupId>org.flowable</groupId> <artifactId>flowable-engine</artifactId> <version>6.0.0.RC1-SNAPSHOT</version> </dependency> <dependency> <groupId>org.postgresql</groupId> <artifactId>postgresql</artifactId> <version>9.4.1211.jre7</version> </dependency>
I’m using the current v6 master branch here, which isn’t released yet. You can build it yourself easily though by cloning the flowable-engine project and doing a ‘mvn clean install -DskipTests’ in the root. The configuration file used for the engine is quite simple, and it looks exactly like connecting to a regular Postgres relational database. Do note I’m “cheating” a bit with the databaseSchemaUpdate settings to avoid the auto-schema check.
<property name="jdbcUrl" value="jdbc:postgresql://127.0.0.1:26257/flowable?sslmode=disable" /> <property name="jdbcDriver" value="org.postgresql.Driver" /> <property name="jdbcUsername" value="maxroach" /> <property name="jdbcPassword" value="" /> <property name="databaseSchemaUpdate" value="cockroachDb" />
The process definition we’ll use is a simple demo process that exercises a few things like user tasks, service tasks, subprocesses, timers, etc:
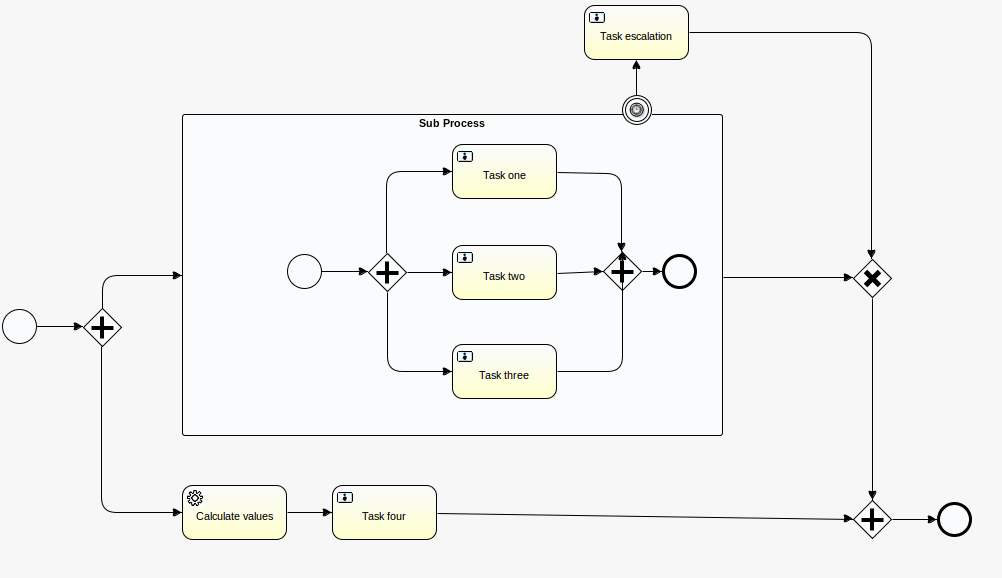
The following snippet shows how the Flowable API is used in a few different ways. If you follow on the CockroachDB admin UI, you’ll see that traffic goes up for a while. What happens here is:
- Lines 3-9: booting up the Flowable process engine using the config file from above and getting all the services
- Line 11: Deploying the process definition
- Lines 15-19: Starting 100 process instances
- Lines 24-33: Finishing all tasks in the system
- Line 35: Doing a historical query
So, as you can see, nothing fancy, simply touching various API’s and validating it all works on CockroachDB.
public static void main(String[] args) {
ProcessEngine processEngine = ProcessEngineConfiguration
.createProcessEngineConfigurationFromResource("flowable.cfg.xml").buildProcessEngine();
RepositoryService repositoryService = processEngine.getRepositoryService();
RuntimeService runtimeService = processEngine.getRuntimeService();
TaskService taskService = processEngine.getTaskService();
HistoryService historyService = processEngine.getHistoryService();
repositoryService.createDeployment().addClasspathResource("demo-process.bpmn").deploy();
System.out.println("Process definitions deployed = " + repositoryService.createProcessDefinitionQuery().count());
Random random = new Random();
for (int i=0; i<100; i++) {
Map<String, Object> vars = new HashMap<>();
vars.put("var", random.nextInt(100));
runtimeService.startProcessInstanceByKey("myProcess", vars);
}
System.out.println("Process instances running = " + runtimeService.createProcessInstanceQuery().count());
LinkedList<Task> tasks = new LinkedList<>(taskService.createTaskQuery().list());
while (!tasks.isEmpty()) {
Task task = taskService.createTaskQuery().taskId(tasks.pop().getId()).singleResult();
if (task != null) {
taskService.complete(task.getId());
}
if (tasks.isEmpty()) {
tasks.addAll(taskService.createTaskQuery().list());
}
}
System.out.println("Finished all tasks. Finished process instances = "
+ historyService.createHistoricProcessInstanceQuery().finished().count());
processEngine.close();
}The output is exactly as you’d expect (and exactly the same as running it on a relational database).
Process definitions deployed = 1 Process instances running = 100 Completed 10 tasks Completed 20 tasks … Completed 400 tasks Finished all tasks. Finished process instances = 100
Conclusion
It’s almost trivial to run the Flowable process engine on CockroachDB, most specifically by the excellent SQL layer and relational support the developers of CockroachDB have added. There’s still a way to go (as you’ll read on their blog), but it’s certainly a cool piece of technology already right now! And who doesn’t like horizontal scalability without sacrificing ACID transactions? It’s a perfect fit for the use cases of a process engine.
I’m going to continue to keep a close eye on the CockroachDB project, as the combination with Flowable shows a lot of potential. And, as you know me, I’m also really looking forward, once they start focusing on performance, to run some benchmarks :-).
| Reference: | Running Flowable on CockroachDB from our JCG partner Joram Barrez at the Small steps with big feet blog. |

Good article.
When defining the connection, you specifically provide Node 1. What if this one fails?
Is the application supposed to fail over or can that be transparent?
Thanks
Jens
(j-lawyer.org)