We are proud to announce the general availability of the new release of the CUBA Platform and Studio!
Perhaps this is one of the most feature-rich platform releases ever – there are important changes on all levels: architecture, extensibility, API usability, and performance.
This article covers major enhancements of the platform. The full list of changes is available in release notes:
Platform 6.3 Release Notes
Studio 6.3 Release Notes
Application Components
As you know, the platform always had a mechanism of functional decomposition: on one hand, the platform itself is split to the core and add-ons, on the other hand, there was an ability to create extension projects. The mechanism of extensions was limited in that it could work only vertically – you could create a number of extensions for one base project, but you couldn’t create an add-on similar to CUBA Reporting or BPM to be combined with other add-ons in a final application and reused in other projects.
Now the problem is solved by introducing the concept of Application Components. With application components, you can decompose a large application to a set of functional modules and develop them as separate projects. Moreover, these modules can be reusable – you can include them to different applications just like you do with CUBA premium add-ons.
For example, in a Taxi management application, the structure of components can be as follows:
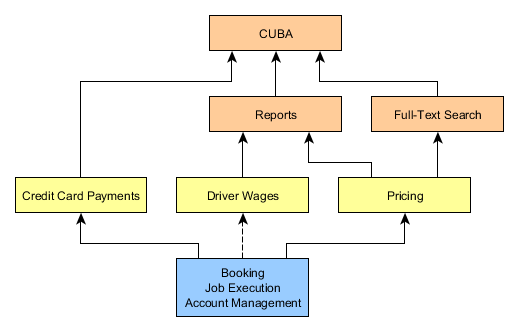
Here CUBA, Reports and Full-Text Search are the components provided by the platform; Credit Card Payments and Pricing are reusable components working in different applications; Driver Wages contains optional functionality delivered only to certain customers. This optional dependency means that you can include app components in an application not only in development but in the deployment stage too.
Actually, an application component (or app component) is just an application that exposes some information about itself. The information about modules, configuration properties, and artifacts of the component is contained in a special file: app-component.xml; special JAR manifest entries are used for automatic discovery of components located in the classpath. Application components can also be seen as full-stack libraries: they provide functionality on all levels, including entities, database DDL scripts, middleware services, UI screens and even CSS theming.
Studio enables automatic generation of app-component.xml for the current project, if you want to make it a component. Just use the link on the Project properties tab. In order to use a component in an application, edit Project properties and add the component to the Custom components list.
You can see an example of creating and using application components in the documentation.
Support for Multiple Data Stores
Until now, the platform mechanisms could work only with a single database selected for an application. You could use other sources of data directly through JDBC or other connections, but it was too complicated to display and edit such “external” data in standard UI components.
The concept of data stores implemented in CUBA 6.3 is designed to solve the problem of working with data from different sources in a single application using the same standard platform mechanisms such as data-aware visual components. A data store is actually an interface with a few methods for loading and saving entities. The platform currently contains one implementation of this interface allowing to work with relational databases through the ORM layer. You can create your own data store implementations in your projects, for example to work with NoSQL databases, in-memory grids, or for integration with other applications.
When you use multiple data stores in an application, its data model will contain entities mapped to data from different locations. If the data store is an RDBMS, the entities will be annotated as JPA persistent classes. Otherwise, the entities will be non-persistent and it will be the responsibility of your custom data store implementation to map the entities to data. An application will always have one “main” data store connected to an RDMS to store platform entities like Users, Roles, Filters, etc. The application entities can be scattered across any number of different stores.
For example, the diagram below represents a structure of data stores for an application that is integrated on the database level with an ERP system, uses MongoDB as a document storage and a REST API to connect to a remote information system. The parts which a native for CUBA a shown in green, the custom parts are in yellow.
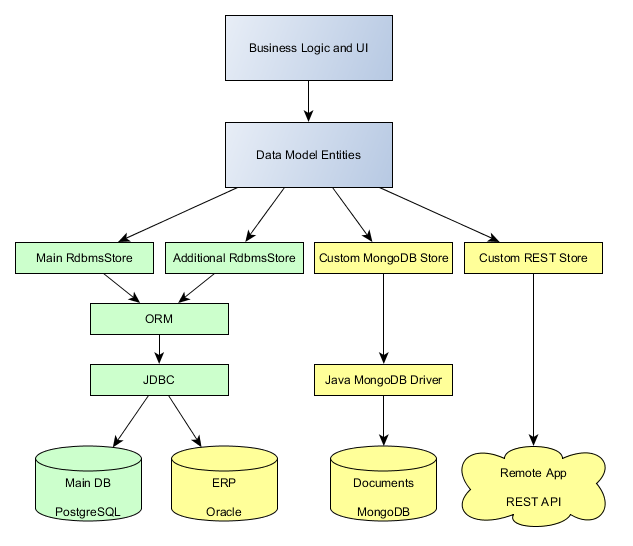
The mixed data model and custom data stores open the way for creating microservices (or, more specifically, Self-Contained Systems). Suppose you have a Sales application which includes a functionality for managing Customers and Products. You can divide the application into three separate projects: Sales, Customers and Products, each with their own database and UI. In the Sales app, you create two additional data stores for integration with other apps. In the simplest case, the data stores can be the built-in RdbmsStore, so the Sales app will just connect to the other databases. For more loose coupling, you can create custom data stores using REST API and map remote data to non-persistent entities of the Sales data model. As a result, you will have three relatively small self-contained applications: Customers and Products work on their own, Sales contains business logic and UI based on standard CUBA mechanisms but using data from remote systems.
Entities from different data stores now cannot have direct relations. It means that if you want to create a reference to an entity from different store, you have to create a persistent attribute for the ID of the “foreign” entity and a non-persistent attribute for the entity itself, and handle its loading and saving programmatically. In a future platform release, we are going to provide a simple declarative way of linking entities on the application level.
Using Studio, you can quickly configure additional data stores (RDBMS or custom) on the Advanced tab of the Project properties page.
See the documentation for the details of data stores configuration.
Base Entity Classes
We have refactored base classes of entities to make them more lightweight. Now a minimal entity can have only one required system attribute – id, and it can be mapped to almost any database type including IDENTITY. Moreover, composite keys are also supported.
It means that now you can create CUBA entities for almost any existing database without modifying its schema. So for example, your new CUBA application can work with a legacy database simultaneously with a legacy system. It also allows you to integrate with third party systems by connecting their databases as additional data stores.
Single Sign-On
Single-sign-on (SSO) for CUBA applications allows a user to log in to multiple running applications by entering a single login name and password once in a browser session. This feature is essential for seamless user experience when working with multiple systems. It also helps administrators to manage user passwords in one place when an LDAP integration is not used.
The CUBA SSO requires minimal efforts to set up because any CUBA application can be an Identity Provider (IDP), which is a central element of the SSO infrastructure. All configuration can be done in the deployment stage, so you don’t have to worry about it when developing your applications.
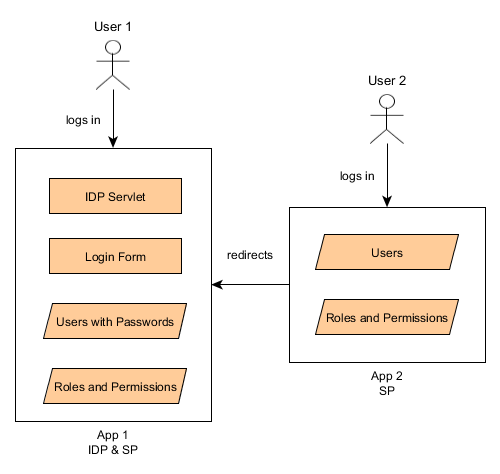
The diagram shows an SSO system with two applications. App 1 is simultaneously an Identity Provider and a Service Provider (i.e. just an application providing some functionality). It contains a special login form shown for all users of the SSO system. App 2 is a Service Provider which redirects users to App 1 IDP for login. User passwords are checked only by IDP, but user roles and permissions are completely separate.
See more information on Single Sign-On in the documentation.
Anonymous Usage
Now you can create applications with UI screens available without login. The platform contains a predefined “anonymous” user, so all the application code working before login is executed on behalf of this user. By default, the anonymous user has all permissions, so do not forget to create a role with only required rights before allowing anonymous access.
How it works: there are two top-level windows in an application: login window and main window. The former works for the anonymous user, the latter – for an authenticated user. By default, the login window contains only the login form, but you can add any visual components and datasources to it, or even main window elements, such as WorkArea for opening other screens. In order to create your own login window for anonymous access, go to the Screens section in Studio and click Create login window.
New REST API
The first version of the universal REST API, included in the platform for a long time, is not quite RESTful – it’s actually a web API providing CRUD and query execution over HTTP. In the platform release 6.3, we are introducing a completely new REST API v2 which conforms to the REST architectural style: usage of URIs and HTTP verbs, OAuth2 authentication. Together with the improved JSON serialization, the new REST API greatly simplifies the creation of web and mobile client applications.
In addition to CRUD operations with entities, the REST API v2 allows you to execute predefined JPQL queries and invoke service methods. Methods must be explicitly permitted by the developer and can accept and return simple types, entities and POJOs, as well as collections of these types. Such a flexible way of working with services saves you from the creation of Spring MVC controllers just for converting Java types to JSON – this conversion can mostly be done automatically. So you just create regular services on the middleware and register exposed methods in rest-services.xml. After that, you can invoke these service methods from your client passing parameters and receiving results in JSON.
The new REST API also provides endpoints for getting current user details and permissions, the information on the application data model and the machine-readable documentation on the REST API itself.
Screen Agent
In the new platform version, there is a mechanism that allows you to adapt your UI screens to different devices: desktops, tablets, phones. You just create multiple versions of the screen layout for each supported device, and give them the same ID but different screen agent values. Then at runtime, the platform will choose an appropriate version of the screen depending on the current device from which the user accesses the application.
This simple approach is not truly responsive because the screen will not transform when a user, for example, changes the device orientation. If you don’t mind writing CSS with media queries, use CssLayout container for fully responsive screens.
Query Cache
A cache is no doubt the most effective performance optimization when you work with a database. And now in addition to the Entity Cache you have a Query Cache with a very simple API. It means that you can just set the cacheable attribute for a datasource, for LoadContext Query of for ORM Query, and the results of this query will be cached and reused next time you execute the query with the same parameters. Of course, a query is evicted from the cache automatically when you update or delete entities of the types used in the query.
Do not forget to set up the Entity Cache for entities, involved in the query caching – the two caches should work together.
Summary
Concluding this article I would like to notice that the majority of the improvements have been made in response to the real user requests, coming from CUBA community. You are most welcome on our support forum to share ideas on how we can make the Platform better.
