“Let it crash” is a watchword in the Erlang world that has a pretty specific meaning in that context, but can be seriously misapplied if taken out of context.
In the erlang world, a “crash” is the termination of an actor in it’s specific context. In a well designed actor system, the actors have very specific jobs and if they cannot complete that job they are free to fail immediately. This is a bit of a problem for folks working in the JVM world as crash can be overloaded to mean things that change the semantics of a transactional system.
Real world(ish) example: Suppose you have a distributed system that accepts a message, writes it to a data store, then hands a new message off to three other components. Suppose further that the transactional semantics of the system are such that the job isn’t “done” until all four operations have completed and are either #1 permanently successful, or #2 permanently failed.
The important detail here is that when performing a transfer, we want the balances of both accounts are updated as a single transaction and we cannot be in a state where the money has left one account, but has not arrived at the other account. To do this requires the concept of a distributed transaction, but without using an “out of the box” distributed transaction coordinator. To clarify, we will assume that the components described are exposed via web services and don’t have access to each other’s underlying transaction management system.
So, to design this, the trivial implementation (let’s call it the synchronous model) is as follows:
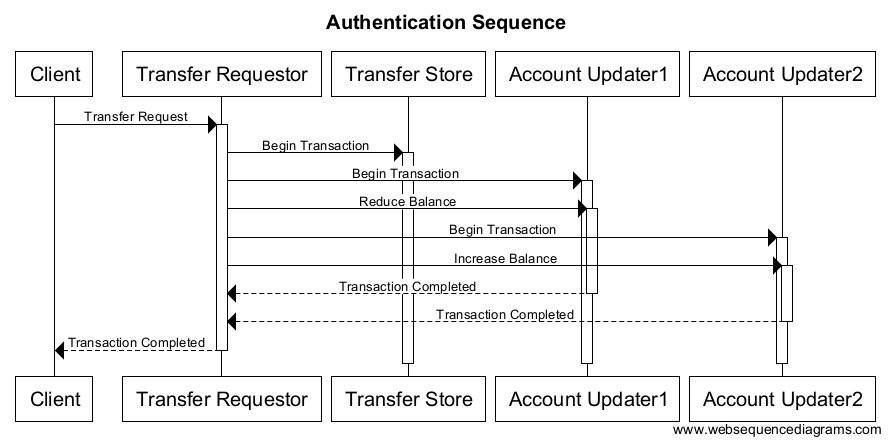
In this model, we need to handle a situation where if EITHER of the nested transactions fail, the requestor can rollback the OTHER transaction also and report back to the client that the entire transaction has failed. I won’t dig into the details, but this is fairly complicated and we’ll leave those details alone. The important detail here is that the entire transaction is synchronous and blocking. This means that the client and the requestor must hang around (typically in memory) waiting for the other components to report “success” or “failure” before reporting anything to the client. Moreover, it means that a failure of any component ultimates is a “permanent” failure (from the client’s perspective), and it’s up to the client to retry the transaction if it’s important. While some failures might genuinely be permanent (one or the other of the accounts maybe don’t or will never exist), while other failures (connectivity to one or other of the accounts updators) may only be transient and/or short lived.
In many ways, this simplifies things as it delegates responsibility of management of success or failure to the leftmost component. That having been said, there is still potential for things to go wrong if, for example, the first updator succeeds, but then the requestor dies and is unable to rollback the first transaction.
When put that way, it’s obvious (I hope), that there needs to be some intermediate management that determines if there are any “partial” transactions if the request processor dies and can immediately rollback partial transactions should a failure occur. As an example, here is what this might look like.
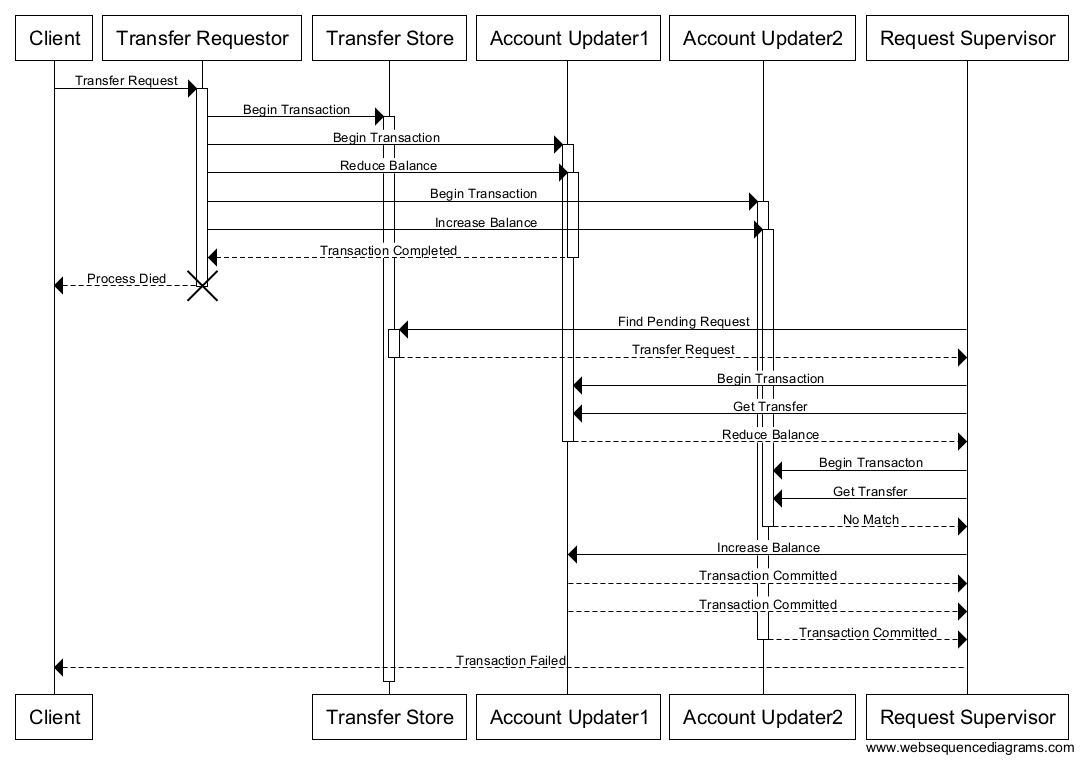
We’re still dodging some internal transaction management housekeeping, but the important detail is that between the point where the client lost track of the requestor (because it died), and the final “transaction failed” from the supervisor, the client has no idea what the state of the transaction is…it genuinely could be that the transaction succeeded, but the connectivity between the transfer requestor and the client simply failed.
So the problems in this model are twofold: #1 it’s “mostly” synchronous (though the Request supervisor -> client messaging clearly isn’t), and #2 it assumes that it’s “OK” for the transfer requestor to simply fail should an intermittant failure in part of the system cause a partial update to have happened. Obviously this may or may not be acceptable depending on the business rules at play, but it is certainly a common model…i.e. you aren’t sure if the transaction worked because, as the client…your network went down, so you get an out of band email from the Request supervisor at your bank confirming that it, in fact, did fail.
While this is a good approach, it does tend to tie up more resources in highly concurrent systems, doesn’t deal with failure very well (you only have a few hard coded strategies you can use), and when you scale to dozens or hundreds of components, the chances of a single failure become so large that you are unlikely to EVER succeed.
So what’s the alternative?
The detail here (which enables more flexibility), is to assume things will intermittantly fail, and design the transaction semantics into the application protocol. This allows you to have “less robust” individual components, but adds the complexity of transaction management to the entire system. An example of how this might work:
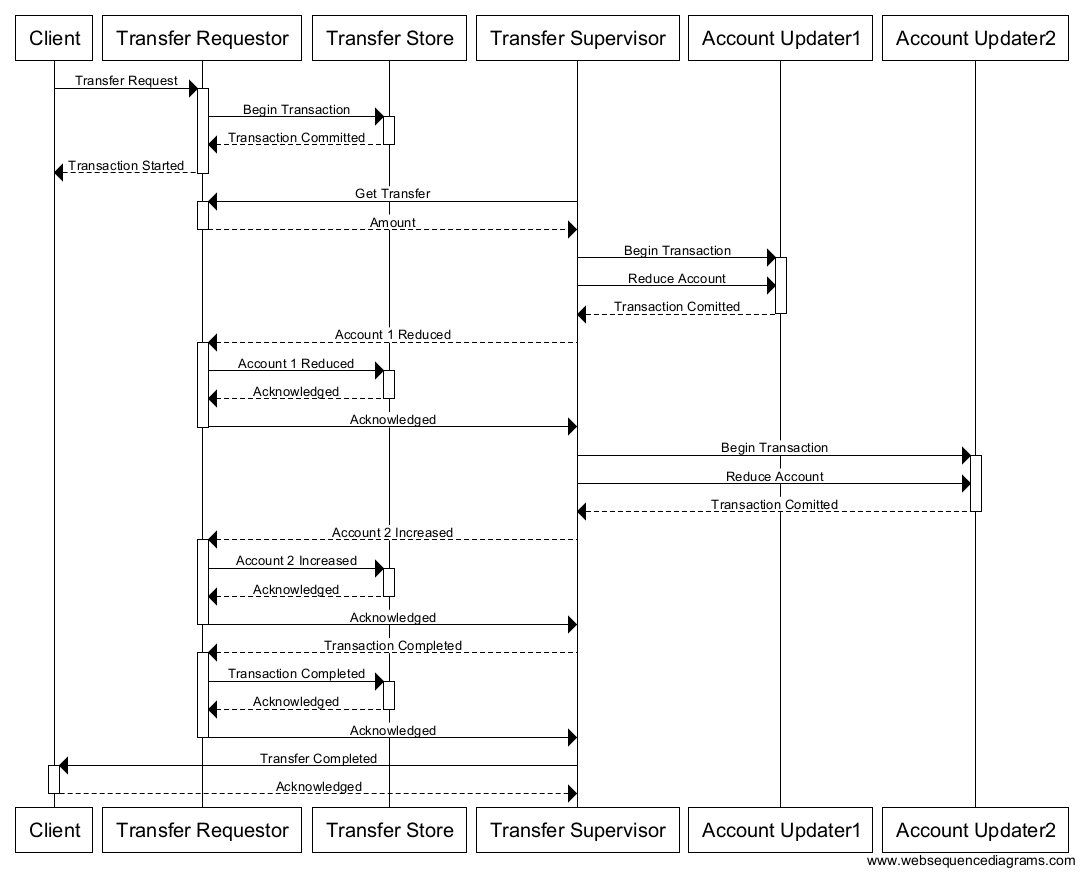
The important details here are: #1 transaction details become persistant in the Transfer Store, #2 the Transfer Supervisor takes on the reponsibilitiy for the semantics of how the transaction strategy is managed, #3 the transaction gains the capabilities to become durable across transient failures with “most” components in the system, and #4 each independant component only needs to be available for smaller amounts of time. In general these are all desirable qualities, but…
The devil is in the details
Some of the negative side effects of this approach are that: #1 as the designer of the system, you now are explicitly reponsibile for the details of the transactional behavior, #2 if the system is to be robust across component failures, the operations must be idempotent (not have side effects across invocations). As an example of how this might be more robust, let’s look at how we might implement a behavior that is durable across transient failures:

In this model, the transfer supervisor implements a simple retry strategy when the account requestor is unavailable. While this potentially make the system more robust and accounts for failure with much more flexibility, it’s obvious that the Account Requestor (or the store) needs to be able to discern that sometimes it might recieve duplicates and be able to handle that gracefully. Additionally, it becomes more important to know the difference between something that mutates state and something that simply acknowledges that it is in agreement with your perspective on the state of the system.
More importantly, the latter approach now means we must take into account the difference between a “permanent failure”, and a “transient failure” and this is often not a trivial task…i.e. transferring between a nonexistant account and a real account a transient problem or not?…if you think that’s a trivial answer, think about a situation where there yet another async process that creates and destroys accounts? Is it acceptable to retry in 1 minute (in case the account is in the process of being created when you initially try the transfer?).
In conclusion, while distributing transactions into smaller pieces adds great power, it also comes with great responsibilitiy. This approach to designing systems is the genisys of the “let it crash” mantra bandied about by Scala and Erlang acolytes. “Let it crash” doesn’t necessarily mean “relax your transaction semantics” or “don’t handle errors”, it means you can delegate responsibilty for recovery from failure out of a synchronous process and deal with it in more robust and novel ways.
| Reference: | Let it crash from our JCG partner Mike Mainguy at the mike.mainguy blog. |
