DCHQ + EMC REX-Ray Delivering Container Database Services On Multiple Clouds And Virtualization Platforms
DCHQ On-Premise v4.0 is now available in preview mode supporting Container Database Services (CDS), Microsoft Azure Resource Manager, Alibaba Aliyun, OVH Public Cloud, application log streaming, and other great features.
The CDS offering integrates with EMC REX-Ray to provide scalable and highly available databases on containers supporting multi-host clustering, backup, replication, and automatic database recovery.
https://youtu.be/EEilhmzMVdQ
Templates for clustered MySQL, MariaDB, PostgreSQL, Oracle XE, Mongo and Cassandra are available. The new offering also supports storage platforms from EMC, Amazon, OpenStack, Rackspace, and Google. Watch the recorded demos on this page: http://dchq.co/container-database-services.html
DCHQ v4.0 will be unveiled at EMC World. You can download DCHQ On-Premise v4.0 (Preview Mode) by completing the download form on this page. http://dchq.co/dchq-on-premise.html
In this blog, we will cover the deployment automation of an Enterprise Java application with PostgreSQL multi-host cluster set up for Master-Slave replication and automated storage management with redundant EBS volumes on AWS using DCHQ + EMC REX-Ray.
What is DCHQ?
DCHQ deploys and manages existing enterprise applications and cloud-native applications seamlessly across any cloud or container infrastructure – including VMware vSphere, OpenStack, OVH, AWS, Microsoft Azure, and many others.
It provides “on-the-fly” containerization of enterprise applications – including Oracle Database Cluster, SAP, and others. By doing so, DCHQ transforms non-cloud-native applications into completely portable applications that can take advantage of cloud scaling, storage redundancy and most importantly, deployment agility.
DCHQ supports advanced multi-tier applications providing data binding and injection to capture complex dependencies across application components. It also provides an infinitely flexible plug-ins framework that can be invoked at 20+ application life-cycle states to provide service discovery and automatic application updates.
The platform is tailored for enterprises providing a clear separation of concerns with role-based access controls, quota policies based on resource utilization, entitlements to extend management of apps to other business users, approval policies to enable painless management, and cost profiles to enable resource billing.
The application-modeling framework enables modular app blueprints using component profiles, storage profiles, DBaaS profiles, and configuration scripting profiles. Once an application is deployed, users get access to monitoring, alerts, continuous delivery, application backups, scale in/out, in-browser terminal to access the containers, log streaming, and application updates.
DCHQ Overview
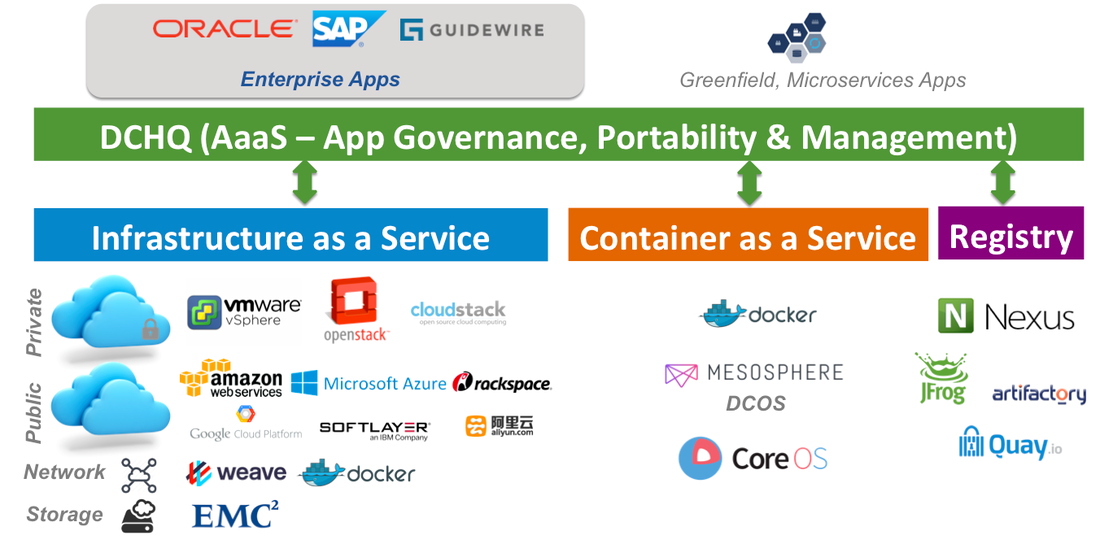
DCHQ Platform Features

DCHQ Workflow

Automated Persistent Storage Management for Docker Applications using DCHQ and EMC REX-Ray
The EMC open-source project, REX-Ray, provides vendor-agnostic persistent storage for Docker containers. It allows developers and database administrators to perform storage management tasks through a standard command line interface. The project supports storage providers that include AWS EC2 (EBS), OpenStack (Cinder), EMC Isilon, EMC ScaleIO, EMC VMAX, EMC XtremIO, Google Compute Engine (GCE), and VirtualBox.
The REX-Ray project addresses the container database storage management challenges – but does not provide the automation, scalability and high-availability deployment options needed for managing container databases in production.
DCHQ, which specializes in enterprise Docker application modeling, deployment, service discovery and management, is now offering “container database services” or CDS. The offering provides scalable and highly available databases on containers.
The new offering allows users to:
- Run highly available and scalable databases on containers with support for multi-host clustering, backup, replication, and automatic database recovery.
- Use out-of-box container database templates for clustered MySQL, MariaDB, PostgreSQL, Oracle XE, Mongo, and Cassandra.
- Create custom storage management tasks through DCHQ plug-ins that can be invoked at different life-cycle stages of application deployment.
- Deploy an application with all of its necessary storage services on any virtual machine or bare metal server, running in public clouds or private data centers.
3 Easy Steps to Set Up your Docker Cluster
Before you start, you will need to get access to DCHQ:
- Sign Up on DCHQ.io — http://dchq.io (no credit card required), or
- Download DCHQ On-Premise — http://dchq.co/dchq-on-premise-download.html
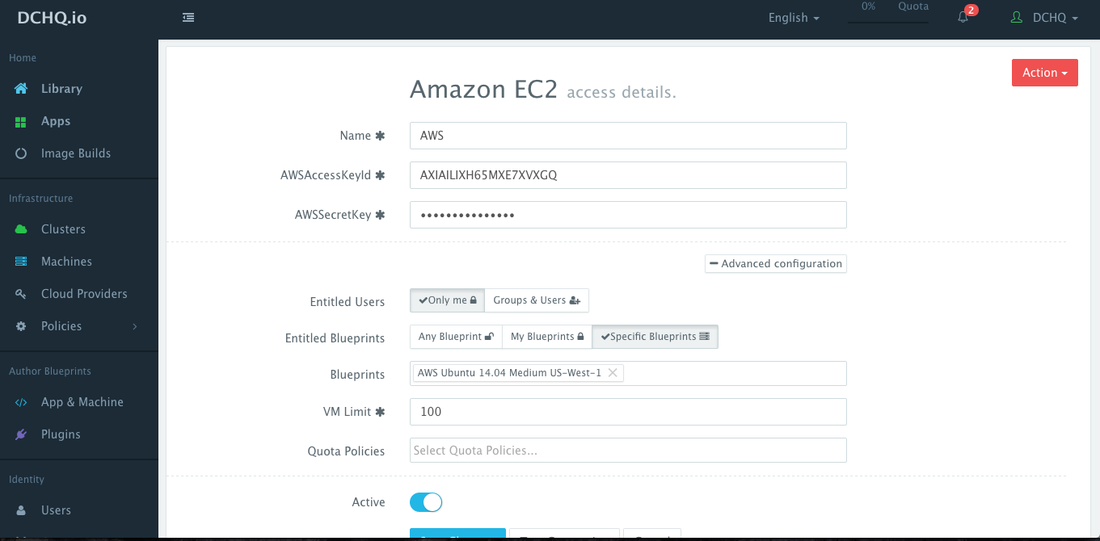
Step 1 – Create a Cloud Provider
First, a user can register a Cloud Provider for any of the 18 clouds & virtualization platforms that DCHQ supports. In this blog, automated provisioning on AWS is covered. Registering a Cloud Provider can be done by navigating to Cloud Providers and then clicking on the + button to select Amazon EC2. The only required fields are:
- AWS Access Key
- AWS Secret Key
The optional fields allow you to enforce granular access controls and associate this provider with a quota policy.
- Entitled Users — these are the users who are allowed to use this Cloud Provider for infrastructure provisioning. The entitled users do not have permission to manage or delete this cloud provider and will not be able to view any of the credentials.
- Entitled Blueprints — these are the Machine Compose templates that can be used with this cloud provider. For example, if a Tenant Admin wishes to restrict users to provisioning 4GB machines on certified operating systems, then users will not be able to use this cloud provider to provision any other machine.
- VM Limit — this is the maximum number of virtual machines that can be used with this cloud provider
- Quota Policies — these are pre-defined policies for setting quotas on the number of VM’s or the cost of VM’s. Multiple quota policies can be selected to customize controls per user or per group of users.
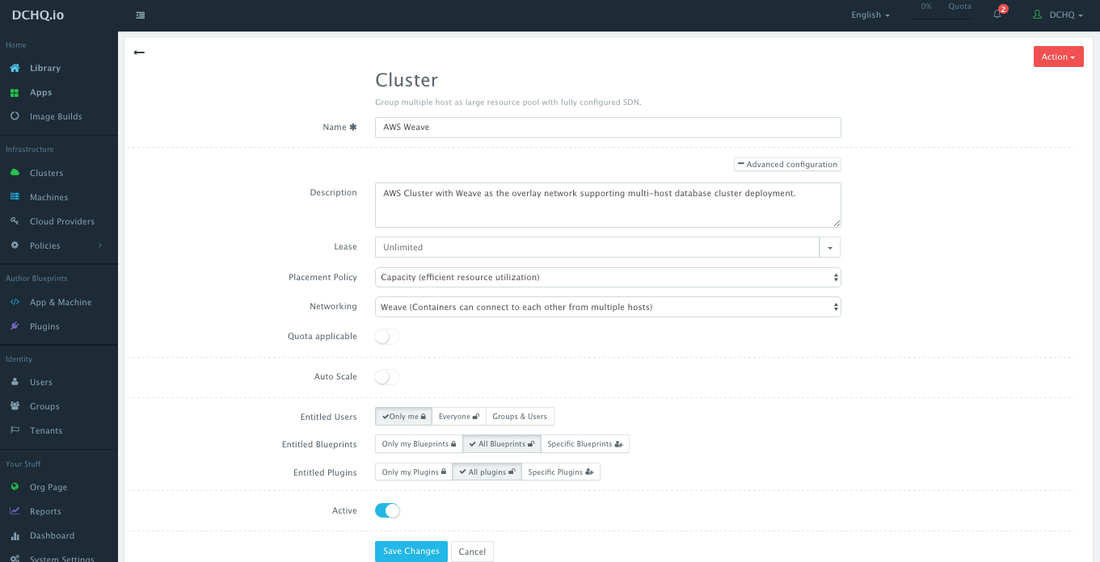
Step 2 – Create a Cluster for AWS using Weave’s Overlay Network
Servers across hybrid clouds or local development machines can be associated with a cluster, which is a logical mapping of infrastructure. A user can create a cluster by navigating to Clusters page and then clicking on the + button.
A cluster has advanced options, like:
- Lease – a user can specify when the applications deployed on servers in this cluster expire so that DCHQ can automatically destroy those applications.
- Placement Policy – a user can select from a number of placement policies like a proximity-based policy, round robin, or the default policy, which is a capacity-based placement policy that will place the Docker workload on the host that has sufficient compute resources.
- Networking – a user can select either Docker networking or Weave as a software-defined networking to facilitate cross-container communication across multiple hosts
- Quota – a user can indicate whether or not this cluster adheres to the quota profiles that are assigned to users and groups. For example, in DCHQ.io, all users are assigned a quota of 8GB of Memory.
- Auto-Scale Policy – a user can define an auto-scale policy to automatically add servers if the cluster runs out of compute resources to meet the developer’s demands for new container-based application deployments
- Granular Access Controls – a tenant admin can define access controls to a cluster to dictate who is able to deploy Docker applications to it through Entitled Users. For example, a developer may register his/her local machine and mark it as private. A tenant admin, on the other hand, may share a cluster with a specific group of users or with all tenant users. Additionally, the cluster owner can specify what application templates can be deployed to this cluster through Entitled Blueprints. If the cluster will be used in upstream environments, then only specific application templates (or “blueprints”) can be deployed on it.
Step 3 – Provision New AWS Instances into the Cluster
A user can provision AWS Instances on the newly created cluster by defining a simple YAML-based Machine Compose template that can be requested from the Self-Service Library.
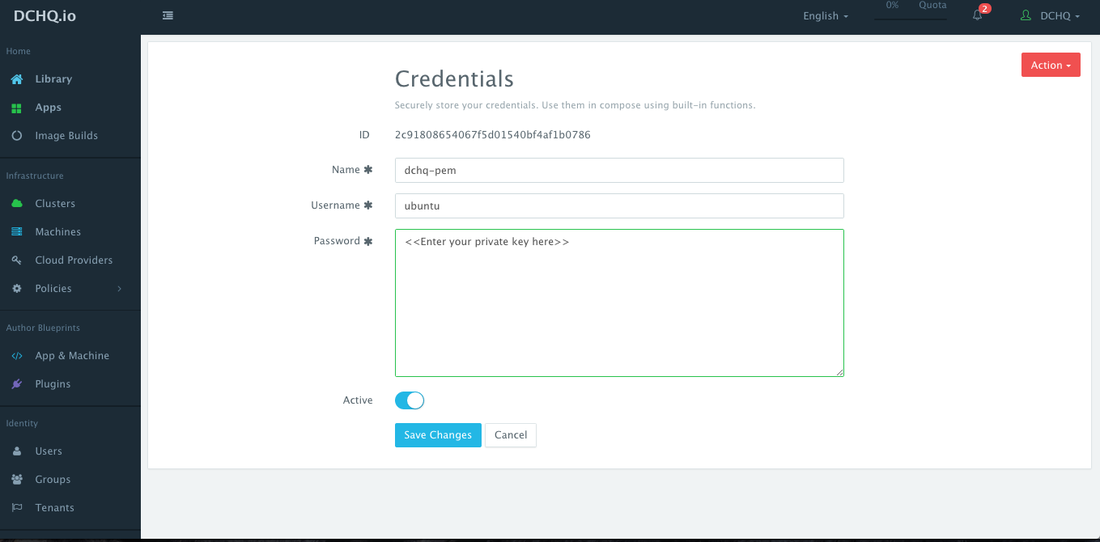
(Recommended) Before creating a Machine Compose template, a user can securely store the private key (or PEM file) in the Credentials Store. This can be done by navigating to Cloud Providers and then clicking on the + button to select Credentials. The username and the password need to be provided. Once this credential item is saved, then click Edit on the new item saved to copy the newly generated ID for this credential item.
A user can create a Machine Compose template for AWS by navigating to App & Machine and then clicking on the + button to select Docker Machine.
Here’s the template for requesting 3 AWS t2.medium instances in the us-west-1 region.
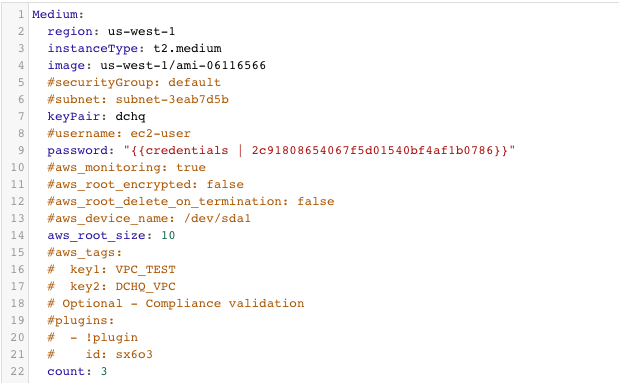
The supported parameters for the Machine Compose template are summarized below:
- description: Description of the blueprint/template
- subnet: Cloud provider specific value (e.g. subnet ID for AWS)
- instanceType: Mandatory — cloud provider specific value (e.g. general1-4)
- region: Mandatory — cloud provider specific value (e.g. IAD)
- image: Mandatory – fully qualified image ID/name (e.g. IAD/5ed162cc-b4eb-4371-b24a-a0ae73376c73 or vSphere VM Template name)
- aws_root_size: Mandatory – the size of the disk to be attached to the instance in GB
- aws_root_encrypted: a Boolean value for whether to encrypt the root disk or not
- aws_root_delete_on_termination: a Boolean value for whether to delete the root disk on terminating the instance
- aws_device_name: the path or directory for the device
- aws_tags: key pair values that can be passed with the instance provisioning
- username: This the username used to connect to the server
- password: This can reference a private key stored in the Credentials store. The ID of the credential item stored in the Manage > Cloud Providers page will be needed. Here’s the acceptable format: “{{credentials | 2c91802a520736224015209a6393098322}}”
- network: Optional – Cloud provider specific value (e.g. default)
- securityGroup: Cloud provider specific value (e.g. default)
- keyPair: Cloud provider specific value (e.g. private key name)
- openPorts: Optional – comma separated port values
- count: Total no of VM’s, defaults to 1.
In addition to these supported parameters, you will also notice that this template is referencing a “plugin”. A plugin can be invoked as follows:
plugins: - !plugin id: <plugin-id>
The plug-in can be created by Navigating to Manage > Plugins and then clicking on the + button. A plug-in is a simple script that can run on either the server being provisioned or on the Docker container. The server plugins can be used for any number of configuration requirements:
- Installing Puppet Modules, Chef Recipes, Ansible Playbook, etc.
- Retrieving the CA certificate needed for the private Docker registry from a secure S3 bucket and then saving it in the right directory (e.g. /etc/docker/certs.d/<domain-name>:5000/ca.crt)
The Machine Compose template has additional advanced options.
- Cost Profiles — these are the cost profiles that you can create under Manage > Cost Profiles. You can define cost per resource on an hourly/weekly/monthly basis. You can attach multiple cost profiles to a single template — e.g. different cost profiles for the instance type, EBS storage used, etc.
- Entitled Users — these are the users who are allowed to use this template to provision AWS instances. The entitled users do not have permission to manage or delete this template and will only be able to consume it.
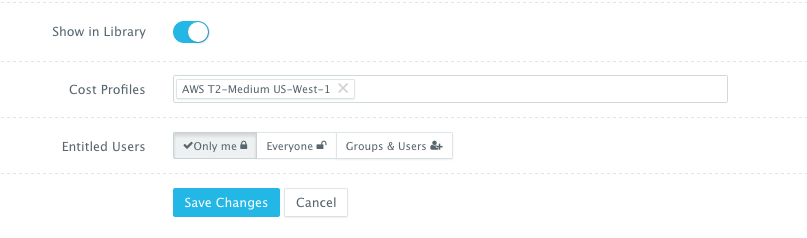
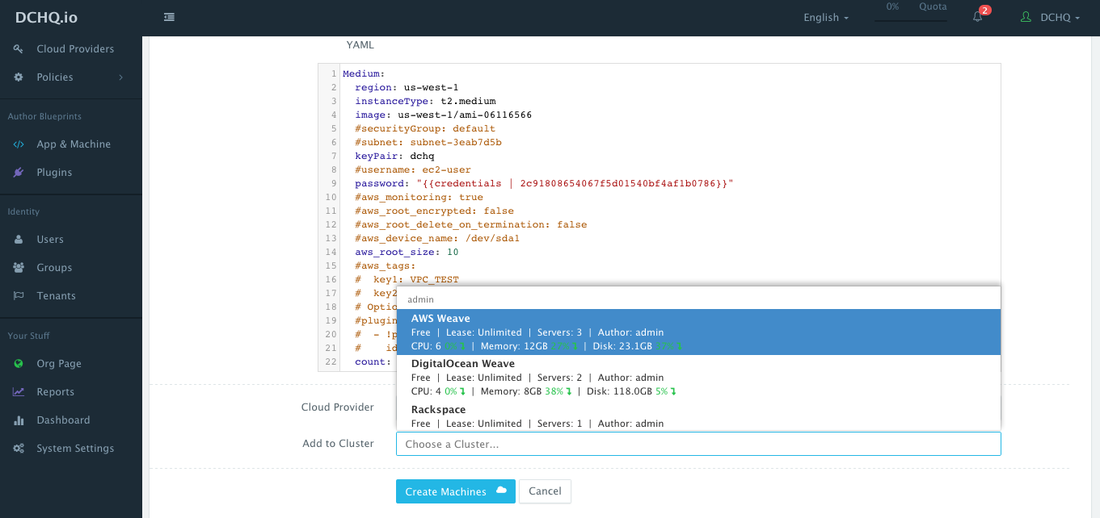
Once the Docker Machine template is saved, a user can request this machine from the Self-Service Library. A user can click Customize and then select the Cloud Provider and Cluster to use for provisioning the AWS Instance(s).
Since Weave was selected as the overlay network, the Weave cluster will be automatically set up for the 3 AWS instances provisioned using DCHQ.
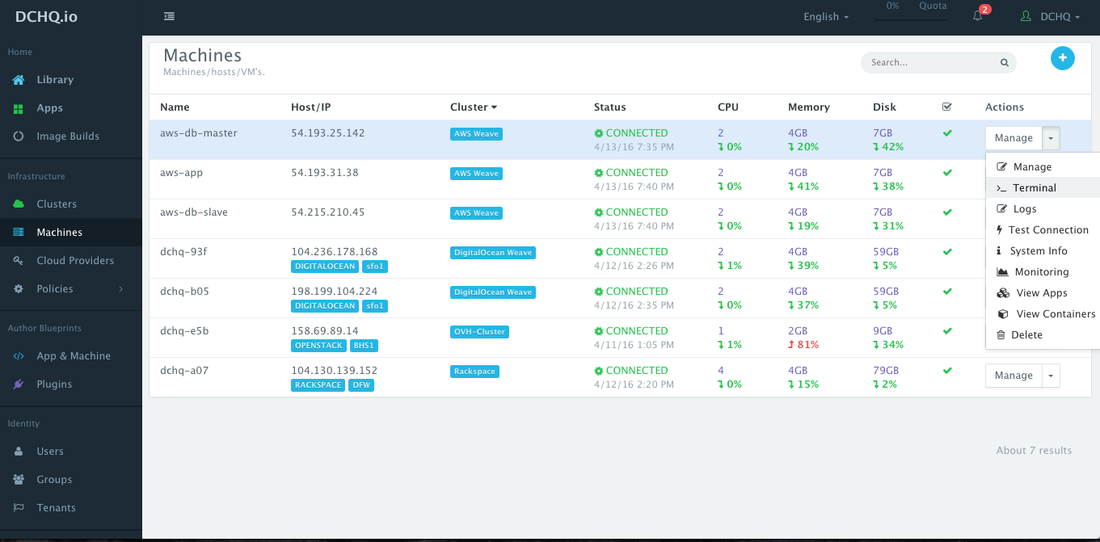
Once the AWS instances are provisioned, a user can monitor key statistics like CPU, Memory, Disk Utilization, Images Pulled and Containers Running. This can be done by navigating to Machines and then selecting Monitoring from the Manage drop-down menu.
An in-browser terminal to the provisioned machine is also accessible. This can be accessed by navigating to Machines and then selecting Terminal from the Manage drop-down menu.

Deploying An Enterprise Java Application with PostgreSQL Multi-Host Cluster Set Up for Master-Slave Replication on the AWS Cluster with Persistent Storage Management by REX-Ray
Now that the AWS cluster is set up, you can now run any Docker application on the newly created server(s). This can be done by navigating to the Library and then clicking on Customize on any of the published application templates. You can then select a Cluster and click Run.
Check out our published Docker application templates — including multi-tier Java stacks, LAMP, LAOP & LAPP stacks, Node.js, Rails, Python, Mongo Replica Set, Couchbase Cluster, MEAN.JS, WordPress, Drupal, and many others.
Creating The Application Template
Docker Compose is a YAML template for defining multi-tier or multi-image distributed applications that can run on any Docker-enabled Linux host running anywhere.
Once logged in to DCHQ (either the hosted DCHQ.io or on-premise version), a user can navigate to App & Machine and then click on the + button to create a new Docker Compose template.
Here’s the example template that contains the following components:
• Apache HTTP Server — for reverse proxy and load balancing
• Tomcat — the application server running the Java application
• PostgreSQL Master — this is the master PostgreSQL database
• PostgreSQL Slave — this is the slave PostgreSQL database
HTTP-LB:
image: httpd:latest
publish_all: true
mem_min: 50m
host: host1
plugins:
- !plugin
id: uazUi
restart: true
lifecycle: on_create, post_scale_out:AppServer, post_scale_in:AppServer
arguments:
# Use container_private_ip if you're using Docker networking
#- BalancerMembers=BalancerMember http://{{AppServer | container_private_ip}}:8080
# Use container_hostname if you're using Weave networking
- BalancerMembers=BalancerMember http://{{AppServer | container_hostname}}:8080
AppServer:
image: tomcat:8.0.21-jre8
mem_min: 600m
host: host1
cluster_size: 1
environment:
- database_driverClassName=org.postgresql.Driver
# Use this configuration with Docker networking
#- database_url=jdbc:postgresql://{{postgres_master|container_private_ip}}:5432/{{postgres_master|DB_NAME}}
# Use this configuration with Weave
- database_url=jdbc:postgresql://{{postgres_master|container_hostname}}:5432/{{postgres_master|DB_NAME}}
- database_username={{postgres_master|DB_USER}}
- database_password={{postgres_master|DB_PASS}}
plugins:
- !plugin
id: oncXN
restart: true
arguments:
- file_url=https://github.com/dchqinc/dchq-docker-java-example/raw/master/dbconnect.war
- dir=/usr/local/tomcat/webapps/ROOT.war
- delete_dir=/usr/local/tomcat/webapps/ROOT
postgres_master:
restart: always
host: host2
#ports:
# - 5432:5432
image: dchq/postgres:latest
environment:
- DEBUG=false
- DB_USER=root
- DB_PASS={{alphanumeric | 8}}
- DB_NAME=names
- DB_UNACCENT=false
- REPLICATION_MODE=master
- REPLICATION_USER=replicator
- REPLICATION_PASS={{alphanumeric | 8}}
volumes:
- "/var/lib/rexray/volumes/dchq-postgres-master/data:/var/lib/postgresql"
plugins:
- !plugin
# Only mounts volume
#id: CmA35
# Create and mount volume
id: 8CF1C
lifecycle: exec_on_machine pre_create
arguments:
- VOLUME_NAME=dchq-postgres-master
- VOLUME_SIZE=5
# Nightly snapshot
#- !plugin
# id: dE4qG
# lifecycle: exec_on_machine cron(0 1 1 * * ?)
# arguments:
# - VOLUME_NAME=dchq-postgres-master
postgres_slave:
restart: always
host: host3
#ports:
# - 5432:5432
image: dchq/postgres:latest
environment:
- DEBUG=false
- REPLICATION_MODE=slave
# Use this configuration with Docker networking
#- REPLICATION_HOST={{postgres_master | container_private_ip}}
# Use this configuration with Weave
- REPLICATION_HOST={{postgres_master | container_hostname}}
- REPLICATION_USER={{postgres_master | REPLICATION_USER}}
- REPLICATION_PASS={{postgres_master | REPLICATION_PASS}}
- REPLICATION_PORT=5432
volumes:
- "/var/lib/rexray/volumes/dchq-postgres-slave/data:/var/lib/postgresql"
plugins:
- !plugin
# Only mounts volume
#id: CmA35
# Create and mount volume
id: 8CF1C
lifecycle: exec_on_machine pre_create
arguments:
- VOLUME_NAME=dchq-postgres-slave
- VOLUME_SIZE=5
# Nightly snapshot
#- !plugin
# id: dE4qG
# lifecycle: exec_on_machine cron(0 1 1 * * ?)
# arguments:
# - VOLUME_NAME=dchq-postgres-masterUsing Environment Variable Bindings To Capture Complex App Dependencies
A user can create cross-image environment variable bindings by making a reference to another image’s environment variable. In this case, we have made several bindings including database_url=jdbc:postgresql://
{{postgres_master|container_hostname}}:5432/{{postgres_master|DB_NAME}} – in which the database container internal IP address is resolved dynamically at request time and is used to ensure that Tomcat can establish a connection with the database.
Here is a list of supported environment variable values:
- {{alphanumeric | 8}} – creates a random 8-character alphanumeric string. This is most useful for creating random passwords.
- {{Image Name | ip}} – allows you to enter the host IP address of a container as a value for an environment variable. This is most useful for allowing the middleware tier to establish a connection with the database.
- {{Image Name | container_hostname}} or {{Image Name | container_ip}} – allows you to enter the name of a container as a value for an environment variable. This is most useful for allowing the middleware tier to establish a secure connection with the database (without exposing the database port).
- {{Image Name | container_private_ip}} – allows you to enter the internal IP of a container as a value for an environment variable. This is most useful for allowing the middleware tier to establish a secure connection with the database (without exposing the database port).
- {{Image Name | port_Port Number}} – allows you to enter the Port number of a container as a value for an environment variable. This is most useful for allowing the middleware tier to establish a connection with the database. In this case, the port number specified needs to be the internal port number – i.e. not the external port that is allocated to the container. For example, {{PostgreSQL | port_5432}} will be translated to the actual external port that will allow the middleware tier to establish a connection with the database.
- {{Image Name | Environment Variable Name}} – allows you to enter the value an image’s environment variable into another image’s environment variable. The use cases here are endless – as most multi-tier applications will have cross-image dependencies.
Using Plug-Ins For Storage Management Automation using REX-Ray And The Host Parameter To Deploy A Multi-Host Cluster of PostgreSQL
The host parameter allows you to specify the host you would like to use for container deployments. This is possible if you have selected Weave as the networking layer when creating your clusters. That way you can ensure high-availability for your application server clusters across different hosts (or regions) and you can comply with affinity rules to ensure that the database runs on a separate host for example. Here are the values supported for the host parameter:
- host1, host2, host3, etc. – selects a host randomly within a data-center (or cluster) for container deployments
- IP Address 1, IP Address 2, etc. — allows a user to specify the actual IP addresses to use for container deployments
- Hostname 1, Hostname 2, etc. — allows a user to specify the actual hostnames to use for container deployments
- Wildcards (e.g. “db-”, or “app-srv-”) – to specify the wildcards to use within a hostname
In this case, postgres_master and postgres_slave containers will be running on two separate hosts — as indicated by the host2 and host3 values.
DCHQ also provides an infinitely flexible plug-ins framework that can be invoked at 20+ application life-cycle states to provide service discovery and automatic application updates.
In this case, the plug-ins are used to automate the storage management tasks for the database cluster. The plug-ins invoke REX-Ray to create, mount and take of snapshots of AWS EBS volumes that are mapped to both the PostgreSQL master and PostgreSQL slave containers. You can download DCHQ On-Premise to get access to these out-of-box plug-ins.
There are three plug-ins that invoke REX-Ray to automate storage management in this template.
- id: CmA35 — this plug-in is commented out but can be un-commented if a user would like to simply mount an existing EBS volume to a database container. This is useful for restoring databases from snapshots or for using data in testing.
- id: 8CF1C — this plug-in is active and used to create & mount an EBS volume to a database container. You will notice that the plug-in arguments allow you to provide the volume name and size — abstracting the complexity of the CLI commands from the user.
- id: dE4qG — this plug-in can be used to take regular snapshots of the EBS volume using a simple cron expression to schedule these snapshots.
The lifecycle parameter in plug-ins allows you to specify the exact stage or event to execute the plug-in. If no lifecycle is specified, then by default, the plug-in will be execute on_create. Here are the supported lifecycle stages:
- on_create — executes the plug-in when creating the container
- on_start — executes the plug-in after a container starts
- on_stop — executes the plug-in before a container stops
- on_destroy — executes the plug-in before destroying a container
- post_create — executes the plug-in after the container is created and running
- post_start[:Node] — executes the plug-in after another container starts
- post_stop[:Node] — executes the plug-in after another container stops
- post_destroy[:Node] — executes the plug-in after another container is destroyed
- post_scale_out[:Node] — executes the plug-in after another cluster of containers is scaled out
- post_scale_in[:Node] — executes the plug-in after another cluster of containers is scaled in
- exec_on_machine — executes the plug-in on the underlying machine (host)
- pre_create — executes the plug-in before launching the container
Deploying The Java Application with PostgreSQL Cluster on AWS
This can be done by navigating to the Library and then clicking on Customize on any of the published application templates. You can then select a Cluster and click Run.
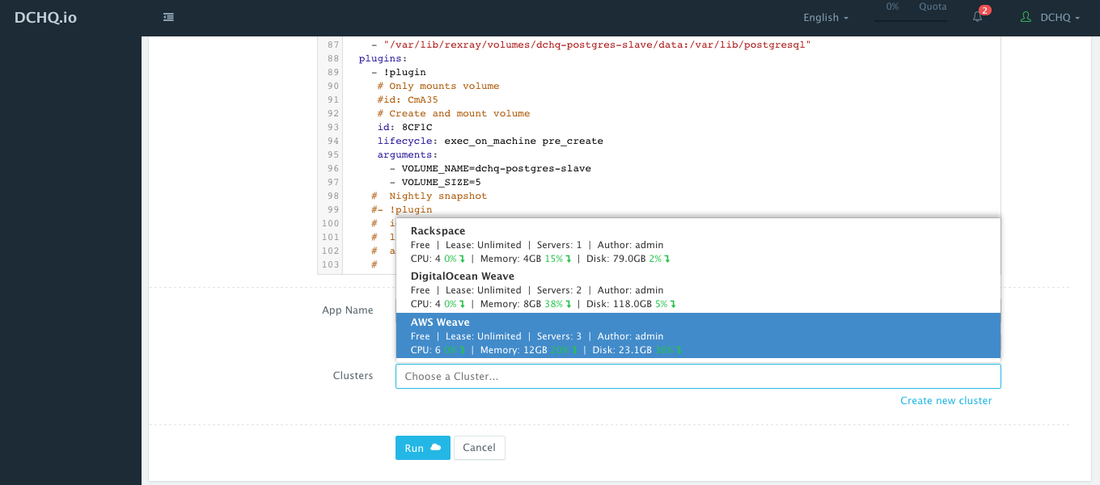
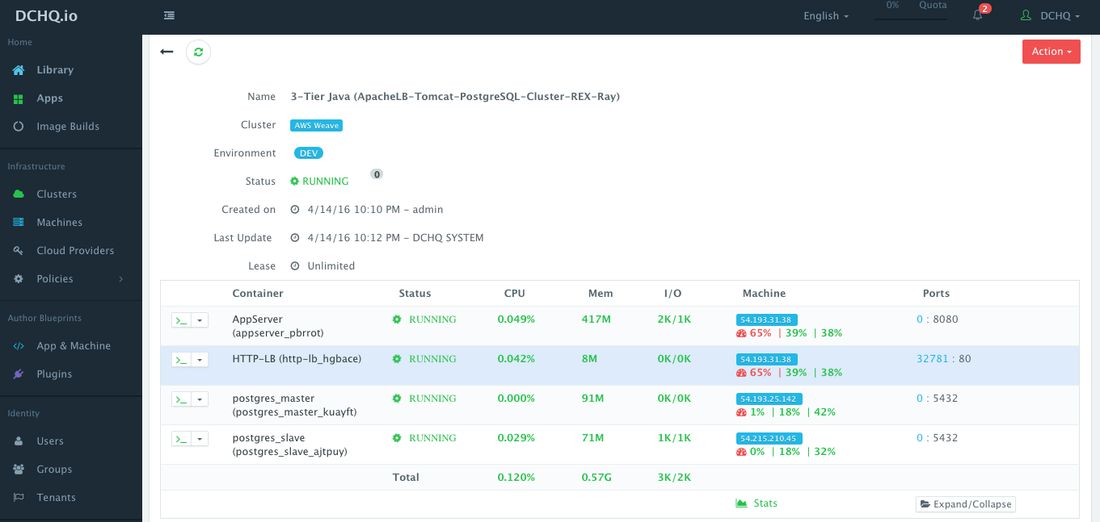
Access The Deployed Application
Once an application is deployed, users get access to monitoring, alerts, continuous delivery, application backups, scale in/out, in-browser terminal to access the containers, log streaming, and application updates.
To access the application, a user can simply click on the exposed port for Apache HTTP Server.
You will notice that PostgreSQL Master and PostgreSQL Slave are running on separate AWS instances. These instances could have been across different regions to ensure high-availability. The Weave overlay network is allowing these containers to communicate without exposing port 5432 on the host.
The application deployed is a simple names directory application. You can save a couple of names for testing.
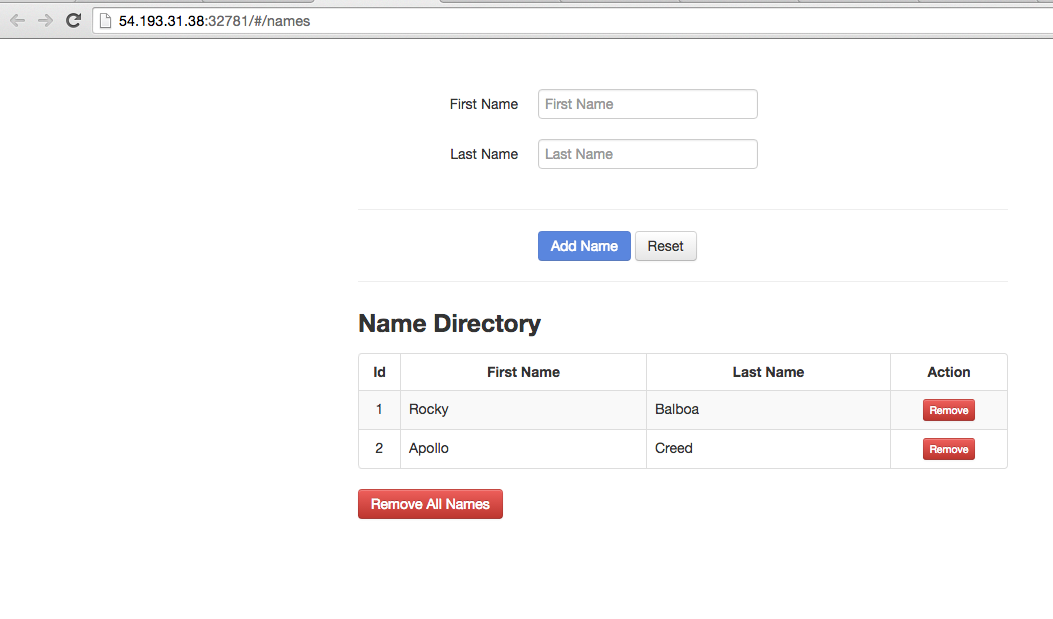
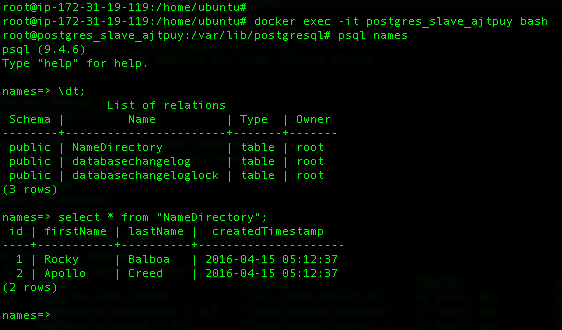
Verify that the PostgreSQL Replication is Working
Now that we’ve saved a couple of names in our Java application, we can verify if these names were replicated properly on the PostgreSQL slave container.
Here are the commands used to perform this verification on the host running the postgres_slave_ajtpuy container.
## Execute these commands on the host running the postgres_slave container ## Enter the postgres_slave container docker exec -it [postgres_slave_container_name] bash ## Access the names database using psql psql names ## List the tables \dt; ## Select the data from the "namedirectory" table select * from "NameDirectory";
Verify that the EBS Volumes were Created on AWS
Log in to the AWS Console and verify that two separate EBS volumes were created and attached to the PostgreSQL Master and the PostgreSQL Slave containers.
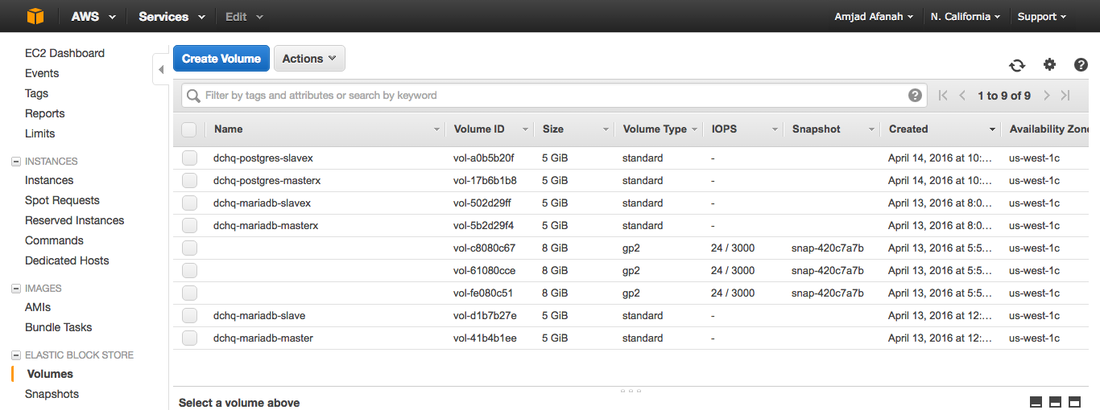
Monitor The Performance Of Containers
Once the application is up and running, users can monitor the CPU, Memory, & I/O of the running containers to get alerts when these metrics exceed a pre-defined threshold. DCHQ also monitors the underlying AWS instances on which the application is running — capturing metrics like CPU. Memory, and Disk Utilization.
A user can perform historical monitoring analysis and correlate issues to container updates or build deployments. This can be done by clicking on the Stats link. A custom date range can be selected to view CPU, Memory and I/O historically.
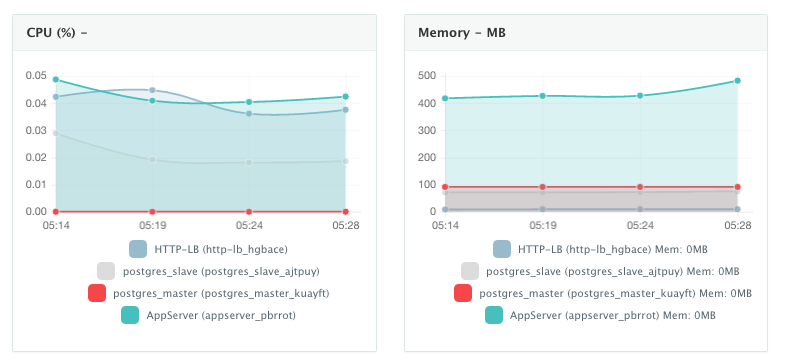
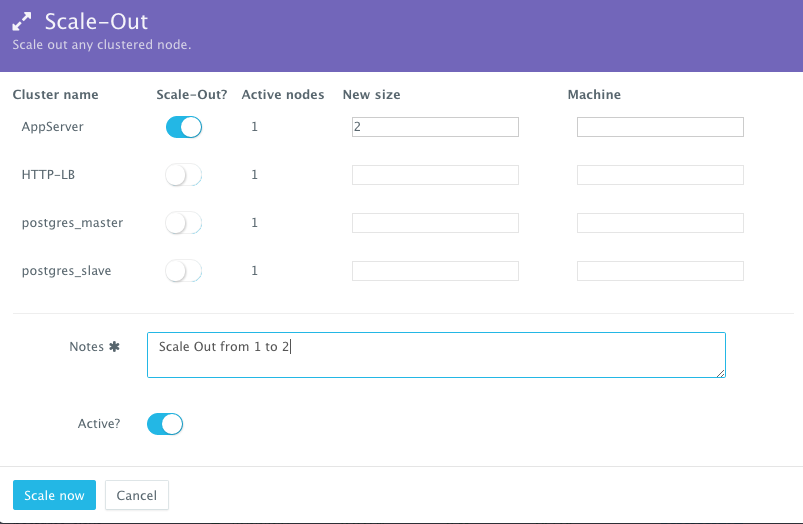
Scale Out The Application
If the running application becomes resource constrained, a user can to scale out the application to meet the increasing load. Moreover, a user can schedule the scale out during business hours and the scale in during weekends for example.
To scale out the cluster of Tomcat servers from 1 to 2, a user can click on the Actions menu of the running application and then select Scale Out. A user can then specify the new size for the cluster and then click on Run Now.
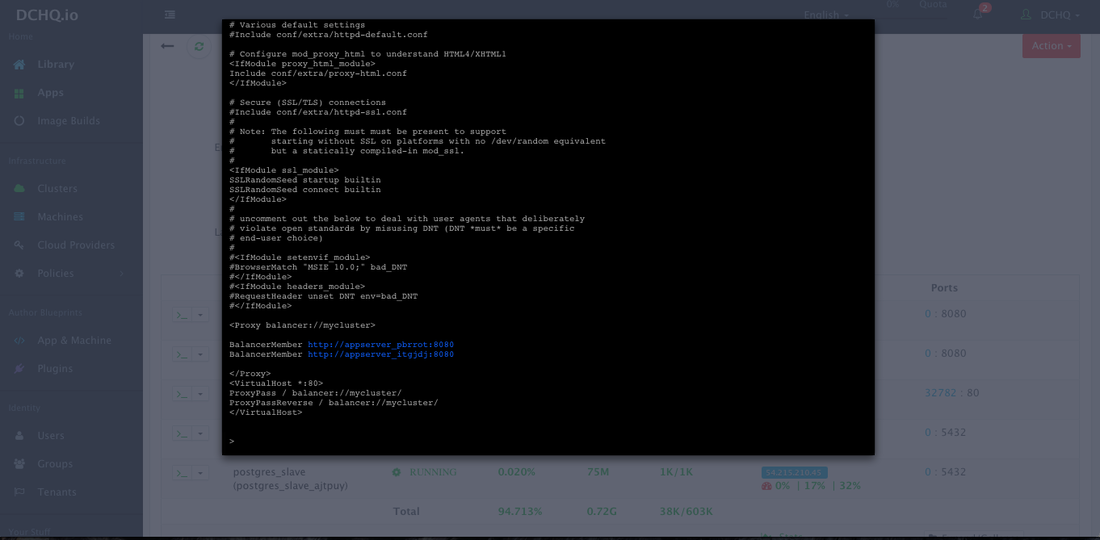
As the scale out is executed, the Service Discovery framework will be used to update the load balancer. A plug-in will automatically be executed on Apache HTTP Server to update httpd.conf file so that it’s aware of the new application server added. This is because we have specified post_scale_out:AppServer as the lifecycle event for this plugin.
An application time-line is available to track every change made to the application for auditing and diagnostics. This can be accessed from the expandable menu at the bottom of the page of a running application. In this case, the Service Discovery framework executed the Apache HTTP Server plugin automatically right after the Application Server cluster was scaled out.
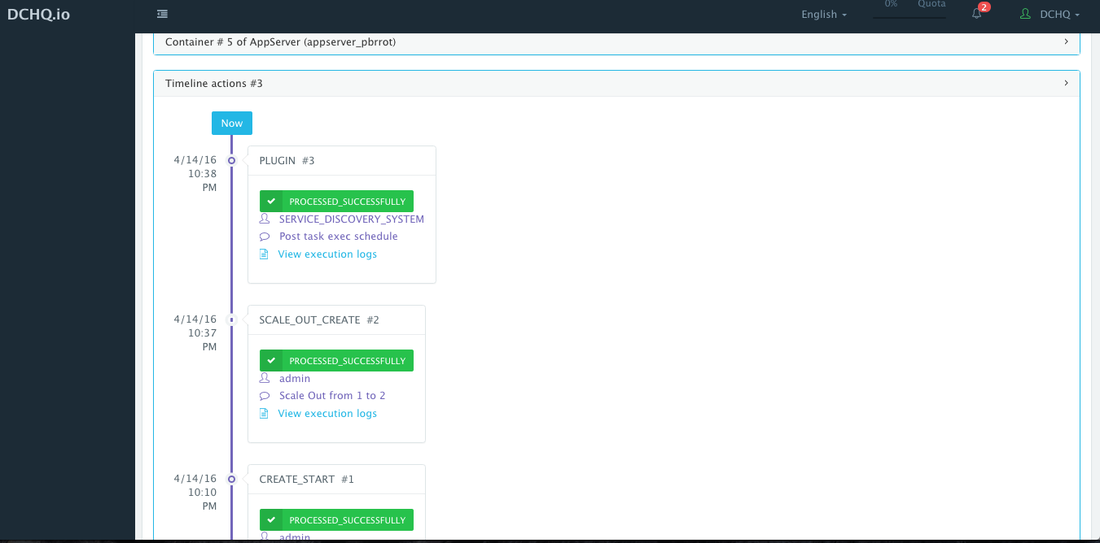
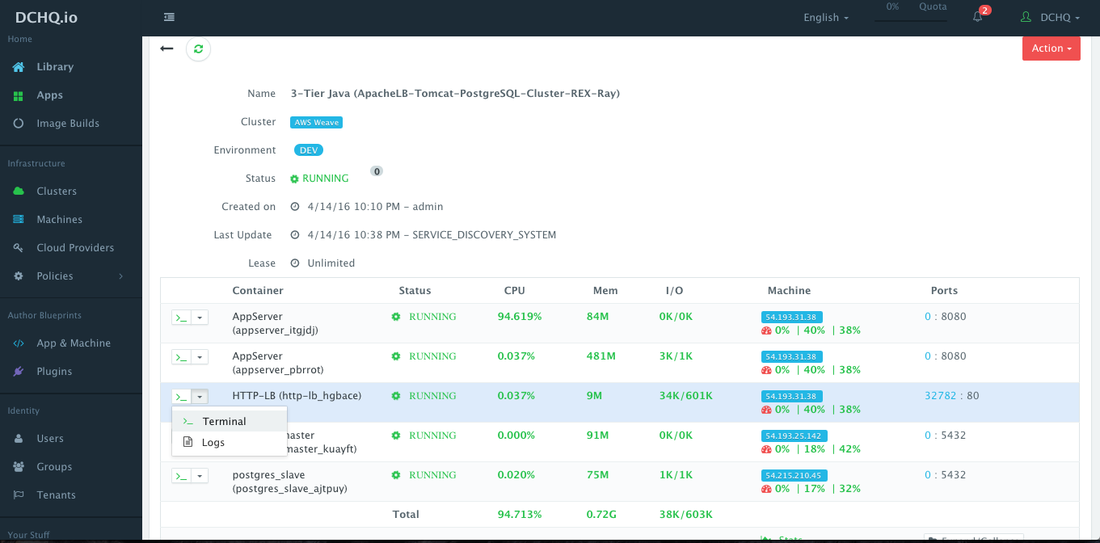
Access An In-Browser Terminal For Containers
A command prompt icon should be available next to the containers’ names on the Live Apps page. This allows users to enter the container using a secure communication protocol through the agent message queue. A white list of commands can be defined by the Tenant Admin to ensure that users do not make any harmful changes on the running containers.
For the httpd container for example, we used the command prompt to make sure that the new container IP was added automatically after the scale out was complete.
Download DCHQ On-Premise Now
- Download DCHQ On-Premise http://dchq.co/dchq-on-premise-download.html
| Reference: | DCHQ + EMC REX-Ray Delivering Container Database Services On Multiple Clouds And Virtualization Platforms from our JCG partner Amjad Afanah at the DCHQ.io blog. |
