Or How I Learned to Stop Worrying and Love the HATEOAS
REST has become the defacto, or at least vogue, solution to implementing web services. This is understandable because REST offers a level of self-documentation in its utilization of the HTTP specification. It’s durable, scalable, and offers several other desirable characteristics.
However many so-called RESTful services don’t implement HATEOAS (Hypermedia As The Engine Of Application State), something which keeps Roy Fielding up at night (if you think the intro is bad, read the comments section). This is an unfortunate trend as including hypermedia controls offers a lot of advantages particularly in the decoupling of the client from the server.
This article, the first in a two-part series, will cover the underlying implementation details and design concerns that govern REST. We’ll discuss how implementing HATEOAS in your RESTful service is worth the additional effort as your service confronts changing business requirements.
Part Two, to be released on March 28th, will be a live code example of implementing a HATEOAS service using Spring-HATEOAS. You can also see some of these concepts in my upcoming talk at the Kansas City Spring User Group on Wednesday, March 2, 2016 titled “How I learned to stop caring and started to love the HATEOAS.”
REST, a triumphant story in the success of architectural constraints
As a developer I had to learn, often with frustration, to work within the constraints imposed upon me by the architects high above. Since recently making the transition to architect, I am now in the position of defining my own constraints and doing my part to continue the cycle of misery. However while researching this article, I learned how the well thought out constraints in the REST architecture are what has lead it to becoming the juggernaut of the web service world. The cycle of misery is abated at least this time.
In his 2000 doctoral dissertation, Roy Fielding defined the six major architectural style constraints governing REST. I’ll be going into detail on five of those; the sixth, code-on-demand, which is optional, will not be covered. The five lucky style constraints are: client-server, stateless, cacheable, uniform interface, and layered architecture.
1. Client-Server
The first style constraint is client-server separation. Ironically, this is the constraint most impacted when developers choose not to implement HATEOAS.
Separation of concerns is one of the fundamental tenets of good system design. In the context of REST and web services, this separation of concerns has some benefits in scalability as new instances of a RESTful service need not also handle the unpacking of a client.
The real benefit, like in all times a separation of concerns constraint is implemented, though is allowing for independent evolvability. The client handles presentation, the server handles storage. The separation means that every change to the server need not necessitate a change to the client (and the need to coordinate a release between the two) and vice versa.
Later in the article we will get into more detail how not implementing HATEOAS blurs the line between client and server.
2. Stateless
If you were to ask a developer what is a key characteristic of a RESTful service, one of the first responses you will likely get is that it is stateless. This is a popular response because statelessness plays a central role in two of RESTs most desirable traits: durability and scalability.
Statelessness in this context means each request contains all the information needed for a server to accept or reject a request, and the server does not need to check a session state to determine the validity of a request. This leads to durability as the client is no longer bound to a specific instance of a service. If a client is talking to instance “A” and it goes down, a load balancer can redirect the client to another available instance and no one is the wiser.
The other benefit, scalability, is achieved because server resources aren’t consumed with storing user state (which, if services are popular enough, could be a very substantial resource drain). It also allows for much faster spinning-up of additional service instances in response to a spike in traffic. That said, achieving that functionality requires a high level of DevOps maturity.
3. Cacheable
The third style constraint is that a request can be cacheable. In this context, cacheability refers to a client’s ability to cache a request. This is as opposed to a server-hosted cache like Redis, though this is enabled in a later constraint. Caching a client request is a feature that has been implemented in every major browser and is activated through the use of http headers as shown in the picture below (cache-control).
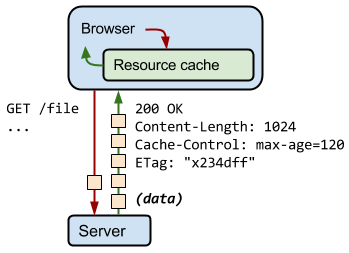
The benefit of having clients cache requests is a decrease to server load by not requiring the server to resupply responses to unchanged and frequently-accessed resources. Also as a browser will be able to retrieve a locally-cached response far more quickly than from the server, there is an improvement to client perceived performance.
4. Uniform interface
A RESTful service’s endpoints are resources. Changes in state occur through manipulation of these resources. Messages sent to these resources are self-descriptive, and hypermedia is the engine of application state (that last constraint sounds familiar).
In the section of the Richardson Maturity Model below, we will walk through what it would look like to implement those four constraints on a service.
5. Layered architecture
Like ogres and onions, REST architecture has layers. A layered architecture in a RESTful service is achieved by the messages sent through it being self-descriptive and each layer not being able to see beyond the interface to the next.
When I submit a request to watch a movie on Netflix, whatever client I am using is going to send a GET request. The request is likely going to hit a routing service. Seeing that it is a GET request (i.e. a retrieval), that routing service may then send that request to a server cache. That cache can check to see if it has a non-expired resource that matches the request’s query. This may continue on for several layers, or even regions within Netflix’s architecture, before my request can be fulfilled. All of this routing and redirection can happen because a REST message is self-descriptive. As long as a layer can understand HTTP, it can understand the message it has received.
The Richardson Maturity Model
So we have covered the five of the six major architectural style constraints that govern REST. Let’s now take a closer look at the fourth style constraint, uniform interface, as previously promised. The uniform interface is what defines a lot of the “look and feel” of RESTful service, it is where an endpoint like: GET: /users/bob is defined. It is also where HATEOAS is defined and that’s the whole point of this article. To give a visualization of the impacts of these constraints as well as see where many RESTful service fall short I will follow the useful Richardson Maturity Model (RMM) as a guide.
The Swamp of POX
This is the level 0 on the RMM. Here a service could in no good faith be described as RESTful. The endpoints our client is interfacing with are not resources, we are not using the correct HTTP verbs in our requests, and the server is not responding back with hypermedia controls. We have all worked on a service like this, indeed it’s possible, though probably not likely, that such a service is easy to use and maintain… but regardless it is definitely not RESTful.
As we go through the RMM, we will be using the interaction of ordering a TV through an online retailer like Amazon to observe how the implementation of the uniform interface constraints in REST impacts the interaction between server and client.
Here we see the interaction at level 0:
POST: viewItem
{
“id”: “1234”
}
Response:
HTTP 1.1 200
{
“id” : 1234,
“description” : “FooBar TV”,
“image” : “fooBarTv.jpg”,
“price” : 50.00
}
POST: orderItem
{
“id” : 1,
“items” : [
“item” : {
“id” : 1234
}
]
}
Response:
HTTP 1.1 200
{
“id” : 1,
“items” : [
“item” : {
“id” : 1234
}
]
}Resources
At this level, level 1 on the RMM, we are implementing the first two constraints of the uniform interface; we are identifying the resources we are interacting with via the URI (/items/1234, /orders/1) and how we interact with the service is through manipulating those resources.
Giving each of our resources a dedicated endpoint instead of a single one provides more identity to the entities our clients are interacting with when sending requests to our service. It also provides opportunities for collecting analytics our how our clients interact with our service. Heat graphs could more easily show which resources and specific entities within that resource that are being requested.
POST: /items/1234
{}
Response:
HTTP 1.1 200
{
“id” : 1234,
“description” : “FooBar TV”,
“image” : “fooBarTv.jpg”,
“price” : 50.00
}
POST: /orders/1
{
“item” : {
“id” : 1234
}
}
Response:
HTTP 1.1 200
{
“id” : 1,
“items” : [
“item” : {
“id” : 1234
}
]
}So now we are hitting resource endpoints instead of anonymous endpoints that all requests will go through. However the nature of our interaction with the service is not clear. When we are POSTing to /items/1234 are we creating a new item or retrieving? When we POST to /orders/1 are we updating an existing entity or creating a new one? These interactions aren’t clear to the client at the time the request is being sent.
HTTP
Up to this point we have been primarily using HTTP as a transport mechanism for our client to interact with our RESTful service. At this level we will begin using the HTTP specification as it has been defined. Thus far we have used POST to submit all our requests, now we will begin using more appropriate HTTP verbs (method types). This isn’t a one-way street however, our server will also respond with more appropriate status codes instead of blithely responding with a 200 status code to every successful request.
The table below lays out the verbs a RESTful service typically implements and some constraints on those verbs. If you are unfamiliar with the term idempotent (the author was), know that it means that the side-effects of the execution of a request are the same when the number of executions is greater than zero.
A GET call should always return the same list of items. A DELETE request should delete the element, but subsequent DELETE requests should result in no change to the server’s state. Note this doesn’t mean the response always has to be the same; in the second example the second DELETE request could return an error response. Safe means the action will have no impact on the server’s state. GET is retrieval only, it will not change the state of the resources it is retrieving. A PUT request however could result in a state change and is thus not a safe verb.
| SAFE | NOT SAFE | |
| IDEMPOTENT | GET, HEAD, TRACE, OPTIONS | DELETE, PUT |
| NOT IDEMPOTENT | POST |
Here is how our interaction looks when we begin using the correct HTTP verbs and status codes in our interactions:
GET: /items/1234
Response:
HTTP 1.1 200
{
“id” : 1234,
“description” : “FooBar TV”,
“image” : “fooBarTv.jpg”,
“price” : 50.00
}
PUT: /orders/1
{
“items” : [
“item” : {
“id” : 1234
}
]
}
Response:
HTTP 1.1 226
{
“items” : [
“item” : {
“id” : 1234
}
]
}Even without having an intimate understanding of the HTTP specification, the interaction between client and server is becoming more clear. We are GETing an item from a server; we are PUTting something on the server. There are some subtitles in which understanding HTTP does help, knowing PUT means modification tells a developer an order already exists and we are modifying it, not creating a new order (that would be a POST request).
Understanding HTTP status codes will also give a developer more understanding on how the server is responding to requests from the client. While our server still returns an appropriate 200 response to our initial GET request, the PUT request the server is now sending a response code of 226 (IM Used) which means only the delta of the changed resource is being returned. If you look at the response to adding an item to an order under the “Resources” section, the server returned the id of the order along with the list of items. In this response, only the item that was added to the order is being returned. If there had been other items already in the order, they too would had been returned in the “resources” response, but omitted in this response.
Alternatively if no item with an id of 1234 exists, instead of returning an empty response body or an error message of some sort, HTTP has already defined a proper response. Can you guess it?
GET: /items/1234 Response: HTTP 1.1 404
Hypermedia Controls
The above scenario of placing an order for a TV offers a good use case to how implementing hypermedia controls would be beneficial. To this point in the scenario, I have assumed the user already has a pre-existing order with an id of “1,” however this might not always be the case.
Without using HATEOAS to convey the state application to the client, the client must be smart enough to determine if an user has an open order, and if so, the id of that order. This creates a duplication of work as business logic determining a user’s state now exists on both the client and server. As business changes, there is a dependency between client and server to determine the state of a user’s order, changes to both client and server code, and the need to coordinate a release between the two. HATEOAS remedies this issue by telling the client the state via the links it returns (i.e. what the client can do next).
GET: /items/1234
Response:
HTTP 1.1 200
{
“id” : 1234,
“description” : “FooBar TV”,
“image” : “fooBarTv.jpg”,
“price” : 50.00,
“link” : {
“rel” : “next”,
“href” : “/orders”
}
}
}
POST: /orders
{
“id” : 1,
“items” : [
{
“id” : 1234
}
]
}
Response:
HTTP 1.1 201:
{
“id” : 1,
“items” : [
{
“id” : 1234
}
]
links : [
{
“rel” : “next”,
“href” : “/orders/1/payment”
},
{
“rel” : “self”,
“href” : “/orders/1”
}
]
}The relative simplicity of determining if an user has an active order might be hand waived as not complex enough to justify the time it would take to implement HATEOAS on the server side and then develop a client that can interpret the hypermedia controls the service produces (neither of which are trivial). That said, this example is also exceedingly simple and representative of only one interaction between client and server.
Death, taxes, and change, the case for HATEOAS
Developers know that the idiom “The only things that are certain are death and taxes” is false, a third is certain: change. Any application that is developed will undergo change over its lifetime; new business requirements are added, existing business requirements are modified, and some business requirements are removed all together.
While I am not promising HATEOAS to be a silver bullet, I do believe it is one of the few technologies whose benefit increases as it encounters real world problems. Below is a sample of three use cases that when taken together, and with others that could be imagined, build a strong case for why you should implement HATEOAS in your RESTful service.
Use case 1: admins and common users interact through the same client
Both common users and admins use the same client to interact with a service. In this use case the common user would only be able to perform a GET on the /items resource, but an admin would also have PUT and DELETE privileges. If we stopped at level 2 on the Richardson Maturity Model (HTTP), we would need to have the client understand the types of privileges a user has in order to properly render the interface to the user.
With HATEOAS it might be as simple as a client rendering some new controls sent by the server. Here is what the differences in the requests might look like. Additionally we probably wouldn’t want admins placing orders for items:
Request:
[Headers]
user: bob
roles: USER
GET: /items/1234
Response:
HTTP 1.1 200
{
“id” : 1234,
“description” : “FooBar TV”,
“image” : “fooBarTv.jpg”,
“price” : 50.00,
“links” : [
{
“rel” : “next”,
“href” : “/orders”
}
]
}
}Request:
[ Headers ]
user: jim
roles: USER, ADMIN
GET: /items/1234
Response:
HTTP 1.1 200
{
“id” : 1234,
“description” : “FooBar TV”,
“image” : “fooBarTv.jpg”,
“price” : 50.00,
“links” : [
{
“rel” : “modify”,
“href” : “/items/1234”
},
{
“rel” : “delete”,
“href” : “/items/1234”
}
]
}
}Use case 2: admins can no longer DELETE
Business requirements change and admins no longer have the ability to DELETE an item. While in the previous use case it is likely a stretch to say no client changes would be needed (for example the admin user would need a form to modify the fields of an item), removing the DELETE verb definitely could be accomplished without change to the client.
With a HATEOAS service no longer returning the DELETE link, the client simply would not display it to the admin user anymore.
Request:
[Headers]
user: jim
roles: USER, ADMIN
GET: /items/1234
Response:
HTTP 1.1 200
{
“id” : 1234,
“description” : “FooBar TV”,
“image” : “fooBarTv.jpg”,
“price” : 50.00,
“links” : [
{
“rel” : “modify”,
“href” : “/items/1234”
}
]
}
}Use case 3: users can sell their own items
Business is now requesting that users have the ability to sell their own user items. This use case, more than the previous two, really begins to show a rapid increase in the amount and complexity of business logic on the client and also introduces a possible coupling between the client and server.
Users can sell their own items, but they should also only be able to only modify the items they put up for sale themselves. User Bob should not be able to modify user Steve’s items and vice versa. A common solution to this issue might be returning a new field within the item entity that specifies ownership, but now we are modifying the item just so our client can properly render the interface to the user not for any business reason.
We are now introducing a coupling between client and server and the line between them is quickly beginning to blur. With a HATEOAS service a lot of this complexity, at least for the client, is removed and our item entity remains unmodified. Below are some sample requests with and without HATEOAS, note how in the HATEOAS example the response looks that same as the response from use case 1.
Without HATEOAS:
Request:
[Headers]
user: jim
roles: USER
GET: /items/1234
Response:
HTTP 1.1 200
{
“id” : 1234,
“description” : “FooBar TV”,
“image” : “fooBarTv.jpg”,
“price” : 50.00,
“owner” : “jim”
}With HATEOAS:
Request:
[Headers]
user: jim
roles: USER
GET: /items/1234
Response:
HTTP 1.1 200
{
“id” : 1234,
“description” : “FooBar TV”,
“image” : “fooBarTv.jpg”,
“price” : 50.00,
“links” : [
{
“rel” : “modify”,
“href” : “/items/1234”
},
{
“rel” : “delete”,
“href” : “/items/1234”
}
]
}
}Summary
While the first style constraint of REST requires a separation of concerns between client and server, this style constraint is being compromised in not implementing HATEOAS. Changes to business logic surrounding how a user’s state is calculated means changes need to be made in both client and server. The independent evolvability of the client and server is lost (releases of client and server must be synchronized) and duplication of business logic reigns. The world needs a little more HATEOAS to remedy this problem.
Bibliography
- http://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-driven
- http://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-driven#comment-745
- https://www.ics.uci.edu/~fielding/pubs/dissertation/rest_arch_style.htm
- http://martinfowler.com/articles/richardsonMaturityModel.html
- https://en.wikipedia.org/wiki/No_Silver_Bullet
- http://www.crummy.com/
- http://www.crummy.com/writing/speaking/2008-QCon/act3.html
| Reference: | Don’t Hate The HATEOAS from our JCG partner Billy Korando at the Keyhole Software blog. |
