DuyHai Doan is an Apache Cassandra Evangelist at DataStax. He spends his time between technical presentations/meetups on Cassandra, coding on open source projects to support the community and helping all companies using Cassandra to make their project successful. Previously he was working as a freelance Java/Cassandra consultant.
In this blog post, we’ll explain the reason why all Cassandra experts and evangelists promote single-partition operations. We’ll see in details all the benefits that single-partition operations can provide in term of operation, consistency and system stability.
Atomicity & Isolation
Mutations (INSERT/UPDATE/DELETE) to all columns of a partition are guaranteed to be atomic e.g. the update of N columns in the same row are considered as a single write operation.
This atomicity property is important because it guarantees the clients that either all the mutations are applied or none is applied.
Multiple partitions mutations cannot provide atomicity right now (at least until CASSANDRA-7056 “RAMP Transaction” is done). Atomicity on multiple partitions would require either setting a coordination system (like global lock) or sending extra meta data like in RAMP Transaction.
Also, mutations to single partition are isolated on a replica e.g. until client1 finishes writing the mutations, another client2 won’t be able to read them. Multiple partitions cannot be applied in isolation for the same reasons as mentioned above.
Batch
We technical evangelists used to rant about LOGGED BATCHES. Misuse of batches can lead to node failure and harm system stability.
Below is what happens when you’re sending a logged batch with mutations to multiple partitions:
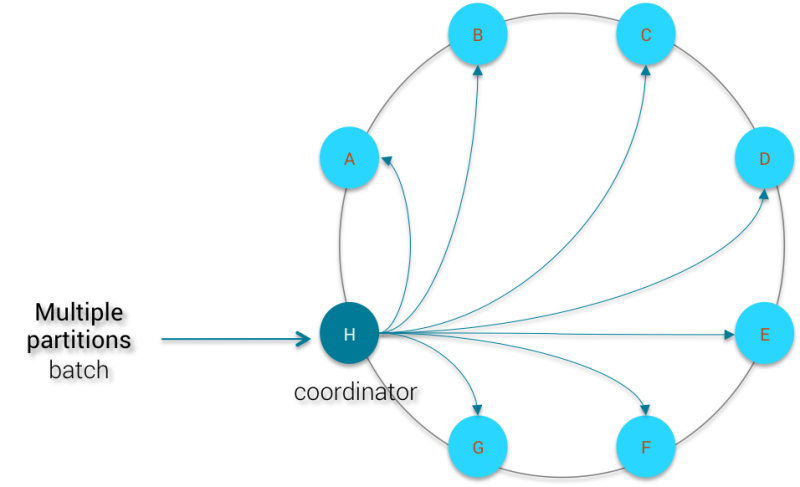
By virtue of high distributivity, the Murmur3 partitioner will distribute evenly the each partition all over the cluster. Consequently the coordinator node will have to wait for N nodes (N = number of distinct partition keys in the logged batch, to simplify) in the cluster to acknowledge for the mutations before removing the locally-stored logged batch. The logged batch cannot be removed from the coordinator until the all N nodes send back an ack. With a cluster of 100 nodes, this logged batch will greatly impact the stability of the coordinator.
Now, let’s see how the coordinator can deal with single partition logged batch:
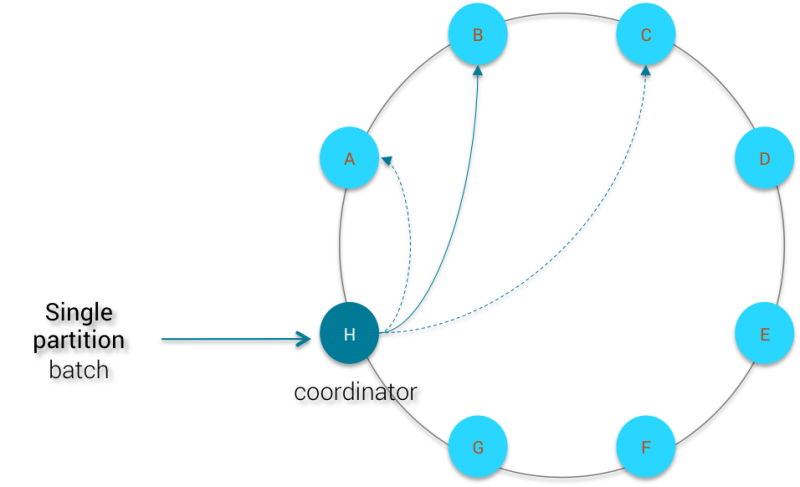
The mutations are sent to all replica nodes and the coordinator waits for RF acknowledgements (RF = replication factor) before removing the logged batch. In this case, the size of your cluster does not matter because the number of nodes involved by the batch is bound to the replication factor.
Secondary Index
Secondary index in Cassandra is an useful feature but very hard to use correctly for 2 main reasons:
- secondary indices do not scale very well with the cluster size.Indeed the indices are distributed with the base data so querying using these indices will require hitting at least N/RF nodes in the cluster, N being the total number of node in the cluster/datacenter and RF being the replication factor.As an example, if you have a 100 nodes cluster with RF = 3, querying with secondary index will likely hit 34 nodes (100/3 rounded up to 34).
- very high cardinality and very low cardinalities.Imagine you have a table user with the gender column. The table primary key is user_id. You want to be able to find user by their gender so it is tempting to create a secondary index on this column. However, since there are only 2 possible values for gender, on each node, all the users will be spread between only 2 wide partitions (MALE & FEMALE).Another example is to create a secondary index on user’s email to be able to find them by their email. The problem is that for 1 user, there is at most 1 distinct email (it’s rare that 2 users have the same email address). So when issuing a query like:
SELECT * FROM users WHERE email='doanduyhai@nowhere.com';
Cassandra will hit N/RF nodes to only retrieve 1 row at most, and sometimes there is no result at all. So the cost to pay for finding just 1 row is quite prohibitive
The only good and scalable use-case for secondary index is when you restrict your query to a single partition. Let’s say we have the following schema to store sensor data:
CREATE TABLE sensors( sensor_id uuid, date timestamp, location text, value double, PRIMARY KEY(sensor_id, date) ); CREATE INDEX location_idx ON sensors(location); CREATE INDEX value_idx ON sensors(value);
We created above 2 indices for the sensors to query by sensor location and sensor value. The following queries will be performant and scalable because we provide everytime the partition key (sensor_id) so Cassandra will not hit N/RF nodes and only searches data from a single node.
//Give all values of my sensor when it is in Los Angelest SELECT value FROM sensors WHERE sensor_id='de305d54-75b4-431b-adb2-eb6b9e546014 ' AND location='Los Angeles'; //Give me the moment and the location of my sensor when it has value 4.5 SELECT date,location FROM sensors WHERE sensor_id='de305d54-75b4-431b-adb2-eb6b9e546014 ' AND value=4.5;
LightWeight Transactions
LightWeight Transactions (LWT) have been introduced in Cassandra 2.0 to solve a class of problem that would require otherwise an external lock manager.
Under the hood, Cassandra is implementing the Paxos protocol to guarantee linearizability of the mutations. It is similar to a distributed Compare and Swap operation.
With LWT, you can simulate integrity constraints with INSERT INTO … IF NOT EXISTS and DELETE … IF EXISTS. Obviously, those 2 operations are single partition.
It is also possible to have conditional update using LightWeight Transactions with the syntax UPDATE … SET col1 = xxx WHERE partition_key = yyy IF col2 = zzz;, the only constraint is that the conditional column to be checked should belong to the same row (so same partition) as the column to be updated.
Similarly, you can issue a batch statement containing one LWT mutation provided that all other mutations are using the same partition key than the one using LWT. Example
CREATE TABLE stock_order (
order_id uuid,
order_state static text, // OPEN or CLOSED
item_id int,
item_amount double,
PRIMARY KEY (order_id, item_id)
);
// Batch insert new items into the given order and close it
BEGIN LOGGED BATCH
INSERT INTO stock_order(order_id,item_id,item_amount) VALUES('de305d54-75b4-431b-adb2-eb6b9e546014
', 5, 460000.0);
INSERT INTO stock_order(order_id,item_id,item_amount) VALUES('de305d54-75b4-431b-adb2-eb6b9e546014
', 6, 50000);
INSERT INTO stock_order(order_id,item_id,item_amount) VALUES('de305d54-75b4-431b-adb2-eb6b9e546014
', 7, 1200000);
UPDATE stock_order SET order_state='CLOSED' WHERE order_id='de305d54-75b4-431b-adb2-eb6b9e546014
' IF order_state='OPEN';
END BATCHIn the above example, if the given order is already closed by some other processes, the conditional update (IF order_state=’OPEN’) will fail so none of the insert will be executed. That’s one of the great features of LWT. It gives you a strong linearizability guarantee for your operations.
If you were to distribute those order updates and mutations across different partitions, LWT won’t be applicable and you will fall back into the world of eventual consistency.
User Defined Aggregates
Last but not least, the recently released feature of User Defined Aggregates (UDA) works best on single partition. Without digging to much into the technical details, you should know that aggregate functions in Cassandra are applied on the coordinator node, after the last-write-win reconciliation logic.
Thus, executing an aggregation on multiple partitions or on the whole table would requires that the coordinator fetches all the data (using internal paging indeed) from different nodes before applying the UDA. In this case, the latency of the aggregation query is bound to the latency of the slowest node. Furthermore, multiple partitions aggregation requires fetching more data and thus can increase greatly the query duration.
For all those reasons, the current recommendation is to reserve UDA only for single partition and to rely on Apache Spark if you where to aggregate and entire table or several partitions.
For more details about UDA, you can read those blog posts:
| Reference: | The importance of single-partition operations in Cassandra from our JCG partner DuyHai Doan at the Planet Cassandra blog. |
