In 2015, General Stan McChrystal published Team of Teams, New Rules of Engagement For a Complex World. It was the culmination of his experience in adapting to a world that had changed faster than the organization that he was responsible to lead. When he assumed command for the Joint Special Operations Task Force in 2003, he recognized that their typical approaches to communication were failing. The enemy was a decentralized network that could move very quickly and accordingly, none of his organizations traditional advantages (equipment, training etc) mattered.
He saw the need to re-organize his force as a network, combining transparent communication with decentralized decision-making authority. Said another way, decisions should be made at the lowest level possible, as quickly as possible, and then, and only then, should data flow back to a centralized point. Information silos were torn down and data flowed faster, as the organization became flatter and more flexible.
Observing that the world is changing faster than ever, McChrystal recognized that the endpoints were the most valuable and the place that most decision making should take place. This prompted the question:
What if you could combine the adaptability, agility, and cohesion of a small team with the power and resources of a giant organization?
As I work with organizations around the world, I see a similar problem to the one observed by General McChrystal:
data and information are locked into an antiquated and centralized model. The impact is that the professionals in most organizations do not have the data they need, in the moment it is required, to make the optimal decision. Even worse, most investments around Big Data today are not addressing this problem, as they are primarily focused on reducing the cost of storage or simply augmenting traditional approaches data management. Enterprises are not moving along the Big Data maturity curve fast enough:
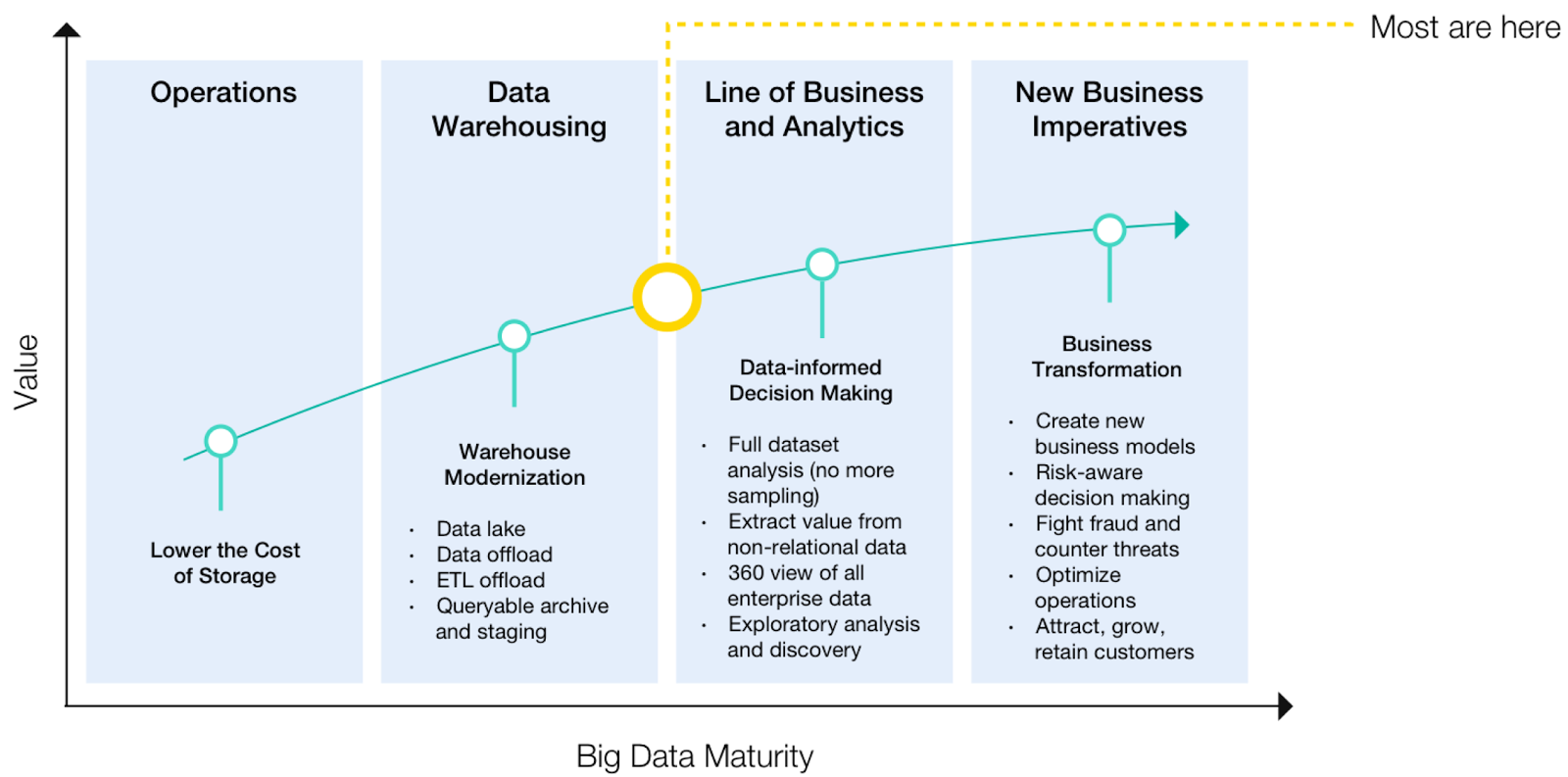
While its not life or death in most cases, the information crisis in organizations is reaching a peak. Companies have not had a decentralized approach to analytics, to complement their centralized architecture. Until now.
Today, we are announcing Quarks. An open source, lightweight, embedded streaming analytics runtime, designed for edge analytics. It can be embedded on a device, gateway, or really anywhere, to analyze events locally, on the edge. For the first time ever, analytics will be truly decentralized. This will shorten the window to insights, while reducing communication costs by only sending the relevant events back to a centralized location. What General McChrystal did to modernize complex field engagements, we are doing for analytics in the enterprise.
While many believe that the Internet of Things (IoT) may be over-hyped, I would assert the opposite; we are just starting to realize the enormous potential of a fully connected world. A few data points:
- $1.7 trillion of value will be added to the global economy by IoT in 2019. (source: Business Insider)
- The world will grow from 13 billion to 29 billion connected devices by 2020. (source: IDC)
- 82% of enterprise decision makers say that IoT is strategic to their enterprise. (source: IDC)
- While exabytes of IoT data are generated every day, 88% of it goes unused. (Source: IBM Research)
Despite this obvious opportunity, most enterprises are limited by the costs and time lag associated with transmitting data for centralized analysis. To compound the situation, data streams from IoT devices are complex, and there is little ability to reuse analytical programs. Lastly, 52% of developers working on IoT are concerned that existing tools do not meet their needs (source: Evans Data Corporation). Enter, the value of open source.
Quarks is a programming model and runtime for analytics at the edge. It includes a programming SDK, a lightweight and embeddable runtime, and is open source (incubation proposal), available on GitHub.
This gives data engineers what they want:
- Easy access to IoT data streams
- Integrated data at rest with IoT data streams
- Curated IoT data streams
- The ability to make IoT data streams available for key stakeholders
This gives data developers what they want:
- Access to IoT data streams through APIs
- The ability to deploy machine learning, spatial temporal and other deep analytics on IoT data streams
- Familiar programming tools like Java or Python to work with IoT data streams
- The ability to analyze IoT data streams to build cognitive applications
Analytics at the edge is finally available to everyone, starting today, with Quarks. And, the use cases are extensive. For example, in 2015, Dimension Data became the official technology partner for the Tour de France, the worlds largest and most prestigious cycling race.

In support of their goal to revolutionize the viewing experience of billions of cycling fans across the globe, Dimension Data leveraged IBM Streams to analyze thousand of data points per second, from over 200 riders, across 21 days of cycling.

The potential of embedding Quarks in connected devices, on the network edge (essentially on each bike) would enable a new style of decentralized analytics: detecting in real-time, critical race events as they happen (a major rider crash for example), rather than having to infer these events from location and speed data alone. With the ability to analyze data at the end point, that data stream can then be integrated with Kafka, etc. and moved directly into Hadoop for storage or Spark for analytics. This will drive analytics at a never before seen velocity in enterprises.
We live in a world of increasing complexity and speed. As General McChrystal described, organizations that rely solely on centralized architectures for decision making and information flow will fail. At IBM, we are proud to lead the decentralization of analytics, complementing centralized architectures, as a basis for Cognitive Computing.
| Reference: | Decentralized Analytics for a Complex World from our JCG partner Rob Thomas at the Rob’s Blog blog. |
