Let’s have some fun.
It’s the start of a new year — we’re on the threshold of something new — so let’s look forward to what you’re likely to be doing in 2016. Now I know the riskiness of making predictions – especially ones on record – but I’m happy for you to drop back by in a year from now and see how my projections for 2016 pan out.
What will you do in 2016?
Before I make my 2016 predictions, first think more generally (and playfully) about the challenge of speculating on what the future will be. Do we work from data and models? From observation and hunch? And remember that the accuracy of describing the future lies in part on how long into the future the target is.
It’s tradition to project distantly future views of what people’s lives will be. Sometimes they are accurate and more often hilariously wrong. Looking back at what the future was supposed to be is an entertainment I call “remembering the future”.
For example, the year 2000 caught people’s imagination for many years. I came across an essay published in the year 1900 in Ladies Home Journal with predictions for what our lives would be like in 2000. Among the predictions that were roughly correct were that motor cars would become numerous, photographs could be telegraphed from distant countries such that they could be printed in newspapers within an hour and that the US population would reach over 350 million including territories (the 2000 census put the US population at 282 million, a bit short). Much less accurate were predictions that there would be no more flies or mosquitos, through-traffic in cities would be underground or overhead such that cities would be “free from noise” and that we would have ceased to use the letters C, X or Q.
The future did not turn out as described, but partly because we often solve the same problems in a different way than predicted: today traffic is shunted through cities on freeways, but — alas — that does not eliminate noise. And instead of normalizing spelling by “firing” certain consonants, we rely on automated spell-correct systems (sometimes with laughable results).
Back to Big Data
This idea of “remembering the future” was a theme picked up in a lively presentation by Ted Dunning on current and future big data trends at a Big Data Singapore meet-up during the week of the Strata Hadoop World conference in that city. Also touching on the idea of where big data systems are going in the near future was another presenter, Hadoop founder Doug Cutting.

Doug talked about the evolution of the Hadoop ecosystem particularly with regard to analytics. Batch-based computation is giving way in many cases to in-memory micro-batched computational capabilities, hence the widespread and growing interest in Apache Spark.
Ted first entertained people with cultural trends that did not turn out as predicted before he described a successful, forward looking, big data project – an open source project from the 19th century that made good use ocean and wind data to build navigational charts for sailing. Jumping to the present day, Ted explained the current big data trend toward simplification in machine learning projects such that they deliver practical value. Ted also talked about the need for more streamlined ways to handle complex data to avoid having to build hundreds of tables (as was true with traditional relational systems) and he showed the advantage of leveraging the flexibility of SQL engine Apache Drill in these situations.
Six Predictions for 2016
Inspired by others who have described big data trends, now I’ll stick out my neck to make my own predictions (purely opinion) about what you’ll be doing in 2016. After all, it’s only one year in the future…
Streaming Data
I feel confident that throughout 2016 there will be explosive interest in streaming data and streaming analytics. Streaming data will be used by many more organizations than previously and in new ways. Increasing volume in IoT sensor data is just one of the sources of streaming data. Series of events – such as clickstream data from web traffic or machine log files – will increasingly be analyzed as streams, using near-real time processing with Apache Spark or actual real time analytics with a newer tool, Apache Flink.
One of the big shifts will be a different way to think of the architecture that best supports these applications: The message queue will become a central focus in designing these systems. The messaging layer will be much more than just a safety buffer in the workflow of a streaming analytic program. Done right, the message queue becomes a re-playable, immutable persistent log that serves multiple masters such as real time analytics applications, databases or search documents. For these reasons, I predict a greatly increased use of the already popular messaging tool Apache Kafka as well as strong interest in new MapR Streams, an integrated messaging technology that supports the Kafka API.
Shorter Time-to-Value
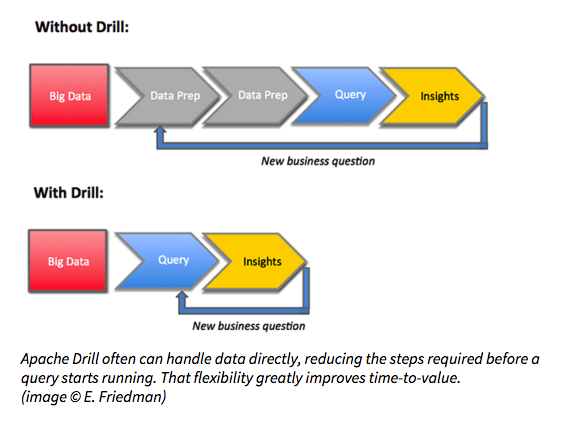
Businesses want practical ways to get to value faster, so I believe you are likely to try out Apache Drill some time in 2016 if your business has any need for SQL. With more frequent releases, Drill’s capabilities continue to expand, but it’s already a highly performant, highly scalable and extremely flexible query engine that uses standard SQL. This makes it equally attractive to people coming to big data from a traditional background as well as veterans of the Hadoop and NoSQL world who want a query engine that easily handles a wider variety of unstructured and nested data types, such as JSON and Parquet.
Perhaps the characteristic of Drill that is most likely to make you want to try it is its ability to query data with little or no preparation – that can cut hours or days off the time needed to go from data to insights. With less time needed before you start your query, with Drill you’re able to quickly build a second query based on what you’ve learned from the first one. Faster development, faster insights, shorter time-to-value.
Centralization
Increasingly people will think of the big data platform as a central part of their overall organization rather than a special purpose project. A big data platform such as an Hadoop and NoSQL based system will need to be easily connected to traditional technologies such as an enterprise data warehouse, relational data base or BI tools.
A paradoxical aspect of centralization for a global organization is the need to globally distribute data. Different parts of your organization need access to unified data sets. As you break down unwanted silos within or between geographically distinct centers, you’ll want to avoid propagation delays. There may be legal issues that require localization of data. For these reasons, I predict many organizations will want a system with secure and reliable ways to maintain multiple data centers that can be quickly synchronized.
Special Topics: Healthcare
I think the use of big data in the health care industry is poised for rapid expansion in 2016. People are recognizing the power of using data to reduce fraud and improve healthcare delivery through the use of electronic patient histories, long-term maintenance records for machinery, and the flow of sensor information. Excellent data security and governance will of course be important for these use cases.
Special Topics: Telecommunications
Another area that will increasingly stand out in the big data space in 2016 is telecommunications. Telecom companies already have excellent use cases for big data: offloading the strain of ETL to Hadoop while maintaining complex billing on enterprise warehouses; using anomaly detection on data to and from cell towers to discover and quickly respond to sudden usage shifts, and employing real time analytics to respond quickly users after a dropped call in order to improve experience and reduce churn.
Expansions in streaming data architectures and technologies (described above) will benefit telecoms. But even if you are not working with a telecom yourself, this special case may still affect you. More non-phone applications are making use of telecom networks. Sensors in cars, for instance, often send data via a telecommunications network. Taking all that together, I predict you will likely be combining advanced telecommunications with big data in 2016.
The Best Prediction: You’ll Surprise Me
And my best prediction for 2016 is that you will come up with some innovative way to put big data to use that has not yet occurred to me. Maybe it will solve a problem I’m already aware of but in a novel way. Or maybe it will be something entirely new. Either way, by January 2017 I’ll be “remembering the future” as I saw it and be surprised by something new, even if my other five predictions turn out to be accurate.
Other Resources
For related content by the author see these free resources:
- Practical Machine Learning: A New Look at Anomaly Detection
- Real World Hadoop
- Article on Apache Drill on the O’Reilly Radar blog
| Reference: | What Will You Do in 2016? Apache Spark, Kafka, Drill and More from our JCG partner Ellen Friedman at the Mapr blog. |
