Ivan Linhares is an Engineering Manager at Chaordic. He has been working as a lead engineer and software developer for more than fifteen years. He is passionate for developing great teams and solving challenging technical problems. At Chaordic, he leads the Data Platform team in scaling its personalization solution for the e-commerce sector.
Chaordic is the leader in big data based personalization solutions for e-commerce in Brazil. The largest online retailers in the country, such as Saraiva, Walmart and Centauro use our solutions to suggest personalized shopping recommendations to their users. Chaordic’s Data Platform provides a common data layer and services shared among multiple product offerings.
Three years ago Chaordic was experiencing an exponential growth. From the beginning, our business was based in gathering as much as relevant information as we could collect. I’ve joined the company when the core database solution – MySQL – was struggling to keep the pace of growth. By that time, it was not so clear which solution would take the lead in the hyped NoSQL front. Although today we use a hybrid data architecture, Cassandra was a key technology to enable sustained growth for Chaordic.
Phase 1: Finding the Sweet Spot
Some modern data store solutions favor being easy to use, others provide an integrated environment with MapReduce or Search, and others invest in performance and data consistency (see CAP theorem). So finding the sweet spot for a technology matching our use case was the first step.
As we considered the challenges we were facing at that moment, many things became clearer:
- Vertically scaling the database had hit the ceiling: we had the largest AWS instance by the time and it was not enough for our master-slave deploy.
- We wanted to avoid manual sharding of data and the complexity of rebalancing cluster data.
- Growing and doubling our capacity should be something straightforward and quick.
- The data store should fit well to our write intensive pattern.
- Downtimes, even scheduled, should be avoided and challenging SLAs adopted.
- Proprietary data storages and provider-specific technologies should also be avoided.
- Schema changes needed to be less painful: long maintenance operations (e.g., ALTER TABLE) were already limiting us.
As we pondered these factors and benchmarked among other players at the time, the choice of Cassandra was natural for our scenario. The balance of linear scalability, write optimizations, ease of administration, tunable consistency and a growing community made the difference. The momentum for Cassandra by the time (including Netflix early adoption) and of course our natural instinct to try new stuff were also important.
Phase 2: Learning by Doing
We decided the most logical way was to migrate incrementally from MySQL. There were many uncertainties in the process, different ways of modeling, and so much to learn. We began by setting up a 6 nodes, single zone Cassandra cluster and migrating the most performance sensitive entities first.
Our strategy included a way to move the migration forward, as well as a way to rollback if things went wrong; this proved to be very effective, as we were still learning the best ways to represent our data in Cassandra. Our platform was already designed with REST APIs, so internal clients would not be affected by the migration. Our tiered architecture demanded only to implement a new Cassandra Data Access Object for each entity and in some cases adapt the business logic.
Understanding how to model efficiently in Cassandra was a step-by-step process. One of the common mistakes was to cause load hotspots in the cluster. Cassandra load balances data distribution based on consistent key hashing. So, by doing a poor choice of partition keys – i.e. a single key for all the products of your biggest client – the load would be concentrated in the same replica group and these particular nodes would be saturated. Primary keys in Cassandra should be chosen considering a partitioning that balances data distribution and clustering of columns. Clustering keys, on the other hand, enables the retrieval of rows very efficiently and is also used to index and sort data.
Cassandra’s well-known limitation with secondary indexes is something we learned the hard way. If you read the docs, the benefits may catch your attention. They work pretty well with low cardinality data, but in many situations this won’t be the case. When we migrated one of our main entities to take advantage of that, to create a list of products by client, performance decreased and we had to rollback. The solution was to create a new table (or a Materialized View) to each desired query and manage updates in the application layer. The good news is that Cassandra 3.0 will support this built in.
Another mistake we did was to use the same table to store different entities, back when there was no table schema. On the 0.8 times there was a myth recommendation to avoid using too many tables, so we reused some tables to store rows in different storage formats, in particular wide and skinny partitions. This ended up messing with page caching and other storage optimizations. Modeling data in CQL as of today already prevents you from this bad practice, but pre-CQL this was not so clear. The advice is that mixing different entities or read/write patterns in the same table is generally not a good idea.
Phase 3: Optimizing for Operations
In case your cluster size is quickly evolving, it is very important to master Cassandra operations: automating the process of node replacement and addition will save you a lot of time. We started with Puppet and then moved to Chef to automate node provisioning. When the cluster gets reasonably big enough, it is also imperative to automate rolling restarts to do configurations tuning and version upgrades.
Understanding Cassandra specificities such as repairs, hinted handoff and clean ups is also key to maintain data consistency. For example, once we got zombie data in our cluster because deletions (see tombstones) were not replicated when a node was down for longer than gc_grace_seconds and data eventually reappeared; a repair operation could have fixed that.
As we grew in developing new products, we had to decide between staying with a monolithic cluster or deploying a new one. We decided that the latter was a better option to enable experimentation and modularity. We then rolled our cluster with a newer version of Cassandra (1.2 at the time) enabling virtual nodes. We started with spinning disk based nodes, but quickly migrated to new SSD backed instances. This last step, reduced write latency to 50% and read latency got 80% better, even using fewer machines to compensate costs! Better yet, it allowed us to take Memcached out of the stack, reducing costs and complexity, specially in multi region deploys (see benchmark here).
Another critical aspect for performance in Cassandra is choosing the right Compaction Strategy. Since Cassandra writes to disk are immutable (SSTables), data updates accumulate in new SSTables files. This gives excellent write performance, but reading data that is not sequentially stored on disk implies multiple disk seeks and performance penalty. To overcome that, the compaction process merges and combines data, evicts tombstones and consolidates SSTables in new merged files. We started with the default SizeTieredCompactionStrategy (STCS), which works pretty well for write intensive workloads. For cases where reads are more frequent and data is frequently updated, we migrated to LeveledCompactionStrategy (LCS). In many cases, this helped removing tombstones faster and reducing the number of SSTables per read, hence, improving read latency (see bellow).
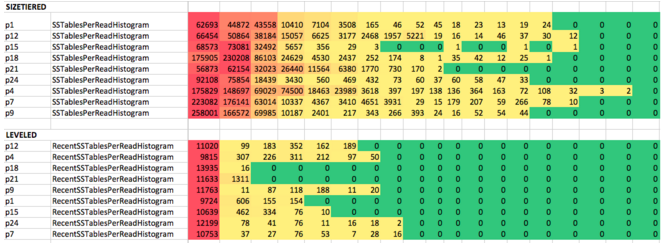
Configuring compression also has a huge impact in storage space. For archival or infrequently read data, Deflate compression saved us 60-70% percent of disk space. For some use cases (see here), compression may even improve read performance, due to reduced IO time.
For monitoring, it doesn’t matter which tool you use (Librato, OpsCenter, Grafana, etc.), as long as you are comfortable with and you do the homework of understanding and watching key metrics. Cassandra is built with extensive instrumentation based on JMX. In our experience, sticking with fewer time-based metrics, coherently organized in dashboards where you can easily spot anomalies, is much more important than having all the metrics. A selection of key metrics will include the more general ones (latencies, transactions per second), as well as system metrics (load, network i/o, disk, memory), JVM metrics (heap usage, gc times), and deeper to Cassandra specifics. For compactions, look for PendingTasks and TotalCompactionsCompleted; Read/WriteTimeouts and Dropped Mutations will normally anticipate capacity issues; Exceptions.count to spot general errors and TotalHints and RepairedBackground will help diagnose inconsistencies.
Keeping the Pace
Thanks to the vibrant community and Datastax commitment to frequent releases, even minor Cassandra upgrades may surprise with performance improvements, features and configuration tweaks. So we advise to keep the cluster upgraded to a recent stable version. A rule of thumb to choose the best stable version to upgrade is to watch the latest DataStax Enterprise’s Cassandra version.
This post gave an overview of how the Data Platform team at Chaordic adopted Cassandra and supported the company’s growth. Overcoming the initial barrier of adopting a non-relational database may not be easy, but it is well worth the investment to gain in a robust and scalable solution.
* Special thanks to DataStax Engineer Paulo Motta and Chaordic Engineer Flavio Santos for contributing and reviewing this article.
| Reference: | Transitioning from MySQL to Cassandra at Chaordic from our JCG partner Ivan Linhares at the Planet Cassandra blog. |
