We’re very happy to announce a guest post series on the jOOQ blog by Manuel Bernhardt. In this blog series, Manuel will explain the motivation behind so-called reactive technologies and after introducing the concepts of Futures and Actors use them in order to access a relational database in combination with jOOQ.
 Manuel Bernhardt is an independent software consultant with a passion for building web-based systems, both back-end and front-end. He is the author of “Reactive Web Applications” (Manning) and he started working with Scala, Akka and the Play Framework in 2010 after spending a long time with Java. He lives in Vienna, where he is co-organiser of the local Scala User Group. He is enthusiastic about the Scala-based technologies and the vibrant community and is looking for ways to spread its usage in the industry. He’s also scuba-diving since age 6, and can’t quite get used to the lack of sea in Austria.
Manuel Bernhardt is an independent software consultant with a passion for building web-based systems, both back-end and front-end. He is the author of “Reactive Web Applications” (Manning) and he started working with Scala, Akka and the Play Framework in 2010 after spending a long time with Java. He lives in Vienna, where he is co-organiser of the local Scala User Group. He is enthusiastic about the Scala-based technologies and the vibrant community and is looking for ways to spread its usage in the industry. He’s also scuba-diving since age 6, and can’t quite get used to the lack of sea in Austria.
This series is split in three parts, which we’ll publish over the next month:
- Part 1: Introduction to Futures, “Why async”, connection pool configuration
- Part 2: Introduction to Actors
- Part 3: Using jOOQ with Scala, Futures and Actors
Reactive?
The concept of Reactive Applications is getting increasingly popular these days and chances are that you have already heard of it someplace on the Internet. If not, you could read the Reactive Manifesto or we could perhaps agree to the following simple summary thereof: in a nutshell, Reactive Applications are applications that:
- make optimal use of computational resources (in terms of CPU and memory usage) by leveraging asynchronous programming techniques
- know how to deal with failure, degrading gracefully instead of, well, just crashing and becoming unavailable to their users
- can adapt to intensive workloads, scaling out on several machines / nodes as load increases (and scaling back in)
Reactive Applications do not exist merely in a wild, pristine green field. At some point they will need to store and access data in order to do something meaningful and chances are that the data happens to live in a relational database.
Latency and database access
When an application talks to a database more often than not the database server is not going to be running on the same server as the application. If you’re unlucky it might even be that the server (or set of servers) hosting the application live in a different data centre than the database server. Here is what this means in terms of latency:
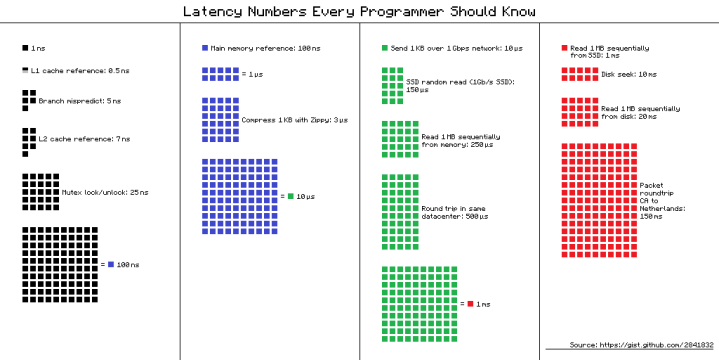
Say that you have an application that runs a simple SELECT query on its front page (let’s not debate whether or not this is a good idea here). If your application and database servers live in the same data centre, you are looking at a latency of the order of 500 µs (depending on how much data comes back). Now compare this to all that your CPU could do during that time (all those green and black squares on the figure above) and keep this in mind – we’ll come back to it in just a minute.
The cost of threads
Let’s suppose that you run your welcome page query in a synchronous manner (which is what JDBC does) and wait for the result to come back from the database. During all of this time you will be monopolizing a thread that waits for the result to come back. A Java thread that just exists (without doing anything at all) can take up to 1 MB of heap memory, so if you use a threaded server that will allocate one thread per user (I’m looking at you, Tomcat) then it is in your best interest to have quite a bit of memory available for your application in order for it to still work when featured on Hacker News (1 MB / concurrent user).
Reactive applications such as the ones built with the Play Framework make use of a server that follows the evented server model: instead of following the “one user, one thread” mantra it will treat requests as a set of events (accessing the database would be one of these events) and run it through an event loop:
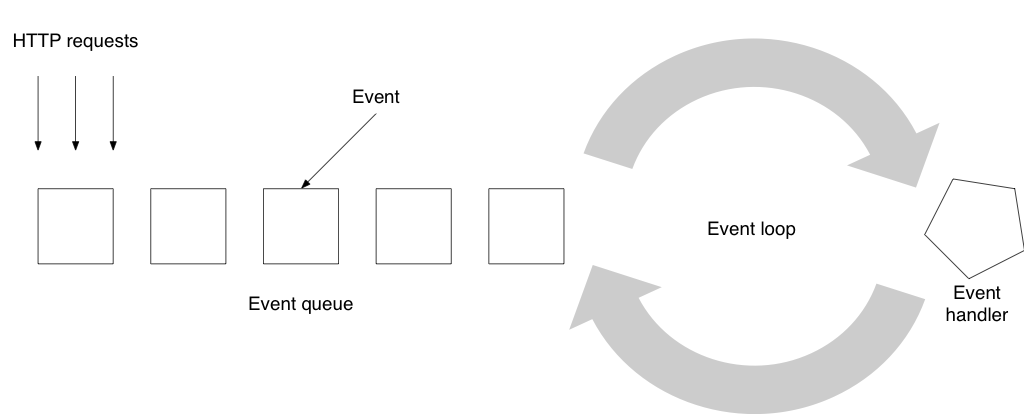
Such a server will not use many threads. For example, default configuration of the Play Framework is to create one thread per CPU core with a maximum of 24 threads in the pool. And yet, this type of server model can deal with many more concurrent requests than the threaded model given the same hardware. The trick, as it turns out, is to hand over the thread to other events when a task needs to do some waiting – or in other words: to program in an asynchronous fashion.
Painful asynchronous programming
Asynchronous programming is not really new and programming paradigms for dealing with it have been around since the 70s and have quietly evolved since then. And yet, asynchronous programming is not necessarily something that brings back happy memories to most developers. Let’s look at a few of the typical tools and their drawbacks.
Callbacks
Some languages (I’m looking at you, Javascript) have been stuck in the 70s with callbacks as their only tool for asynchronous programming up until recently (ECMAScript 6 introduced Promises). This is also knows as christmas tree programming:

Threads
As a Java developer, the word asynchronous may not necessarily have a very positive connotation and is often associated to the infamous synchronized keyword:
95% of syncronized code is broken. The other 5% is written by Brian Goetz. – Venkat Subramaniam at #s2gx
— Ronny Løvtangen (@rlovtangen) October 26, 2011
Working with threads in Java is hard, especially when using mutable state – it is so much more convenient to let an underlying application server abstract all of the asynchronous stuff away and not worry about it, right? Unfortunately as we have just seen this comes at quite a hefty cost in terms of performance.
And I mean, just look at this stack trace:
In one way, threaded servers are to asynchronous programming what Hibernate is to SQL – a leaky abstraction that will cost you dearly on the long run. And once you realize it, it is often too late and you are trapped in your abstraction, fighting by all means against it in order to increase performance. Whilst for database access it is relatively easy to let go of the abstraction (just use plain SQL, or even better, jOOQ), for asynchronous programming the better tooling is only starting to gain in popularity.
Let’s turn to a programming model that finds its roots in functional programming: Futures.
Futures: the SQL of asynchronous programming
Futures as they can be found in Scala leverage functional programming techniques that have been around for decades in order to make asynchronous programming enjoyable again.
Future fundamentals
A scala.concurrent.Future[T] can be seen as a box that will eventually contain a value of type T if it succeeds. If it fails, theThrowable at the origin of the failure will be kept. A Future is said to have succeeded once the computation it is waiting for has yielded a result, or failed if there was an error during the computation. In either case, once the Future is done computing, it is said to be completed.
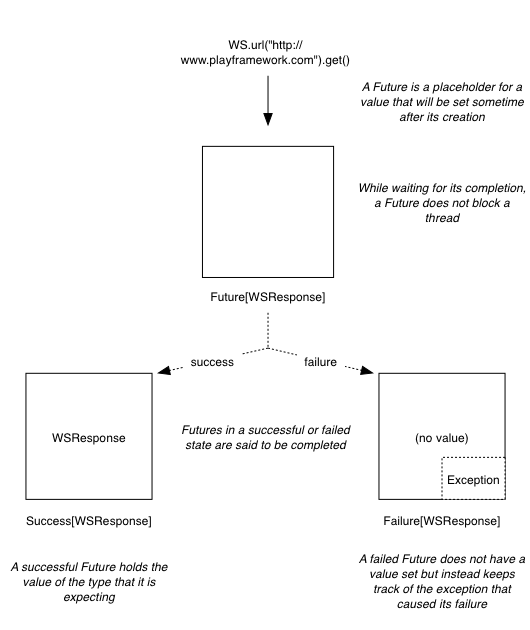
As soon as a Future is declared, it will start running, which means that the computation it tries to achieve will be executed asynchronously. For example, we can use the WS library of the Play Framework in order to execute a GET request against the Play Framework website:
val response: Future[WSResponse] =
WS.url("http://www.playframework.com").get()This call will return immediately and lets us continue to do other things. At some point in the future, the call may have been executed, in which case we could access the result to do something with it. Unlike Java’s java.util.concurrent.Future<V>which lets one check whether a Future is done or block while retrieving it with the get() method, Scala’s Future makes it possible to specify what to do with the result of an execution.
Transforming Futures
Manipulating what’s inside of the box is easy as well and we do not need to wait for the result to be available in order to do so:
val response: Future[WSResponse] =
WS.url("http://www.playframework.com").get()
val siteOnline: Future[Boolean] =
response.map { r =>
r.status == 200
}
siteOnline.foreach { isOnline =>
if(isOnline) {
println("The Play site is up")
} else {
println("The Play site is down")
}
}In this example, we turn our Future[WSResponse] into a Future[Boolean] by checking for the status of the response. It is important to understand that this code will not block at any point: only when the response will be available will a thread be made available for the processing of the response and execute the code inside of the map function.
Recovering failed Futures
Failure recovery is quite convenient as well:
val response: Future[WSResponse] =
WS.url("http://www.playframework.com").get()
val siteAvailable: Future[Option[Boolean]] =
response.map { r =>
Some(r.status == 200)
} recover {
case ce: java.net.ConnectException => None
}At the very end of the Future we call the recover method which will deal with a certain type of exception and limit the dammage. In this example we are only handling the unfortunate case of a java.net.ConnectException by returning a Nonevalue.
Composing Futures
The killer feature of Futures is their composeability. A very typical use-case when building asynchronous programming workflows is to combine the results of several concurrent operations. Futures (and Scala) make this rather easy:
def siteAvailable(url: String): Future[Boolean] =
WS.url(url).get().map { r =>
r.status == 200
}
val playSiteAvailable =
siteAvailable("http://www.playframework.com")
val playGithubAvailable =
siteAvailable("https://github.com/playframework")
val allSitesAvailable: Future[Boolean] = for {
siteAvailable <- playSiteAvailable
githubAvailable <- playGithubAvailable
} yield (siteAvailable && githubAvailable)The allSitesAvailable Future is built using a for comprehension which will wait until both Futures have completed. The two Futures playSiteAvailable and playGithubAvailable will start running as soon as they are being declared and the for comprehension will compose them together. And if one of those Futures were to fail, the resulting Future[Boolean] would fail directly as a result (without waiting for the other Future to complete).
This is it for the first part of this series. In the next post we will look at another tool for reactive programming and then finally at how to use those tools in combination in order to access a relational database in a reactive fashion.
Read on
Stay tuned as we’ll publish Parts 2 and 3 shortly as a part of this series:
- Part 1: Introduction to Futures, “Why async”, connection pool configuration
- Part 2: Introduction to Actors
- Part 3: Using jOOQ with Scala, Futures and Actors
| Reference: | Reactive Database Access – Part 1 – Why “Async” from our JCG partner Lukas Eder at the JAVA, SQL, AND JOOQ blog. |
