Editor’s note: If you would like to learn more about using Spark there is a free book titled Getting Started with Apache Spark: From Inception to Production.
If you’re thinking about working with big data, you might be wondering which tools you should use. If you are trying to enable SQL-on-Hadoop then you might be considering the use of Apache Spark or Apache Drill. While both are great projects with the ability to use Hadoop to process data, they have two very different goals. Both projects perform distributed data processing, however they are very different from one another. Selecting the right tool for the job is an important task.
Project Goals
There are some similarities between the two projects. Apache Drill and Apache Spark are both distributed computation engines with support for Hadoop. They both have very low barriers to entry. Both are open source and neither requires a Hadoop cluster to get started with them. All that is really needed is a personal computer. They can be downloaded to any desktop operating system, including Windows, Mac OS X, or Linux, or they can be run inside a virtual machine to avoid cluttering up your system. Spark contains many sub projects and the piece that directly compares with Drill is SparkSQL.
The differing approach to SQL reflects the major differences in the design philosophies of the two projects. Drill is fundamentally an ANSI SQL:2003 query engine, albeit an incredibly powerful one. Write your queries and they run against the data source, whether that is files on your computer, Hadoop cluster or a NoSQL database. Spark, on the other hand, is a general computation engine that happens to have SQL query capabilities. This enables you to do lots of interesting things with your data, from stream processing to machine learning.
In Drill, you write queries with an SQL query, much the same way you would with Microsoft SQL Server, MySQL, or Oracle. In Spark, you write code in Python, Scala or Java to execute a SQL query and then deal with the results of those queries. Most importantly, the queries in SparkSQL are not written in ANSI SQL. SparkSQL only supports a subset of SQL functionality.
ANSI SQL vs. SQL-Like
Drill supports ANSI SQL:2003. If you’re already familiar with SQL, this means that you can transfer your skills right over to the brave new world of NoSQL and big data. SparkSQL supports only a subset of SQL as its query language. While the former is the easiest to utilize because of its adherence to the SQL standard, the latter will often suffice for extracting data in order to process it with Spark.
Having a subset of SQL isn’t likely to be a dealbreaker for most people wanting to process data with Spark, as most people will use pretty simple SQL syntax. SELECT columns from some files or databases, maybe JOIN a couple different files and throw in a where clause to limit the results. However, when getting into slightly more complicated SQL syntax like a nested select statement, SparkSQL alone falls short.
Data Formats and Sources
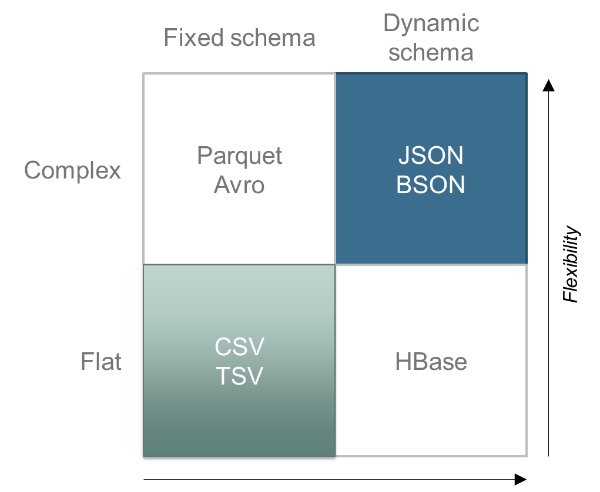
Apache Drill leverages a JSON data model to run SQL queries on a number of different data formats and data sources, some of which include: HBase, MapR-DB, Cassandra, MongoDB, MySQL, CSV, Parquet, Avro, and of course JSON. SparkSQL can also query many of these same data sources and formats, but the method by which Spark and Drill interact with the data sources varies widely.
Drill can query data from any or all of those data sources or formats at the same time and can push down functionality into the underlying storage system. Where Drill really differentiates itself from SparkSQL is in its capabilities to operate on JSON data. In order for Drill to work on more complex JSON data structures it offers some advanced capabilities as extensions to ANSI SQL. One of which is the FLATTEN command which enables dealing with arrays of data. This function separates the entries of an array and creates one row for each complete record for each value in the array. KVGEN–key-value generation–enables querying data where the name of a column of data is actually metadata. This is very helpful where you would not otherwise know the name of the field you want to query. I suggest perusing the Drill documentation for even more advanced operations.
Within Apache Drill all data is internally represented as either a simple or complex JSON data structure, and when represented in this way, Drill can discover the schema on the fly. This allows for complex data models that can be dynamic and change frequently—ideal for unstructured or semi-structured uses.
Drill’s distributed architecture gives a significant performance boost when dealing with disparate data formats, and Drill can work on many records at a time with vectorization. Even better, Drill optimizes queries and generates code on the fly for greater efficiency.
Leveraging Existing Tools
There are multiple choice for accessing Drill. It can be accessed via the Drill shell, web interface, ReST interface, or through JDBC/ODBC drivers. SparkSQL can be used from its interactive shell or its JDBC/ODBC drivers. There will be performance differences between the drivers based on how they are implemented, but since both projects have JDBC/ODBC support the big differentiator comes back to SQL support.
Apache Drill is supported by a number of business intelligence (BI) tools like Tableau, Qlik, MicroStrategy, Webfocus, and even Microsoft Excel to query big data. This integration makes Apache Drill very appealing to people with an existing investment in their favorite BI tools who are looking to handle workloads at scale. Since most BI users just want to query data, this makes Drill an excellent fit. While Spark with its SQL-Like syntax tends to be a less than adequate option for this use case.
This Apache Drill documentation and this Apache Spark documentation goes into much more detail on setting up JDBC and ODBC drivers.
Views and Security
Big data can mean a big headache when it comes to securing data. Many organizations need to have some way of making sure only authorized people have access to sensitive data. This is important in industries like healthcare that need to comply with regulations such as HIPAA, or in finance where sensitive customer information like a social security number needs to be protected.
Views can aggregate data from several sources and hide the underlying complexities of the data sources. Security through impersonation leverages views. Impersonation and views together offer fine grained security at the file level. A data owner can create a view which selects some limited set of data from the raw data source. They can then grant privileges in the file system for other users to execute that view to query the underlying data without giving the user the ability to read the underlying file directly.
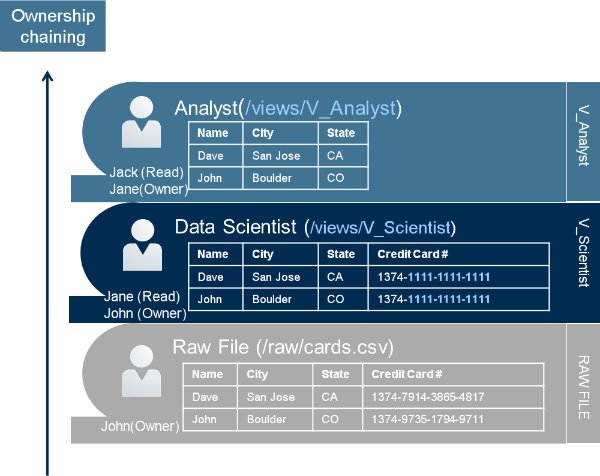
What is great about security through this impersonation model is that it does not require an additional security data store to manage this access. It leverages file system permissions, which makes it very easy to use and setup.
Spark does have this kind of scope. If simplifying access to data sources via views, privacy or data security are concerns for your use case, you are better off with Drill.
Conclusion
The key takeaway is that Drill is designed to be a distributed SQL query engine for pretty much everything, and Spark is a general computation engine which offers some limited SQL capabilities. If you are considering Spark only for SparkSQL my suggestion is to reconsider and move in the direction of Apache Drill.
If you need to perform complex math, statistics, or machine learning, then Apache Spark is a good place for you to start. If that isn’t the case, then Apache Drill is where you want to be.
If you need to use Apache Spark, but feel like its SQL support doesn’t meet your needs then maybe you want to consider using Drill within Spark. Since Drill has a JDBC driver and Spark can leverage such a driver, Spark could use Drill to perform queries. Don’t rule this out if you need the functionality of both Apache Spark and Apache Drill.
I encourage you to give them both a try for yourself. You can download them individually and install them yourself, or you can get them both within the MapR sandbox. This will let you play around with these powerful systems on your own machine.
| Reference: | Apache Spark vs. Apache Drill from our JCG partner Jim Scott at the Mapr blog. |
