In this blog post we will talk about various branching strategies that we can adopt during SDLC. Different strategies exist for different situations with your organisation and an informative decision should be taken based on what is available and what is the situation within the team.
Mainline Branch Strategy
Mainline branch strategy is the simplest yet most effective strategy for small to medium sized teams. The developers in the team constantly commit their work into a single, central branch—which is always in a deployment-ready state. In other words, the main branch for the project should only contain tested and quality work, and should never be broken.
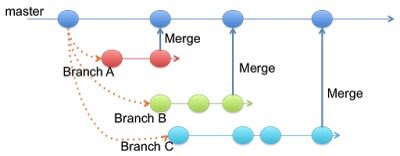
Each unit of work (or sprint) may have an accordion effect on the number of branches. At first, the developers are all working on their own pieces, and the number of branches expands. Then, as each of the developers finishes his or her work and integrates it with the others’, the accordion compresses back down again. There are variations of this strategy that can be used to suit a particular team’s wishes.
In Git terms, each developer in the team will have its own local branch. For example if a team is working on a feature : Implement Environment Service and one of the tasks is Implement Env Serv API, then the developer can create a local branch from the master (for eg. env-serv-api). Remember that breaking down of tasks into a unit of work during Sprint/Release Planning becomes important where the Scrum Master/Product Owner makes sure that each unit of work is a self-contained code.
Thus, in figure below, Branch A, Branch B and Branch C corresponds to Git Local Branches on a developer workstation.
Keeping the branching strategy simple ensures that you do not spend unnecessary time doing manual merges.
At scale, this approach of having a single working branch is used by teams working with automated build procedures.
Advantages
- There are not many branches across the project, which results in simplified workflows in the team as well as less confusion about where a change may have disappeared.
- Commits that are being made into the code base are relatively small and quick. If there is a problem, it should be relatively quick to undo the mistake.
- There are fewer emergency fixes, because any code that is saved into the main branch is ready to be deployed. Deployments can often be stressful for developers as they hold their breath while code goes live in production and wait to hear back from the code’s users. With tiny frequent updates, this procedure becomes practiced, and finally automated to the point where it should be almost invisible to the end user.
Disadvantages
- The assumption is that the main branch contains deployment-ready code. If the team doesn’t have a testing infrastructure, it can be risky to assume that new code won’t break anything, especially as the project becomes more complex over time.
- The notion of a deployment is more appropriate for code that is automatically loaded onto a user’s device (for example, a website). It is less appropriate for software that must be downloaded and installed. While updates that fix problems are welcomed, having frequent updates would annoy anyone who is looking to work with the application.
- One of the ways developers can verify code on production is to hide the feature behind a flag or a flipper. Facebook, Flickr, and Etsy are all rumored to use this technique. The potential risk here is that code can be abandoned behind the flags, resulting in a large technical debt for code that isn’t removed because it is hidden.
Branch Per Feature Deployment Strategy
In this strategy, there is a branch maintained per feature. Once the team/developer is confident that the feature works properly and is tested, the feature branch is merged into an integration branch, which is also a fork from the main branch whose sole intention is to not let broken commits be propagated to the main deployment branch. Ideally, anything in the master branch should be in a deployable state. Having this approach gives flexibility to choose which features should be used in the master deployment. Usually this is a manual step and thus is a hindrance in the overall goal for automated deployment.
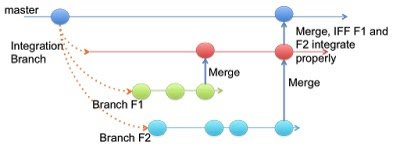
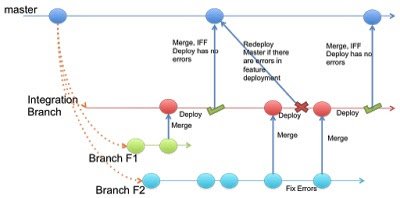
With this strategy there is a pause before the actual deployment. Github Flow uses this strategy . it relies on the concept of Pull Requests. Once the team/developer of the feature believes that the feature is complete, it sends the pull request to the Integration Branch. This Pull Request is then mediated manually, reviewed and if cleared, merged into the master. Here the master is always in a deployable state. Thus as soon as the merge happens, the master can be deployed.
Initially, GitHub Flow, first merged the Feature branch with the master and then deployed the master. Now it deploys the feature branch first and if it works properly, merges it with the master. This means that if there are problems with a feature branch, master can immediately be redeployed because it is proven to be in a working state.
Advantages
- Much like mainline development, the focus is on rapid deployment of code.
- Unlike the mainline development, there is an optional build step. When the build step is used, there is the option to select which features should be incorporated into the master branch for deployment.
Disadvantages
- If code is kept on a feature branch, but it is not immediately rolled into master, there is an extra maintenance requirement for developers who need to keep their features up to date while waiting to be rolled into the deployed branch.
- The semantic naming of the branches helps those who are familiar with the system, but it also represents an insider language that can make on-boarding more difficult if there are a lot of open features.
- There is now a housekeeping requirement for developers to remove old branches as they are rolled into master. This isn’t a large burden, but it is more than would be required from working out of a single master branch.
Environment Based Branching Strategy
Suppose you have a staging environment, a pre-production environment and a production environment. In this case the master branch is deployed on staging. When someone wants to deploy to pre-production they create a merge request from the master branch to the pre-production branch. And going live with code happens by merging the pre-production branch into the production branch. This workflow where commits only flow in one direction ensures that everything has been tested on all environments.
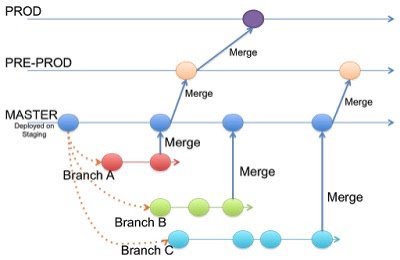
Through branch naming conventions, the above strategy makes it clear what code is going to be used in what environment, and therefore what conditions might need to be met before merging in commits. For example, you would clearly not merge untested code into a branch named production.
Variation to the above Branching Strategy used by Git
Git uses 4 different branches and names them appropriately for its team to understand what each branch is for. In addition it follows the convention that a commit can only propagate to the next branch in the stack. Thus the branches work much like a stacked pyramid. Each of the “lower” branches contain commits that are not present in the “higher” branches. As is shown in figure below, maintenance has the fewest commits, and proposed updates has the most commits. Once code has passed through the review process, it is incorporated into the next integration branch, getting closer to being incorporated into an official release.
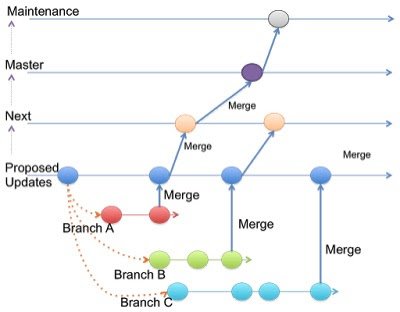
- maintenance: This branch contains code from the most recent stable release of Git as well as additional commits for point releases (maintenance).
- master: This branch contains the commits that should go into the next release.
- next: This branch is intended to test topics that are being considered for stability in the master branch.
- proposed updates: The proposed updates branch contains commits that are not quite ready for inclusion.
Release Branching Strategy
Only in case you need to release the software to the outside world, you need to work with release branches. In this case, each branch contains a minor version. The stable branch uses master as a starting point and is created as late as possible. By branching as late as possible you minimise the time you have to apply bug fixes to multiple branches. After a release branch is announced, only serious bug fixes are included in the release branch. If possible these bug fixes are first merged into master and then cherry-picked into the release branch. This way you can’t forget to cherry-pick them into master and encounter the same bug on subsequent releases. This is called an ‘upstream first’ policy that is also practiced by Google and Red Hat. Every time a bug-fix is included in a release branch the patch version is raised (to comply with Semantic Versioning) by setting a new tag. Some projects also have a stable branch that points to the same commit as the latest released branch. In this flow it is not common to have a production branch (or git flow master branch).
Resources
- https://about.gitlab.com/2014/09/29/gitlab-flow/
- https://www.safaribooksonline.com/library/view/git-for-teams/9781491911204/ch07.html#ch07
- https://www.safaribooksonline.com/library/view/git-for-teams/9781491911204/ch03.html
- https://www.kernel.org/pub/software/scm/git/docs/gitworkflows.html
- https://www.atlassian.com/git/tutorials/comparing-workflows/centralized-workflow
- http://blogs.atlassian.com/2014/01/simple-git-workflow-simple/
- Actual workflow for Branching Strategy – https://gist.github.com/jbenet/ee6c9ac48068889b0912
| Reference: | Git Branching Strategies from our JCG partner Anuj Kumar at the JavaWorld Blog blog. |

Nice read. Great Article!
Thank you for a nice article. Well understood and explained. Using it to explain to my newly formed development teams.