This article is part of our Academy Course titled Spring Integration for EAI.
In this course, you are introduced to Enterprise Application Integration patterns and how Spring Integration addresses them. Next, you delve into the fundamentals of Spring Integration, like channels, transformers and adapters. Check it out here!
Table Of Contents
1. Introduction
This is the first part of the Spring Integration course. This part introduces you to what enterprise integration patterns are and how different strategies can be applied to design integration solutions. The reason behind why you should acquire a basic knowledge of these patterns in this course is because the Spring Integration project was designed upon these patterns. The following parts of this course will get into the Spring Integration project and show practical examples of how these patterns are applied.
2. Enterprise integration patterns
Enterprise Integration Patterns is a group of 65 design patterns which are compiled in the book under the same name and written by Gregor Hohpe and Bobby Woolf back in 2003. The target of defining these design patterns is in view of the need to standardize procedures and establish a reference for the developers in order to deal with building integration solutions.
This group of integration design patterns is the result of a recompilation of practices used by experienced developers during years, and each of them describe the base solution to a specific design problem related to the communication among different systems.
Once we move forward through the course, you will see how Spring Integration’s API is based on these enterprise integration patterns, since its design was inspired on the concepts explained in the above book. This first tutorial will make a brief introduction to these concepts in order to make you feel familiar with them when you see how Spring Integration is built.
3. Integration strategies
The task of integration between applications or systems has always been pretty difficult. Some of the reasons are that applications can be written in different programming languages (the communication among them is impossible since one system does not understand the other) or use a different data format (the message is incompatible). During the years, different approaches have been implemented in order to face these problems and accomplish the challenge of integrating applications. There are basically four strategies which are briefly described below:
3.1. File transfer
This strategy involves applications sharing information by using files. You can have one or more applications which produce a file with information (the producer), and other applications will consume this data (consumers). One of the most important things to take into account is to decide which standard format will the data within the file have, because all involved applications should know how to deal with it. One of the most accepted formats is the use of XML.
Once the data format is set, there may be several applications which use the information in that file in a different manner. For that purpose, the consuming application will need an interceptor with the target to transform the format in which the file has been generated so that it can be adapted to the application’s requirements.
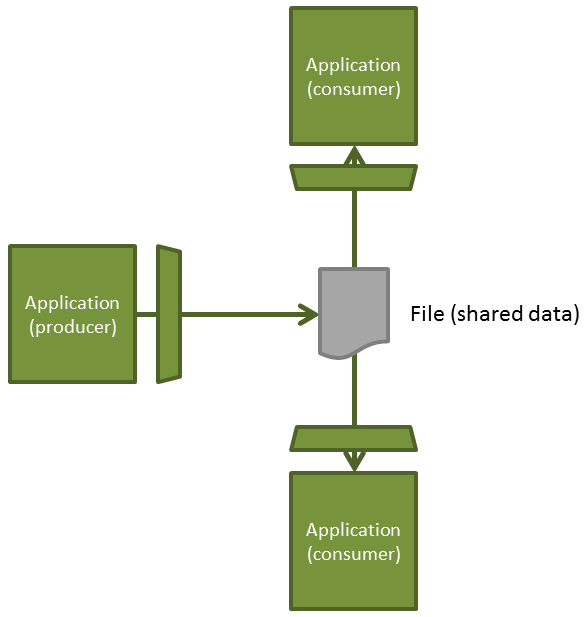
The main advantage is that it decouples applications from each other. The consuming application does not need to know the internals of the producing application. Interceptors will deal with files, so changes in any of the involved applications don’t affect the others as long as they keep the same file format.
On the other side, this approach usually takes time, so it may not be ideal if you need the information too frequently. Some applications may need to show updated information as quickly as possible. In this case, a shared database may be a better option. Another aspect to consider is that file transfer strategy is quite unsafe, since it is not transactional and can have concurrency issues.
3.2. Shared database
This solution is based upon having a central database that stores all the information that needs to be shared. This way, different applications will be able to simultaneously access the same data, provided you use transaction management. By using the same database, the retrieved information will be consistent and up to date. Also, the information can be quickly accessed by the consumers, making sure you don’t get stale data. This would be one of the drawbacks you would have to face if file transfer was used.
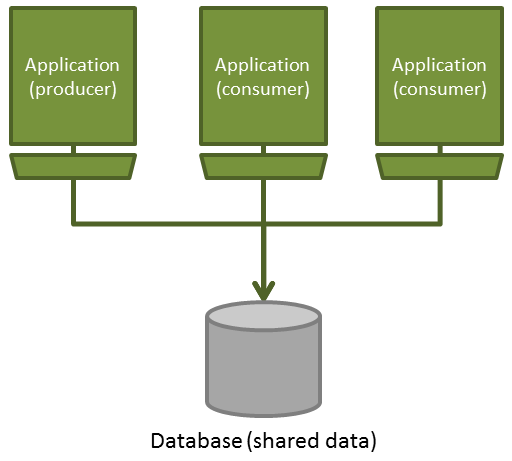
You have to keep in mind though, that there can be performance issues if multiple applications access the same data. Some applications may be blocked trying to modify data locked by another application.
Another difficulty is found when designing the database schema. The resulting schema should be suitable for all the involved applications. Additionally, you will have to take into account that any change in the schema would affect them. Nowadays, this may not be an issue if you take the decision of using a NoSQL database like MongoDB or Apache Cassandra because these types of databases use a schemaless data structure. Considering the advantages or disadvantages of each type is beyond the scope of this tutorial.

3.3. Remote Procedure Invocation
In previously discussed approaches, a producer produces information (stored into a file or database) and others can consume it. But, what if you need to interact with the other application depending on the shared data? There’s a problem here, since the producer does not know the internals of the consuming application. You need some kind of abstraction mechanism. This is where remote procedure invocation comes in.

The remote procedure invocation consists of an application interacting directly with another application through stubs. The client calls a stub (client stub) through a local procedure call, and the stub sends the message to the server, where another stub (skeleton) will receive it and call the server procedure.
The cons of this approach are that applications get tightly coupled and their calls are slow. This brings us to the last strategy, messaging.
3.4. Messaging
Messaging is a better fit if you need to exchange small amounts of information between applications. The great benefit of messaging is that components (producers and consumers) are decoupled. The producer can send the message without knowing who is on the other side. There may be one or more consumers that will receive the message, but that’s not relevant to the producer.
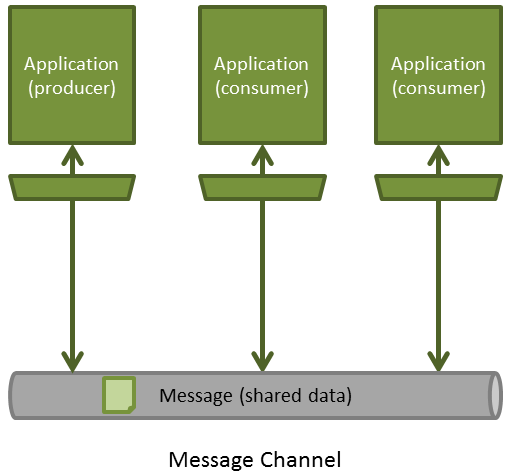
Another important feature is that messaging can be done asynchronously. This means the producer can send the message and continue with his logic without having to block in order to wait for the consumer to return the response. Once the consumer has processed the message and sent a response, the producer will be notified.
The main downside of this approach is its complexity, especially when dealing with asynchronous messaging.
This strategy is considered by the book authors of enterprise integration patterns generally the best approach for integration enterprise applications, and the Spring Integration project is based upon this same strategy. For this reason, the rest of the tutorial will be based on this strategy.
An architecture based on this strategy is called message driven architecture. The next section explains its basic concepts, which will be largely used through this course.
4. Message driven architecture
A message driven architecture is an architecture based on the messaging strategy that you have seen in the previous section. The basic concepts on which this strategy is built are explained below:
- Message: Amount of information that is shared among applications or among different components in the same application. This message is a data structure composed by a header containing meta-information about the message, and a body that contains the information that we want to share.
- Producer: A component which creates (produces) a message and sends it to a message channel. The message can be sent synchronously so the producer will block its thread and wait until a response is received. But, if the processing may take time, there’s a better option; the producer can send the message asynchronously.
- Message channel: A message channel is some kind of pipe or queue that connects the producer to one or several consumers.
- Consumer: A component that retrieves (consumes) the message from the message channel and processes it. Optionally, a response is sent back to the producer.
This message driven approach loosely couples applications. An asynchronous communication connects both applications in a way that one application does not need to know if the other is active. The producer can send the message and forget about it, continuing with its own work. If the sending requires a response, the producer will be notified in order to handle the result.
5. Synchronous and asynchronous communication
Synchronous communication allows for a real time conversation where both parts are active. The sender sends the message and waits for the receiver to process it and return a response. This is useful when the producer needs an immediate response in order to continue with its tasks. This type of communication has its drawbacks though; for example, the next task that needs to be done by the sender will be delayed if the receiver processing takes time. Or even worse, the consumer may be inactive. A common solution is to establish a timeout and handle it if the response takes too much time.
Asynchronous communication allows decoupling of both parts, each one possibly acting at a different time (the receiver could not be active at the moment of the sending). This approach is common when the sender does not need the response immediately. It will continue processing its tasks until a response is received. Asynchronous communication can be adequate when the receiver processing takes time.
Spring Integration allows both types of communication, each one with its advantages and disadvantages. During the following tutorials of this course, you will see how to accomplish this and be able to decide which one is more adequate in each situation.

I have to admit, this is the best source to learn very good medium and advanced topics.
Thank You.
I liked the way basic patterns are described.