 In one of my previous posts I already discussed how to process the Twitter sample feed using Apache Storm, and now we’re going to walk through the steps of creating a sample Spring Boot application that reads messages from Twitter sample feed using the Spring Social Twitter framework and writes data to Neo4J using Spring Data Neo4J.
In one of my previous posts I already discussed how to process the Twitter sample feed using Apache Storm, and now we’re going to walk through the steps of creating a sample Spring Boot application that reads messages from Twitter sample feed using the Spring Social Twitter framework and writes data to Neo4J using Spring Data Neo4J.
The whole project is available on Github at https://github.com/davidkiss/twitter-keyword-graph, but we’ll be discussing here each step one-by-one.
What is Spring Boot?
In case you’re wondering what Spring Boot might be, it’s one of the latest addition to the Spring stack and is built on top of the Spring Framework. Spring Boot takes software development productivity to the next level while also offering some production ready tools out of the box (metrics, health-checks, externalized configuration and integration with liquibase, a DB refactoring tool).
Configuring the application
All application related configurations are stored in the src/main/resources/application.properties file that you have to create from the template application-template.properties file in the same folder. Make sure to update the properties file with your own config values to connect to Twitter Api (https://twittercommunity.com/t/how-to-get-my-api-key/7033).
The neo4j.uri property is used to set the connection details to our Neo4J server.
Setting the twitterProcessing.enabled property to false will disable processing the twitter feed while we can still query the application’s REST api for already processed data.
The taskExecutor.xyz properties are used for the TaskExecutorPool where we configure a pool of workers that will process tweets in parallel from the Twitter feed.
Spring Boot can do wonders using its annotation, and it helped getting the web application up and running in a few lines of code. See the Application, Neo4JConfig, TwitterConfig and TaskExcutorConfig classes on how the Neo4J and Twitter clients are wired together using the application.properties config file.
Reading messages from Twitter feed
The TwitterStreamIngester service class has a listener set up for the Twitter sample feed using Spring Social Twitter. Based on the number of workers configured for the TaskExecutor, the application creates multiple instances of the TweetProcessor class that will process the tweets asynchronously and in parallel (if processing is enabled).
The asynchronous processing is done using a BlockingQueue and the ThreadPoolTaskExecutor bean injected by Spring. If the processing of the tweets is slower than the rate of incoming tweets, the application will drop the new tweets (see the BlockingQueue#offer() method) until it catches up.
Here’s the code that reads messages from the feed and puts them in the queue in TwitterStreamIngester:
public void run() {
List<StreamListener> listeners = new ArrayList<>();
listeners.add(this);
twitter.streamingOperations().sample(listeners);
}
@PostConstruct
public void afterPropertiesSet() throws Exception {
if (processingEnabled) {
for (int i = 0; i < taskExecutor.getMaxPoolSize(); i++) {
taskExecutor.execute(new TweetProcessor(graphService, queue));
}
run();
}
}
@Override
public void onTweet(Tweet tweet) {
queue.offer(tweet);
}And here’s the code in TweetProcessor class that processes messages from the queue:
@Override
public void run() {
while (true) {
try {
Tweet tweet = queue.take();
processTweet(tweet);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}Talking to Neo4J database
The application requires a stand-alone Neo4j server running. You can download the latest version of Neo4J Community Edition from http://neo4j.com/download/ and start it by running bin/neo4j-community.
In the small dialog click the Start button in the bottom right and in a few seconds the database should be up and running at http://localhost:7474/.
Going back to the code, the KeywordRepository class extends Spring Data Neo4J’s repository interfaces allowing us to create Cypher queries to retrieve data from Neo4j without any boilerplate code. Using the @RepositoryRestResource annotation it also creates REST endpoints to access twitter keywords data:
@RepositoryRestResource(collectionResourceRel = "keywords", path = "keywords")
public interface KeywordRepository extends GraphRepository<Keyword>, RelationshipOperationsRepository<Keyword> {
// Spring figures out Neo4j query based on method name:
Keyword findByWord(String word);
// Spring implements method using query defined in annotation:
@Query("START n = node(*) MATCH n-[t:Tag]->c RETURN c.word as tag, count(t) AS tagCount ORDER BY tagCount DESC limit 10")
List<Map> findTopKeywords();
@Query("start n=node({0}) MATCH n-[*4]-(m:Keyword) WHERE n <> m RETURN DISTINCT m LIMIT 10")
List<Keyword> findRelevantKeywords(long keywordId);
}Note that the Application class has to be configured to look for the @RepositoryRestResource annotation:
...
@Import(RepositoryRestMvcConfiguration.class)
public class Application extends Neo4jConfiguration {
...The GraphService class encapsulates all Neo4j related operations – creating nodes and relationships in the database and querying existing records. Here’s an excerpt from the class:
public Tag connectTweetWithTag(Tweet tweet, String word) {
Keyword keyword = new Keyword(word);
keyword = keywordRepository.save(keyword);
Tag tag = tweetRepository.createRelationshipBetween(tweet, keyword, Tag.class, "Tag");
return tag;
}
// ...
public List<Map> findTopKeywords() {
return keywordRepository.findTopKeywords();
}Rest api to query Neo4j
Apart from the REST endpoints automatically provided by Spring Data (for example: http://localhost:8080/keywords/), the TwitterController class is configured to handle custom REST requests using the Spring MVC annotations:
@RequestMapping("/keywords/relevants/{word}")
@ResponseBody
public Iterable<Keyword> findRelevantKeywords(@PathVariable("word") String word) {
return graphService.findRelevantKeywords(word);
}You can test this endpoint once the application is up and running at http://localhost:8080/keywords/relevants/<your keyword>.
Building the Application
This sample application uses Maven v3+ and in case you don’t have it installed, here’s the link to download it: http://maven.apache.org/download.cgi.
The pom.xml is very straight forward, it contains a list of all the spring dependencies. Notice the configuration of the spring-boot-maven-plugin in the file and the start-class property which defines the main class that the spring boot maven plugin can start from the command line (Spring Boot uses an embedded Tomcat server to serve HTTP requests).
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.7</java.version>
<start-class>com.kaviddiss.keywords.Application</start-class>
<spring-data-neo4j.version>3.2.0.RELEASE</spring-data-neo4j.version>
</properties><build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>Running the application
To run the application execute below command:
mvn spring-boot:run
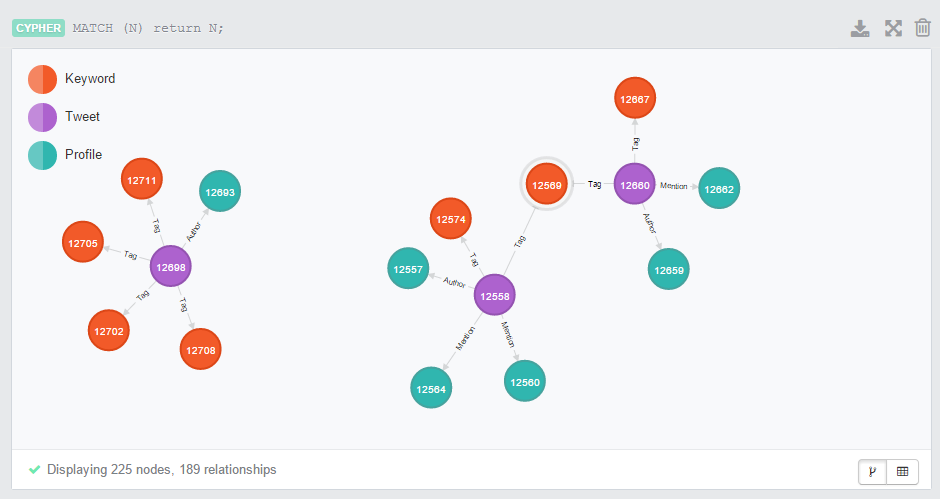
In order to see existing data populated in Neo4j, go to http://localhost:7474/browser/ and execute this query:
MATCH (N) return N;
The result will be something similar to below screenshot.
Summary
This post gives a glimpse of using a few of Spring’s most exciting technologies (Spring Boot and Spring Data) and Neo4j DB. I hope you enjoyed it and you got enough information to get started on your own project.
Have you used Spring Boot before? What’s your experience with Spring Boot or any of the other technologies mentioned here? Leave your comments below.
In case you’re looking for help building efficient and scalable Java-based web applications, please let me know.
| Reference: | Processing Twitter feed using Spring Boot from our JCG partner David Kiss at the Building scalable enterprise applications blog. |

Hi David, nice article thanks a lot. It would be cool if you would use the most recent version of Neo4j (2.2.3) and Spring Data Neo4j (3.3.2) release, so that people don’t get stuck with the older versions. The cypher syntax for your queries should now also be much shorter: @Query(“START n = node(*) MATCH n-[t:Tag]->c RETURN c.word as tag, count(t) AS tagCount ORDER BY tagCount DESC limit 10”) List findTopKeywords(); @Query(“MATCH (c:KeyWord)<-[:Tag]-() RETURN c.word as tag, count(*) AS tagCount ORDER BY tagCount DESC limit 10") List findTopKeywords(); @Query(“start n=node({0}) MATCH n-[*4]-(m:Keyword) WHERE n m RETURN DISTINCT m LIMIT 10”)… Read more »