The top 5 things you need to know before moving to Apache Spark
It seems like everyone’s only talking about the new hottest tech and neglect what it actually means to adopt it. But it’s only natural, right? The new features and promises outshine everything else and the tough challenges and decisions are swept aside.
Not this time. Software architecture is hard, and trade offs are the name of the game.
In this post, we wanted to take a step back and see what it actually means to execute the decision of moving to Spark from the ground up. A huge thanks goes out to Tzach Zohar, Developer and System Architect at Kenshoo, who shared his experience with us for this post.
Why bother moving at all?
If you’re starting with a whole new project that would benefit from distributed data analysis, be it batch analysis or streamlined analysis, Spark has already pretty much established its supremacy as the best implementation of MapReduce. Mostly because of the way it uses in-memory processing. Otherwise, if you’re getting the throughput you need with a single server, and the data you’re using isn’t expected to outgrow it, you’re probably better off avoiding the added complexity of going distributed. Notice how we didn’t say big data even once. Oh. In addition, Spark has an awesome and easy to use machine learning library.
Spark vs. Hadoop
It’s more likely though that your starting point is an existing solution you already have, and this is where things can get extra hairy. We’ll put the focus of the post on that. Migrating from Hadoop or a home grown solution on top of databases that are struggling with scale. The performance boost can eventually cut down your hardware cost, increase productivity, or just really be the only way to get away with what is it that you’re trying to do.
The biggest benefit comes from the batch analysis angle, so if that’s your use case – Upgrading your cluster can be even more urgent. In Kenshoo’s case, a single-server MySQL solution was once more than enough. But as the company grew and years have passed, this was no longer enough – Tens and millions of records going in every day, hundreds of tables, over a billion of records on the bigger ones, and terabytes of data. It’s not Kansas anymore. There comes a point when all the optimizations you throw at it and even high-performance storage engines like TokuDB just won’t do. What you do end up with is a mutant MySQL on steroids.
On the other side of the shore there’s Spark, solving all sorts of issues, new, but implementing longstanding principles, and gaining fast adoption and lots of positive signals from the community.

1. HDFS vs. Cassandra vs. S3
Your choice of a storage server for Apache Spark should reflect what you value most for your system. The 3 common options here are Hadoop’s HDFS, Apache Cassandra, and Amazon’s S3. S3 fits very specific use cases, when data locality isn’t critical. Like jobs that run once per day for example, or anything really that doesn’t require the data and processing power to share a machine. Jobs with no urgency. As for the HDFS vs. Cassandra issue, hardware costs for running HDFS are lower, since it was designed to solve simpler use cases. How low? As far as 10x. The main difference comes from HDFS solving the issue of running of a distributed file system, while Cassandra was specifically designed to be a high-throughput key-value store.
Although the higher costs, Cassandra has the upper hand when it comes to interactive, streaming data analysis – Opposed to running batch jobs. You could say that HDFS loves big files, while Cassandra doesn’t have to load all of the data, use only what it needs and reach
- S3 – Non urgent batch jobs.
- Cassandra – Perfect for streaming data analysis and an overkill for batch jobs.
- HDFS – Great fit for batch jobs without compromising on data locality.
2. Greenfield vs. Refactoring
Alright, so you’ve decided to move to Spark, now, should you start off fresh with a greenfield project or refactor based on your current application? Each has their own caveats, and Kenshoo decided to let go of the greenfield path in favor of refactoring their current system. This decision narrows down to 4 factors:
- Avoiding a moving target scenario – Building a new system from scratch takes time, months of development. And during that time the legacy system is also changing, so your spec is literally a moving target that changes over time.
- Zero diff tolerance – The new system should reach the same results as the legacy one, right? What sounds like a straightforward process, is a problem in disguise. With years in development, all kinds of quirks and customizations for specific analysis processes have been hardcoded into the older application. Certain assumptions, rounding results, and requests from individual clients for instance – Have created a complex analysis process that’s hard to recreate from scratch.
- Code is the only spec – Documentation is most likely… Nonexistent. And if it does exist, it most likely that doesn’t reflect the current state of the system. Here’s one example that you can probably relate to, those dark corners in the code:

Stuff that “shouldn’t” happen, but does it happen? - Test reuse – Your current tests are coupled with the older implementation, and assume a different setup. Another task here is to rewrite them to match the new implementation.

Bottom line: In this case, refactoring, rather than starting up completely fresh – Made the most sense.
3. Refactoring challenges
Choosing the refactoring path also has its challenges, untested legacy code, tight coupling with other system components, and the paradigm shift for a new architecture. Switching from a similar Hadoop architecture would be easier than getting on the distributed system path after being on a single node application. There are new skills to learn, processes to adjust, and there’s lots of friction. Greenfield or not, it’s a hard task, but if you’ve determined that it’s worth it – There’s a light at the end of this tunnel.
In Kenshoo’s case, their mission was to free a bottleneck aggregator component from a huge 8 year old system. The aggregator performs occasional batch processing on the data and groups it by different keys.
Bottom line: Know your weak spots in advance before moving, and make sure you have solution approaches for the critical paths in your new implementation.
4. Solution approaches
4.1. Core business rules first
One of the main benefits of refactoring is of course code reuse. The first step for building the new system was to go for the core business rules first and create a stand-alone jar from them. The methods were refactored to Java static methods to avoid serialization issues in Spark.
4.2. Dropwizard metrics and untangling legacy code
Moving on up, remember that “shouldn’t happen” example? Kenshoo rigged it up with a Dropwizard Metrics counter:
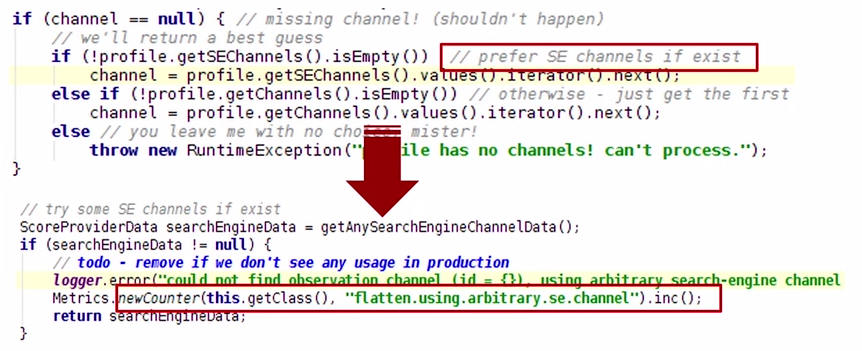
And what do you know. It does happen quite a lot:
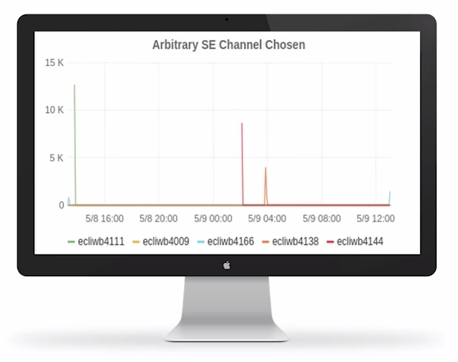
Bottom line: Using metrics to measure the unknowns in the legacy code proved to be a powerful tool, which allowed turning “hidden” features into explicit, well-documented, and well tested features.
4.3. Local mode testing
To take a stab at the testing challenges, Kenshoo made use and took inspiration from Spark’s local mode – Creating an embedded like instance of Spark inside the new aggregation component. Moreover, they then took this new component, and embedded it in the legacy system, reusing the older tests and make sure the new system meet all the requirements:
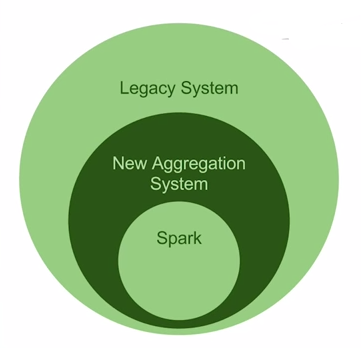
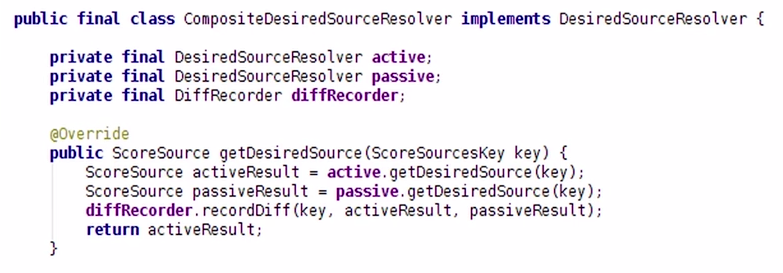
4.4. Graphite the “diffRecorder”
The final frontier, beyond the local mode testing, is to test on real data in production and see if the Spark results match those of the legacy system. For this purpose, a “diffRecorder” hooked up with Graphite visualizations was implemented. The Diff Recorder represents every real input for which the two versions differed as a Graphite Metric, pin-pointing the exact inputs for which the new implementation isn’t consistent.
And the resulting data helped understand what needs to be further tweaked to match the older system (or… uncovering hidden faults in the system). btw, to learn more about Graphite you can check out this post about choosing the best Graphite architecture for your system.
5. Spark Monitoring
Spark has a great integration with Graphite where you can plot any kind of graph that you have in mind. Beyond that, the second go to tool here would the Spark web UI for viewing your jobs and performance metrics. Any serious deployment of Spark requires putting in lots of thought into performance and monitoring. This can become a really thorny issue and you need to be familiar with internals to tune the system. Writing code for Spark is easy, but performance adds another layer of complexity. In that sense, it’s easy to go wrong here and produce bad code.
Check out this post where we explored Taboola’s Spark monitoring architecture, and why are they moving ahead to add Takipi to their monitoring stack.
Recommended resources for getting started with Spark
The basic docs are short, straightforward, and get the job done. More advanced topics covering Spark performance tuning can be found mostly in recorded talks from previous Spark summits.
Conclusion
Storage, refactoring techniques, monitoring, test reuse, and consistent results – We hope you’ve found the provided solutions useful and know how to apply them when needed. Transitions to new technologies are tough. In addition to the learning curve, they make you more vulnerable to errors (And also make you more likely to receive calls in the middle of the night to fix some critical production issue). For these kind of situations, we launched Takipi’s error analysis for Spark.
We’d like to say thanks again to Tzach Zohar from Kenshoo for sharing his experience with us for this post!
| Reference: | Apache Spark: 5 Pitfalls You MUST Solve Before Changing Your Architecture from our JCG partner Alex Zhitnitsky at the Takipi blog. |

{kind=link}