In this post I’ll mention the first paper at which Spark is introduced, Spark: Cluster Computing with Working Sets. This post will be one of the base posts about my GSoC project. You can read the post about my accepted proposal from here: GSoC 2015 Acceptance for Apache GORA.
MapReduce and its variants are successful for large-scale computations. However, most of these variants are based on acyclic data flow model that is not suitable for many applications. Spark presents a solution to reuse a working set of data across multiple parallel operations. Iterative machine learning applications and interactive data analysis are such kind of tasks. Spark supports these while retaining the scalability and fault tolerance of MapReduce.
When we look closer to these two use cases:
- Iterative jobs: Many machine learning algorithms use same dataset and repeatedly applies same function to optimize a parameter. When each job is defined as a MapReduce job, each job should reload data from disk which causes a performance problem.
- Interactive analytics: When working with Hadoop, each query is a single job and reads data from disk. So, it causes a another performance problem too.
Spark integrates into Scala which is a statically typed high-level programming language for the Java VM. Developers write a program called driver program to use Spark to run operations parallel. There are two main abstractions which Spark provides for parallel programming, these are RDD (Resilient Distributed Datasets) and parallel operations (functions are passed to apply on a dataset). Also, Spark has two restricted types of shared variables that can be used within function running on a cluster.
Resilient Distributed Datasets (RDDs)
RDDs are one of the main difference at Spark. They are read only collection of objects which need not to be in physical storage and RDDs can always be reconstructed if nodes fail.
Each RDD is represented by a Scala object and programmers can construct RDDs in four ways:
- From a file in a shared file system
- By parallelizing a Scala collection
- By transforming an existing RDD
- By changing the persistence of an existing RDD.
RDDs’ persistence can be altered with two ways. First one is cache action which leaves dataset lazy but lets dataset to be cached after the first time it is computed. Second one is save action which lets dataset to evaluate and write to a distributed file system. Cache action works similar to idea of virtual memory. When there is not enough memory, Spark will recompute all partitions of a dataset.
There maybe applied several parallel operations on RDDs: reduce, collect and forearch.
Shared Variables
There are two restricted types of shared variables at Spark: broadcast variables and accumulators. Broadcast variables suitable when working on large read-only variables and want to distribute it. Accumulators are suitable for add tasks.
Implementation
Spark is built on Mesos which is a cluster operating system and lets multiple parallel applications share a cluster.
The core of Spark is RDDs. Here is an example usage of RDDs:
val file = spark.textFile("hdfs://...")
val errs = file.filter(_.contains("ERROR"))
val cachedErrs = errs.cache()
val ones = cachedErrs.map(_ => 1)
val count = ones.reduce(_+_)Key point is that, these datasets are stored as a chain of objects that captures the lineage of each RDD. Below is the lineage chain of given example:
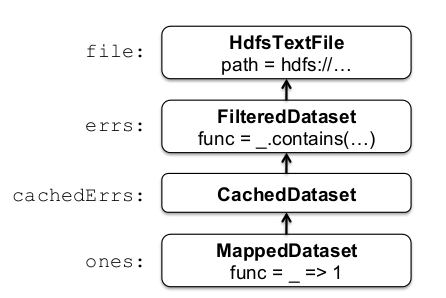
errs and ones are lazy RDDs. When reduce is called, input blocks are scanned in a streaming manner to evaluate ones, these are added to perform a local reduce, and are local counts are sent to the driver. This paradigm is similar to MapReduce.
Spark’s difference is it can make some of the intermediate datasets persist across operations. errs can be reused with that way:
val cachedErrs = errs.cache()
which creates a cached RDD and parallel operations can be run on that. After the first time it is computed it can be reusable and helps to gain speed up.
Each RDD object implements three operations:
- getPartitions, returns a list of partition IDs
- getIterator(partition), iterates over a partition
- getPreferredLocations(partition), used for task scheduling to achieve data locality.
Different types of RDDs differ on how they implement RDD interface as like HdfsTextFile, MappedDataset and CachedDataset.
Performance
When logistic regression is implemented at both Spark and Hadoop which requires iterative computational work load, below is the results:
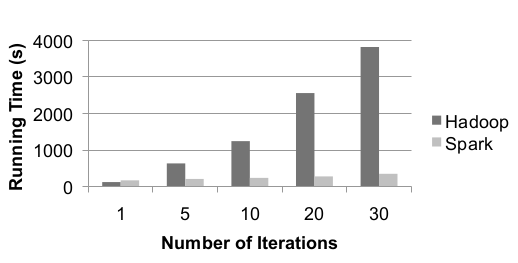
It can be seen that at first iteration Hadoop is better likely due to using Scala instead of Java. However subsequent iterations takes only 6 seconds because of reusing cached data. This represents the power of Spark compared to Hadoop.
Conclusion
This post examined Spark and cluster computing. Spark is believed as it is the first system to allow an efficient, general-purpose programming language to be used interactively to process large datasets on a cluster. Its core feature is RDDs and it also has two other abstractions which are broadcast variables and accumulators. Results show that Spark can run 10x faster than Hadoop due to its internal design.
| Reference: | Spark and Cluster Computing from our JCG partner Furkan Kamaci at the FURKAN KAMACI blog. |
