About a year ago Ian pointed me at a Chicago Crime data set which seemed like a good fit for Neo4j and after much procrastination I’ve finally got around to importing it.
The data set covers crimes committed from 2001 until now. It contains around 4 million crimes and meta data around those crimes such as the location, type of crime and year to name a few.
The contents of the file follow this structure:
$ head -n 10 ~/Downloads/Crimes_-_2001_to_present.csv ID,Case Number,Date,Block,IUCR,Primary Type,Description,Location Description,Arrest,Domestic,Beat,District,Ward,Community Area,FBI Code,X Coordinate,Y Coordinate,Year,Updated On,Latitude,Longitude,Location 9464711,HX114160,01/14/2014 05:00:00 AM,028XX E 80TH ST,0560,ASSAULT,SIMPLE,APARTMENT,false,true,0422,004,7,46,08A,1196652,1852516,2014,01/20/2014 12:40:05 AM,41.75017626412204,-87.55494559131228,"(41.75017626412204, -87.55494559131228)" 9460704,HX113741,01/14/2014 04:55:00 AM,091XX S JEFFERY AVE,031A,ROBBERY,ARMED: HANDGUN,SIDEWALK,false,false,0413,004,8,48,03,1191060,1844959,2014,01/18/2014 12:39:56 AM,41.729576153145636,-87.57568059471686,"(41.729576153145636, -87.57568059471686)" 9460339,HX113740,01/14/2014 04:44:00 AM,040XX W MAYPOLE AVE,1310,CRIMINAL DAMAGE,TO PROPERTY,RESIDENCE,false,true,1114,011,28,26,14,1149075,1901099,2014,01/16/2014 12:40:00 AM,41.884543798701515,-87.72803579358926,"(41.884543798701515, -87.72803579358926)" 9461467,HX114463,01/14/2014 04:43:00 AM,059XX S CICERO AVE,0820,THEFT,$500 AND UNDER,PARKING LOT/GARAGE(NON.RESID.),false,false,0813,008,13,64,06,1145661,1865031,2014,01/16/2014 12:40:00 AM,41.785633535413176,-87.74148516669783,"(41.785633535413176, -87.74148516669783)" 9460355,HX113738,01/14/2014 04:21:00 AM,070XX S PEORIA ST,0820,THEFT,$500 AND UNDER,STREET,true,false,0733,007,17,68,06,1171480,1858195,2014,01/16/2014 12:40:00 AM,41.766348042591375,-87.64702037047671,"(41.766348042591375, -87.64702037047671)" 9461140,HX113909,01/14/2014 03:17:00 AM,016XX W HUBBARD ST,0610,BURGLARY,FORCIBLE ENTRY,COMMERCIAL / BUSINESS OFFICE,false,false,1215,012,27,24,05,1165029,1903111,2014,01/16/2014 12:40:00 AM,41.889741146006095,-87.66939334853973,"(41.889741146006095, -87.66939334853973)" 9460361,HX113731,01/14/2014 03:12:00 AM,022XX S WENTWORTH AVE,0820,THEFT,$500 AND UNDER,CTA TRAIN,false,false,0914,009,25,34,06,1175363,1889525,2014,01/20/2014 12:40:05 AM,41.85223460427207,-87.63185047834335,"(41.85223460427207, -87.63185047834335)" 9461691,HX114506,01/14/2014 03:00:00 AM,087XX S COLFAX AVE,0650,BURGLARY,HOME INVASION,RESIDENCE,false,false,0423,004,7,46,05,1195052,1847362,2014,01/17/2014 12:40:17 AM,41.73607283858007,-87.56097809501115,"(41.73607283858007, -87.56097809501115)" 9461792,HX114824,01/14/2014 03:00:00 AM,012XX S CALIFORNIA BLVD,0810,THEFT,OVER $500,STREET,false,false,1023,010,28,29,06,1157929,1894034,2014,01/17/2014 12:40:17 AM,41.86498077118534,-87.69571529596696,"(41.86498077118534, -87.69571529596696)"
Since I wanted to import this into Neo4j I needed to do some massaging of the data since the neo4j-import tool expects to receive CSV files containing the nodes and relationships we want to create.
I’d been looking at Spark towards the end of last year and the pre-processing of the big initial file into smaller CSV files containing nodes and relationships seemed like a good fit.
I therefore needed to create a Spark job to do this. We’ll then pass this job to a Spark executor running locally and it will spit out CSV files.
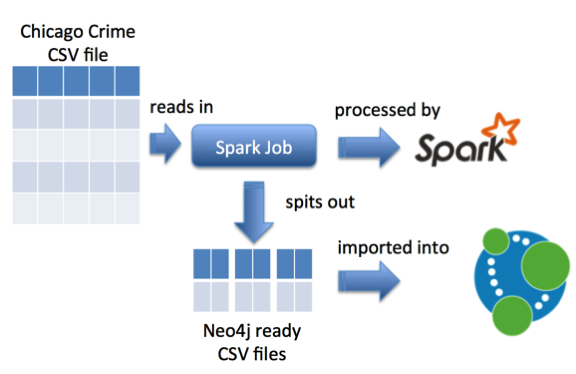
We start by creating a Scala object with a main method that will contain our processing code. Inside that main method we’ll instantiate a Spark context:
import org.apache.spark.{SparkConf, SparkContext}
object GenerateCSVFiles {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Chicago Crime Dataset")
val sc = new SparkContext(conf)
}
}Easy enough. Next we’ll read in the CSV file. I found the easiest way to reference this was with an environment variable but perhaps there’s a more idiomatic way:
import java.io.File
import org.apache.spark.{SparkConf, SparkContext}
object GenerateCSVFiles {
def main(args: Array[String]) {
var crimeFile = System.getenv("CSV_FILE")
if(crimeFile == null || !new File(crimeFile).exists()) {
throw new RuntimeException("Cannot find CSV file [" + crimeFile + "]")
}
println("Using %s".format(crimeFile))
val conf = new SparkConf().setAppName("Chicago Crime Dataset")
val sc = new SparkContext(conf)
val crimeData = sc.textFile(crimeFile).cache()
}The type of crimeData is RDD[String] – Spark’s way of representing the (lazily evaluated) lines of the CSV file. This also includes the header of the file so let’s write a function to get rid of that since we’ll be generating our own headers for the different files:
import org.apache.spark.rdd.RDD
// http://mail-archives.apache.org/mod_mbox/spark-user/201404.mbox/%3CCAEYYnxYuEaie518ODdn-fR7VvD39d71=CgB_Dxw_4COVXgmYYQ@mail.gmail.com%3E
def dropHeader(data: RDD[String]): RDD[String] = {
data.mapPartitionsWithIndex((idx, lines) => {
if (idx == 0) {
lines.drop(1)
}
lines
})
}Now we’re ready to start generating our new CSV files so we’ll write a function which parses each line and extracts the appropriate columns. I’m using Open CSV for this:
import au.com.bytecode.opencsv.CSVParser
def generateFile(file: String, withoutHeader: RDD[String], fn: Array[String] => Array[String], header: String , distinct:Boolean = true, separator: String = ",") = {
FileUtil.fullyDelete(new File(file))
val tmpFile = "/tmp/" + System.currentTimeMillis() + "-" + file
val rows: RDD[String] = withoutHeader.mapPartitions(lines => {
val parser = new CSVParser(',')
lines.map(line => {
val columns = parser.parseLine(line)
fn(columns).mkString(separator)
})
})
if (distinct) rows.distinct() saveAsTextFile tmpFile else rows.saveAsTextFile(tmpFile)
}We then call this function like this:
generateFile("/tmp/crimes.csv", withoutHeader, columns => Array(columns(0),"Crime", columns(2), columns(6)), "id:ID(Crime),:LABEL,date,description", false)The output into ‘tmpFile’ is actually 32 ‘part files’ but I wanted to be able to merge those together into individual CSV files that were easier to work with.
The full job looks like this:
import java.io.File
import au.com.bytecode.opencsv.CSVParser
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs._
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object GenerateCSVFiles {
def merge(srcPath: String, dstPath: String, header: String): Unit = {
val hadoopConfig = new Configuration()
val hdfs = FileSystem.get(hadoopConfig)
MyFileUtil.copyMergeWithHeader(hdfs, new Path(srcPath), hdfs, new Path(dstPath), false, hadoopConfig, header)
}
def main(args: Array[String]) {
var crimeFile = System.getenv("CSV_FILE")
if(crimeFile == null || !new File(crimeFile).exists()) {
throw new RuntimeException("Cannot find CSV file [" + crimeFile + "]")
}
println("Using %s".format(crimeFile))
val conf = new SparkConf().setAppName("Chicago Crime Dataset")
val sc = new SparkContext(conf)
val crimeData = sc.textFile(crimeFile).cache()
val withoutHeader: RDD[String] = dropHeader(crimeData)
generateFile("/tmp/primaryTypes.csv", withoutHeader, columns => Array(columns(5).trim(), "CrimeType"), "crimeType:ID(CrimeType),:LABEL")
generateFile("/tmp/beats.csv", withoutHeader, columns => Array(columns(10), "Beat"), "id:ID(Beat),:LABEL")
generateFile("/tmp/crimes.csv", withoutHeader, columns => Array(columns(0),"Crime", columns(2), columns(6)), "id:ID(Crime),:LABEL,date,description", false)
generateFile("/tmp/crimesPrimaryTypes.csv", withoutHeader, columns => Array(columns(0),columns(5).trim(), "CRIME_TYPE"), ":START_ID(Crime),:END_ID(CrimeType),:TYPE")
generateFile("/tmp/crimesBeats.csv", withoutHeader, columns => Array(columns(0),columns(10), "ON_BEAT"), ":START_ID(Crime),:END_ID(Beat),:TYPE")
}
def generateFile(file: String, withoutHeader: RDD[String], fn: Array[String] => Array[String], header: String , distinct:Boolean = true, separator: String = ",") = {
FileUtil.fullyDelete(new File(file))
val tmpFile = "/tmp/" + System.currentTimeMillis() + "-" + file
val rows: RDD[String] = withoutHeader.mapPartitions(lines => {
val parser = new CSVParser(',')
lines.map(line => {
val columns = parser.parseLine(line)
fn(columns).mkString(separator)
})
})
if (distinct) rows.distinct() saveAsTextFile tmpFile else rows.saveAsTextFile(tmpFile)
merge(tmpFile, file, header)
}
// http://mail-archives.apache.org/mod_mbox/spark-user/201404.mbox/%3CCAEYYnxYuEaie518ODdn-fR7VvD39d71=CgB_Dxw_4COVXgmYYQ@mail.gmail.com%3E
def dropHeader(data: RDD[String]): RDD[String] = {
data.mapPartitionsWithIndex((idx, lines) => {
if (idx == 0) {
lines.drop(1)
}
lines
})
}
}Now we need to submit the job to Spark. I’ve wrapped this in a script if you want to follow along but these are the contents:
./spark-1.1.0-bin-hadoop1/bin/spark-submit \ --driver-memory 5g \ --class GenerateCSVFiles \ --master local[8] \ target/scala-2.10/playground_2.10-1.0.jar \ $@
If we execute that we’ll get the following CSV files generated:
$ ls -alh /tmp/*.csv -rwxrwxrwx 1 markneedham wheel 3.0K 14 Apr 07:37 /tmp/beats.csv -rwxrwxrwx 1 markneedham wheel 217M 14 Apr 07:37 /tmp/crimes.csv -rwxrwxrwx 1 markneedham wheel 84M 14 Apr 07:37 /tmp/crimesBeats.csv -rwxrwxrwx 1 markneedham wheel 120M 14 Apr 07:37 /tmp/crimesPrimaryTypes.csv -rwxrwxrwx 1 markneedham wheel 912B 14 Apr 07:37 /tmp/primaryTypes.csv
Let’s have a quick check what they contain:
$ head -n 10 /tmp/beats.csv id:ID(Beat),:LABEL 1135,Beat 1421,Beat 2312,Beat 1113,Beat 1014,Beat 2411,Beat 1333,Beat 2521,Beat 1652,Beat
$ head -n 10 /tmp/crimes.csv id:ID(Crime),:LABEL,date,description 9464711,Crime,01/14/2014 05:00:00 AM,SIMPLE 9460704,Crime,01/14/2014 04:55:00 AM,ARMED: HANDGUN 9460339,Crime,01/14/2014 04:44:00 AM,TO PROPERTY 9461467,Crime,01/14/2014 04:43:00 AM,$500 AND UNDER 9460355,Crime,01/14/2014 04:21:00 AM,$500 AND UNDER 9461140,Crime,01/14/2014 03:17:00 AM,FORCIBLE ENTRY 9460361,Crime,01/14/2014 03:12:00 AM,$500 AND UNDER 9461691,Crime,01/14/2014 03:00:00 AM,HOME INVASION 9461792,Crime,01/14/2014 03:00:00 AM,OVER $500
$ head -n 10 /tmp/crimesBeats.csv :START_ID(Crime),:END_ID(Beat),:TYPE 5896915,0733,ON_BEAT 9208776,2232,ON_BEAT 8237555,0111,ON_BEAT 6464775,0322,ON_BEAT 6468868,0411,ON_BEAT 4189649,0524,ON_BEAT 7620897,0421,ON_BEAT 7720402,0321,ON_BEAT 5053025,1115,ON_BEAT
Looking good. Let’s get them imported into Neo4j:
$ ./neo4j-community-2.2.0/bin/neo4j-import --into /tmp/my-neo --nodes /tmp/crimes.csv --nodes /tmp/beats.csv --nodes /tmp/primaryTypes.csv --relationships /tmp/crimesBeats.csv --relationships /tmp/crimesPrimaryTypes.csv Nodes [*>:45.76 MB/s----------------------------------|PROPERTIES(2)=============|NODE:3|v:118.05 MB/] 4M Done in 5s 605ms Prepare node index [*RESOLVE:64.85 MB-----------------------------------------------------------------------------] 4M Done in 4s 930ms Calculate dense nodes [>:42.33 MB/s-------------------|*PREPARE(7)===================================|CALCULATOR-----] 8M Done in 5s 417ms Relationships [>:42.33 MB/s-------------|*PREPARE(7)==========================|RELATIONSHIP------------|v:44.] 8M Done in 6s 62ms Node --> Relationship [*>:??-----------------------------------------------------------------------------------------] 4M Done in 324ms Relationship --> Relationship [*LINK-----------------------------------------------------------------------------------------] 8M Done in 1s 984ms Node counts [*>:??-----------------------------------------------------------------------------------------] 4M Done in 360ms Relationship counts [*>:??-----------------------------------------------------------------------------------------] 8M Done in 653ms IMPORT DONE in 26s 517ms
Next I updated conf/neo4j-server.properties to point to my new database:
#*************************************************************** # Server configuration #*************************************************************** # location of the database directory #org.neo4j.server.database.location=data/graph.db org.neo4j.server.database.location=/tmp/my-neo
Now I can start up Neo and start exploring the data:
$ ./neo4j-community-2.2.0/bin/neo4j start
MATCH (:Crime)-[r:CRIME_TYPE]->() RETURN r LIMIT 10
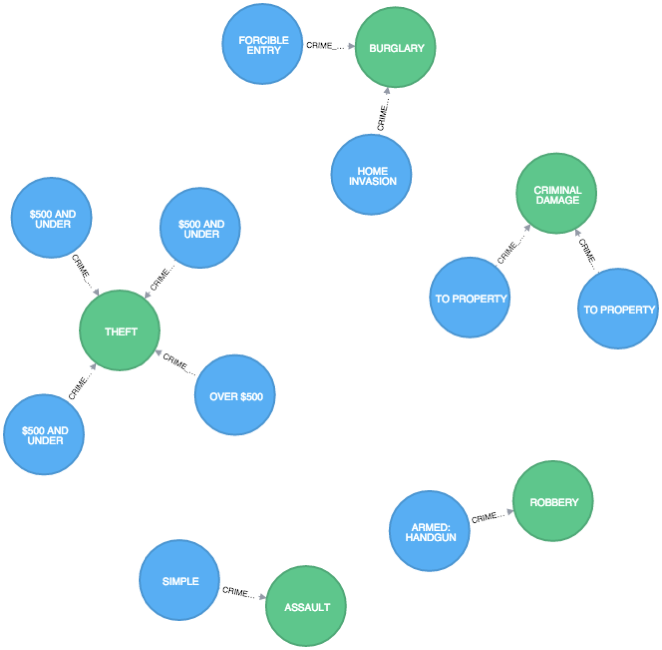
There’s lots more relationships and entities that we could pull out of this data set – what I’ve done is just a start. So if you’re up for some more Chicago crime exploration the code and instructions explaining how to run it are on github.
| Reference: | Spark: Generating CSV files to import into Neo4j from our JCG partner Mark Needham at the Mark Needham Blog blog. |

Thanks for the demo. I have a question about updating the nodes and relationships. If I have some update to the existing database files using Spark, do I need to re-import the file to the existing database? Or only update the database file is enough? Thanks very much!