This is Spring batch tutorial which is part of the Spring framework.
Spring Batch provides reusable functions that are essential in processing large volumes of records, including logging/tracing, transaction management, job processing statistics, job restart, skip, and resource management. It also provides more advanced technical services and features that will enable extremely high-volume and high-performance batch jobs through optimization and partitioning techniques.
Here, you can find a clear explanation about its main components and concepts and several working examples. This tutorial is not about the Spring framework in general; it is expected that you are familiar with mechanisms like Inversion of Control and Dependency Injection, that are the main pillars of the Spring framework. It is also assumed that you know how to configure the Spring framework context for basic applications and that you are used to work with both annotations and configuration files based Spring projects.
If this is not the case, I would really recommend going to the Spring framework official page and learn the basic tutorials before starting to learn what is Spring batch and how it works. In spring docs you can find a good one.
At the end of this tutorial, you can find a compressed file with all the examples listed and some extras.
The software used in the elaboration of this tutorial is listed below:
- Java update 8 Version 3.1
- Apache Maven 3.2.5
- Eclipse Luna 4.4.1
- Spring Batch 3.0.3 and all its dependencies (I really recommend to use Maven or Gradle to resolve all the required dependencies and avoid headaches)
- Spring Boot 1.2.2 and all its dependencies (I really recommend to use Maven or Gradle to resolve all the required dependencies and avoid headaches)
- MySQL Community Server version 5.6.22
- MongoDB 2.6.8
- HSQLDB version 1.8.0.10
Table Of Contents
This tutorial will not explain how to use Maven although it is used for solving dependencies, compiling, and executing the examples provided. You can learn more in our Log4j Maven example.
The module Spring boot is also heavily used in the examples, for more information about it please refer to the official Spring Boot documentation.
1. Introduction
Spring Batch is an open source framework for batch processing. It is built as a module within the Spring framework and depends on this framework (among others). Before continuing with Spring Batch we are going to put here the definition of batch processing:
“Batch processing is the execution of a series of programs (“jobs”) on a computer without manual intervention” (From the Wikipedia).
So, for our matter, a batch application executes a series of jobs (iterative or in parallel), where input data is read, processed and written without any interaction. We are going to see how Spring Batch can help us with this purpose.
Spring Batch provides mechanisms for processing large amount of data like transaction management, job processing, resource management, logging, tracing, conversion of data, interfaces, etc. These functionalities are available out of the box and can be reused by applications containing the Spring Batch framework. By using these diverse techniques, the framework takes care of the performance and the scalability while processing the records.
Normally a batch application can be divided in three main parts:
- Reading the data (from a database, file system, etc.)
- Processing the data (filtering, grouping, calculating, validating…)
- Writing the data (to a database, reporting, distributing…)
Spring Batch contains features and abstractions (as we will explain in this article) for automating these basic steps and allowing the application programmers to configure them, repeat them, retry them, stop them, executing them as a single element or grouped (transaction management), etc.
It also contains classes and interfaces for the main data formats, industry standards and providers like XML, CSV, SQL, Mongo DB, etc.
In the next chapters of this tutorial we are going to explain and provide examples of all these steps and the difference possibilities that Spring Batch offers.
2. Concepts
Here are the most important concepts in the Spring Batch framework:
Jobs
Jobs are abstractions to represent batch processes, that is, sequences of actions or commands that have to be executed within the batch application.
Spring batch contains an interface to represent Jobs. Simple Jobs contain a list of steps and these are executed sequentially or in parallel.
In order to configure a Job it is enough to initialize the list of steps, this is an example of an xml based configuration for a dummy Job:
<job id="eatJob" xmlns="http://www.springframework.org/schema/batch">
<step id="stepCook" next="stepEntries">
<tasklet>
<chunk reader="cookReader" writer="cookProcessor"
processor="cookWriter" commit-interval="1" />
</tasklet>
</step>
<step id="stepEntries" next="stepMeat">
<tasklet>
<chunk reader="entriesReader" writer="entriesProcessor"
processor="entriesWriter" commit-interval="1" />
</tasklet>
</step>
<step id="stepMeat" next="stepWine">
<tasklet ref="drinkSomeWine" />
</step>
<step id="stepWine" next="clean">
<tasklet>
<chunk reader="wineReader" writer="wineProcessor"
processor="wineWriter" commit-interval="1" />
</tasklet>
</step>
<step id="clean">
<tasklet ref="cleanTheTable" />
</step>
</job>
Job launcher
This interface represents a Job Launcher. Implementations of its run() method takes care of starting job executions for the given jobs and job parameters.
Job instance
This is an abstraction representing a single run for a given Job. It is unique and identifiable. The class representing this abstraction is http://docs.spring.io/spring-batch/apidocs/org/springframework/batch/core/JobInstance.html.
Job instances can be restarted in case they were not completed successfully and if the Job is restart able. Otherwise an error will be raised.
Steps
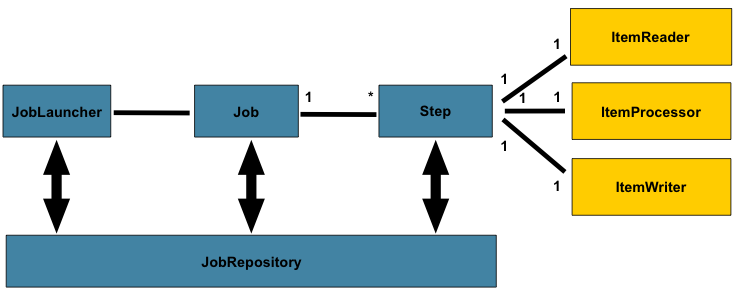
Steps are mainly the parts that compose a Job (and a Job instance). A Step is a part of a Job and contains all the necessary information to execute the batch processing actions that are expected to be done at that phase of the job. Steps in Spring Batch are composed of ItemReader, ItemProcessor and ItemWriter and can be very simple or extremely complicated depending on the complexity of their members.
Steps also contain configuration options for their processing strategy, commit interval, transaction mechanism or job repositories that may be used. Spring Batch uses normally chunk processing, that is reading all data at one time and processing and writing “chunks” of this data on a preconfigured interval, called commit interval.
Here is a very basic example of a xml based step configuration using an interval of 10:
<step id="step" next="nextStep">
<tasklet>
<chunk reader="customItemReader" writer="customItemWriter" processor="customItemProcessor" commit-interval="10" />
</tasklet>
</step>
And the following snippet is the annotation based version defining the readers, writers and processors involved, a chunk processing strategy and a commit interval of 10 (this is the one that we are using in the majority of examples in this tutorial):
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory,
ItemReader reader, ItemWriter writer,
ItemProcessor processor) {
/* it handles bunches of 10 units */
return stepBuilderFactory.get("step1")
. chunk(10).reader(reader)
.processor(processor).writer(writer).build();
}
Job Repositories
Job repositories are abstractions responsible for storing and updating metadata information related to Job instance executions and Job contexts. The basic interface that has to be implemented in order to configure a Job Repository can be found here.
Spring stores as metadata information about their executions, the results obtained their instances, the parameters used for the Jobs executed, and the context where the processing runs. The table names are very intuitive and similar to their domain classes counterparts, in this link, there is an image with a very good summary of these tables.
Please visit the Spring Batch metadata schema for more information.
Item Readers
Readers are abstractions responsible of the data retrieval. They provide batch processing applications with the needed input data. We will see in this tutorial how to create custom readers and we will see how to use some of the most important Spring Batch predefined ones. Here is a list of some readers provided by Spring Batch:
- AmqpItemReader
- AggregateItemReader
- FlatFileItemReader
- HibernateCursorItemReader
- HibernatePagingItemReader
- IbatisPagingItemReader
- ItemReaderAdapter
- JdbcCursorItemReader
- JdbcPagingItemReader
- JmsItemReader
- JpaPagingItemReader
- ListItemReader
- MongoItemReader
- Neo4jItemReader
- RepositoryItemReader
- StoredProcedureItemReader
- StaxEventItemReader
We can see that Spring Batch already provides readers for many of the formatting standards and database industry providers. It is recommended to use the abstractions provided by Spring Batch in your applications rather than creating your own ones.
Item Writers
Writers are abstractions responsible of writing the data to the desired output database or system. The same that we explained for Readers is applicable to Writers: Spring Batch already provides classes and interfaces to deal with many of the most used databases, these should be used. Here is a list of some of these provided writers:
- AbstractItemStreamItemWriter
- AmqpItemWriter
- CompositeItemWriter
- FlatFileItemWriter
- GemfireItemWriter
- HibernateItemWriter
- IbatisBatchItemWriter
- ItemWriterAdapter
- JdbcBatchItemWriter
- JmsItemWriter
- JpaItemWriter
- MimeMessageItemWriter
- MongoItemWriter
- Neo4jItemWriter
- StaxEventItemWriter
- RepositoryItemWriter
In this article we will show how to create custom writers and how to use some of the listed ones.
Item Processors
Processors are in charge of modifying the data records converting them from the input format to the output desired one. The main interfaces used for Item Processors configuration can be found here.
In this article we will see how to create our custom item processors.
The following picture (from the Spring batch documentation) gives a very good summary of all these concepts and how the basic Spring Batch architecture is designed:
3. Use Cases
Although it is difficult to categorize the use cases where batch processing can be applied in the real world, I am going to try to list in this chapter the most important ones:
- Conversion Applications: These are applications that convert input records into the required structure or format. These applications can be used in all the phases of the batch processing (reading, processing and writing).
- Filtering or validation applications: These are programs with the goal of filtering valid records for further processing. Normally validation happens in the first phases of the batch processing.
- Database extractors: These are applications that read data from a database or input files and write the desired filtered data to an output file or to other database. There are also applications that updates large amounts of data in the same database where the input records come from. As a real life example we can think of a system that analyzes log files with different end user behaviors and, using this data, produces reports with statistics about most active users, most active periods of time, etc.
- Reporting: These are applications that read large amounts of data from a database or input files, process this data and produce formatted documents based on that data that are suitable for printing or sending via other systems. Accounting and Legal Banking systems can be part of this category: at the end of the business day, these systems read information from the databases, extract the data required and write this data into legal documents that may be sent to different authorities.
Spring Batch provides mechanisms to support all these scenarios, with the elements and components listed in the previous chapter programmers can implement batch applications for conversion of data, filtering records, validation, extracting information from databases or input files and reporting.
4. Controlling flow
Before starting talking about specific Jobs and Steps I am going to show how a Spring Batch configuration class looks like. The next snippet contains a configuration class with all the components needed for batch processing using Spring Batch. It contains readers, writers, processors, job flows, steps and all other needed beans.
During this tutorial we will show how to modify this configuration class in order to use different abstractions for our different purposes. The class bellow is pasted without comments and specific code, for the working class example please go to the download section in this tutorial where you can download all the sources:
@Configuration
@EnableBatchProcessing
public class SpringBatchTutorialConfiguration {
@Bean
public ItemReader reader() {
return new CustomItemReader();
}
@Bean
public ItemProcessor processor() {
return new CustomItemProcessor();
}
@Bean
public ItemWriter writer(DataSource dataSource) {
return new CustomItemItemWriter(dataSource);
}
@Bean
public Job job1(JobBuilderFactory jobs, Step step1) {
return jobs.get("job1").incrementer(new RunIdIncrementer())
.flow(step1).end().build();
}
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory,
ItemReader reader, ItemWriter writer,
ItemProcessor processor) {
/* it handles bunches of 10 units */
return stepBuilderFactory.get("step1")
. chunk(10).reader(reader)
.processor(processor).writer(writer).build();
}
@Bean
public JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
@Bean
public DataSource mysqlDataSource() throws SQLException {
final DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost/spring_batch_annotations");
dataSource.setUsername("root");
dataSource.setPassword("root");
return dataSource;
}
...
In order to launch our spring context and execute the configured batch shown before we are going to use Spring Boot. Here is an example of a program that takes care of launching our application and initializing the Spring context with the proper configuration. This program is used with all the examples shown in this tutorial:
@SpringBootApplication
public class SpringBatchTutorialMain implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication.run(SpringBatchTutorialMain.class, args);
}
@Override
public void run(String... strings) throws Exception {
System.out.println("running...");
}
}
I am using Maven to resolve all the dependencies and launching the application using Spring boot. Here is the used pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.danibuiza.javacodegeeks</groupId>
<artifactId>Spring-Batch-Tutorial-Annotations</artifactId>
<version>0.1.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.1.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
And the goal used is:
mvn spring-boot:run
Now we are going to go through the configuration file shown above step by step. First of all we are going to explain how Jobs and Steps are executed and what rules they follow.
In the example application pasted above we can see how a Job and a first step are configured. Here we extract the related piece of code:
@Bean
public Job job1(JobBuilderFactory jobs, Step step1) {
return jobs.get("job1").incrementer(new RunIdIncrementer())
.flow(step1).end().build();
}
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory,
ItemReader reader, ItemWriter writer,
ItemProcessor processor) {
/* it handles bunches of 10 units */
return stepBuilderFactory.get("step1")
. chunk(10).reader(reader)
.processor(processor).writer(writer).build();
}
We can observe how a Job with the name “job1” is configured using just one step; in this case an step called “step1”. The class JobBuilderFactory creates a job builder and initializes the job repository. The method flow() of the class JobBuilder creates an instance of the class JobFlowBuilder using the step1 method shown. This way the whole context is initialized and the Job “job1” is executed.
The step processes (using the processor) in chunks of 10 units the CustomPojo records provided by the reader and writes them using the past writer. All dependencies are injected in runtime, Spring takes care of that since the class where all this happens is marked as a configuration class using the annotation org.springframework.context.annotation.Configuration .
5. Custom Writers, Readers and Processors
As we already mentioned in this tutorial, Spring Batch applications consist basically of three steps: reading data, processing data and writing data. We also explained that in order to support these 3 operations Spring Batch provides 3 abstractions in form of interfaces:
Programmers should implement these interfaces in order to read, process and write data in their batch application jobs and steps. In this chapter we are going to explain how to create custom implementations for these abstractions.
Custom Reader
The abstraction provided by Spring Batch for reading records of data is the interface ItemReader. It only has one method (read()) and it is supposed to be executed several times; it does not need to be thread safe, this fact is very important to know by applications using these methods.
The method read() of the interface ItemReader has to be implemented. This method expects no input parameters, is supposed to read one record of the data from the desired queue and returns it. This method is not supposed to do any transformation or data processing. If null is returned, no further data has to be read or analyzed.
public class CustomItemReader implements ItemReader {
private List pojos;
private Iterator iterator;
@Override
public CustomPojo read() throws Exception, UnexpectedInputException,
ParseException, NonTransientResourceException {
if (getIterator().hasNext()) {
return getIterator().next();
}
return null;
}
. . .
The custom reader above reads the next element in the internal list of pojos, this is only possible if the iterator is initialized or injected when the custom reader is created, if the iterator is instantiated every time the read() method is called, the job using this reader will never end and cause problems.
Custom Processor
The interface provided by Spring Batch for data processing expects one input item and produces one output item. The type of both of them can be different but does not have to be different. Producing null means that the item is not required for further processing any more in case of concatenation.
In order to implement this interface, it is only necessary to implement the process() method. Here is a dummy example:
public class CustomItemProcessor implements ItemProcessor {
@Override
public CustomPojo process(final CustomPojo pojo) throws Exception {
final String id = encode(pojo.getId());
final String desc = encode(pojo.getDescription());
final CustomPojo encodedPojo = new CustomPojo(id, desc);
return encodedPojo;
}
private String encode(String word) {
StringBuffer str = new StringBuffer(word);
return str.reverse().toString();
}
}
The class above may not be useful in any real life scenario but shows how to override the ItemProcessor interface and do whatever actions (in this case reversing the input pojo members) are needed in the process method.
Custom Writer
In order to create a custom writer programmers need to implement the interface ItemWriter. This interface only contains one method write() that expects an input item and returns void. The write method can do whatever actions are wanted: writing in the database, writing in a csv file, sending an email, creating a formatted document etc. The implementations of this interface are in charge of flushing the data and leave structures in a safe state.
Here is an example of a custom writer where the input item is written in the standard console:
public class CustomItemWriter implements ItemWriter {
@Override
public void write(List pojo) throws Exception {
System.out.println("writing Pojo " + pojo);
}
}
Also not very useful in real life, only for learning purposes.
It is also important to mention that for almost all real life scenarios Spring Batch already provides specific abstractions that cope with most of the problems. For example Spring Batch contains classes to read data from MySQL databases, or to write data to a HSQLDB database, or to convert data from XML to CSV using JAXB; and many others. The code is clean, fully tested, standard and adopted by the industry, so I can just recommend to use them.
These classes can also be overridden in our applications in order to fulfil our wishes without the need of re implement the whole logic. Implementing the provided classes by Spring may be also useful for testing, debugging, logging or reporting purposes. So before discovering the wheel again and again, it would be worth to check the Spring Batch documentation and tutorials because probably we will find a better and cleaner way to solve our specific problems.
6. Flat file example
Using the example above, we are going to modify the readers and writers in order to be able to read from a csv file and write into a flat file as well. The following snippet shows how we should configure the reader in order to provide a reader that extracts the data from a flat file, csv in this case. For this purpose Spring already provides the class FlatFileItemReader that needs a resource property where the data should be coming from and a line mapper to be able to parse the data contained in that resource. The code is quite intuitive:
@Bean
public ItemReader reader() {
if ("flat".equals(this.mode)) {
// flat file item reader (using an csv extractor)
FlatFileItemReader reader = new FlatFileItemReader();
//setting resource and line mapper
reader.setResource(new ClassPathResource("input.csv"));
reader.setLineMapper(new DefaultLineMapper() {
{
//default line mapper with a line tokenizer and a field mapper
setLineTokenizer(new DelimitedLineTokenizer() {
{
setNames(new String[] { "id", "description" });
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper() {
{
setTargetType(CustomPojo.class);
}});
}
});
return reader;
}
else {
. . .
The following piece of code shows the modifications that are needed in the writer. In this case we are going to use a writer of the class FlatFileItemWriter that needs an output file to write to and an extractor mechanism. The extractor can be configured as shown in the snippet:
@Bean
public ItemWriter writer(DataSource dataSource) {
...
else if ("flat".equals(this.mode)) {
// FlatFileItemWriter writer
FlatFileItemWriter writer = new FlatFileItemWriter ();
writer.setResource(new ClassPathResource("output.csv"));
BeanWrapperFieldExtractor fieldExtractor = new CustomFieldExtractor();
fieldExtractor.setNames(new String[] { "id", "description" });
DelimitedLineAggregator delLineAgg = new CustomDelimitedAggregator();
delLineAgg.setDelimiter(",");
delLineAgg.setFieldExtractor(fieldExtractor);
writer.setLineAggregator(delLineAgg);
return writer;
}
else {
. . .
}
7. MySQL example
In this chapter we are going to see how to modify our writer and our data source in order to write processed records to a local MySQL DB.
If we want to read data from a MySQL DB we first need to modify the configuration of the data source bean with the needed connection parameters:
@Bean
public DataSource dataSource() throws SQLException {
. . .
else if ("mysql".equals(this.mode)) {
// mysql data source
final DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost/spring_batch_annotations");
dataSource.setUsername("root");
dataSource.setPassword("root");
return dataSource;
} else {
. . .
Here is how the writer can be modified using an SQL statement and a JdbcBatchItemWriter that gets initialized with the data source shown above:
@Bean
public ItemWriter writer(DataSource dataSource) {
...
else if ("mysql".equals(this.mode)) {
JdbcBatchItemWriter writer = new JdbcBatchItemWriter();
writer.setSql("INSERT INTO pojo (id, description) VALUES (:id, :description)");
writer.setDataSource(dataSource);
writer.setItemSqlParameterSourceProvider(
new BeanPropertyItemSqlParameterSourceProvider());
return writer;
}
.. .
It is good to mention here, that there are problems with the required Jettison library.

8. In Memory DB (HSQLDB) example
As third example we are going to show how to create readers and writers in order to use an in memory database, this is very useful for testing scenarios. By default, if nothing else is specified, Spring Batch choose HSQLDB as data source.
The data source to be used is in this case the same one as for a MySQL DB but with different parameters (containing the HSQLDB configuration):
@Bean
public DataSource dataSource() throws SQLException {
. . .
} else {
// hsqldb datasource
final DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("org.hsqldb.jdbcDriver");
dataSource.setUrl("jdbc:hsqldb:mem:test");
dataSource.setUsername("sa");
dataSource.setPassword("");
return dataSource;
}
}
The writer does not differ (almost) from the MySQL one:
@Bean
public ItemWriter writer(DataSource dataSource) {
if ("hsqldb".equals(this.mode)) {
// hsqldb writer using JdbcBatchItemWriter (the difference is the
// datasource)
JdbcBatchItemWriter writer = new JdbcBatchItemWriter();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider());
writer.setSql("INSERT INTO pojo (id, description) VALUES (:id, :description)");
writer.setDataSource(dataSource);
return writer;
} else
. . .
If we want that Spring takes care of the initialization of the DB to be used we can create an script with the name schema-all.sql (for all providers, schema-hsqldb.sql for Hsqldb, schema-mysql.sql for MySQL, etc.) in the resources project of our project:
DROP TABLE IF EXISTS POJO;
CREATE TABLE POJO (
id VARCHAR(20),
description VARCHAR(20)
);
This script is also provided in the download section at the end of the tutorial.
9. Unit testing
In this chapter we are going to see briefly how to test Batch applications using the Spring Batch testing capabilities. This chapter does not explain how to test Java applications in general or Spring based ones in particular. It only covers how to test from end to end Spring Batch applications, only Jobs or Steps testing is covered; that is why unit testing of single elements like item processors, readers or writers is excluded, since this does not differ from normal unit testing.
The Spring Batch Test Project contains abstractions that facilitate the unit testing of batch applications.
Two annotations are basic when running unit tests (using Junit in this case) in Spring:
- @RunWith(SpringJUnit4ClassRunner.class): Junit annotation to execute all methods marked as tests. With the
SpringJunit4ClassRunnerclass passed as parameter we are indicating that this class can use all spring testing capabilities. - @ContextConfiguration(locations = {. . .}): we will not use the “locations” property because we are not using xml configuration files but configuration classes directly.
Instances of the class can be used for launching jobs and single steps inside the unit test methods (among many other functionalities. Its method launchJob() executes a Job and its method launchStep("name") executes an step from end to end. In the following example you can see how to use these methods in real jUnit tests:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes=SpringBatchTutorialConfiguration.class, loader=AnnotationConfigContextLoader.class)
public class SpringBatchUnitTest {
@Autowired
private JobLauncherTestUtils jobLauncherTestUtils;
@Autowired
JdbcTemplate jdbcTemplate;
@Test
public void testLaunchJob() throws Exception {
// test a complete job
JobExecution jobExecution = jobLauncherTestUtils.launchJob();
assertEquals(BatchStatus.COMPLETED, jobExecution.getStatus());
}
@Test
public void testLaunchStep() {
// test a individual step
JobExecution jobExecution = jobLauncherTestUtils.launchStep("step1");
assertEquals(BatchStatus.COMPLETED, jobExecution.getStatus());
}
}
You can assert or validate the tests checking the status of the Job execution for complete Jobs unit tests or asserting the results of the writer for single steps tests. In the example shown we do not use any xml configuration file, instead we use the already mentioned configuration class. In order to indicate the unit test to load this configuration, the annotation ContextConfiguration with the properties “classes” and “loader” is used:
@ContextConfiguration(classes=SpringBatchTutorialConfiguration.class, loader=AnnotationConfigContextLoader.class)
More information about Spring Batch unit testing can be found in the following tutorial: http://docs.spring.io/spring-batch/trunk/reference/html/testing.html.
10. Error handling and retrying Jobs
Spring provides mechanisms for retrying Jobs but since the release 2.2.0 is not anymore part of the Spring Batch framework but included in the Spring Retry. A very good tutorial can be found here.
Retry policies, callbacks and recovery mechanism are part of the framework.
11. Parallel Processing
Spring Batch supports parallel processing in two possible variations (single process and multi process) that we can separate into the following categories. In this chapter we are just going to list these categories and explain briefly how Spring Batch provides solutions to them:
- Multi-threaded Step (single process): Programmers can implement their readers and writers in a thread safe way, so multi threading can be used and the step processing can be executed in different threats. Spring batch provides out of the box several
ItemWriterandItemReaderimplementations. In their description is stated normally if they are thread safe or not. In case this information is not provided or the implementations clearly state that they are not thread safe, programmers can always synchronize the call to theread()method. This way, several records can be processed in parallel. - Parallel Steps (single process): If an application modules can be executed in parallel because their logic do not collapse, these different modules can be executed in different steps in a parallel way. This is different to the scenario explained in the last point where each step execution process different records in parallel; here, different steps run in parallel.
Spring Batch supports this scenario with the elementsplit.Here is an example configuration that may help to understand it better:<job id="havingLunchJob"> <split id="split1" task-executor="taskExecutor" next="cleanTableStep"> <flow> <step id="step1" parent="s1" next="eatCakeStep"/> <step id=" eatCakeStep " parent="s2"/> </flow> <flow> <step id="drinkWineStep" parent="s3"/> </flow> </split> <step id=" cleanTableStep" parent="parentStep1"/> . . . - Remote Chunking of Step (single process): In this mode, steps are separated in different processes, these are communicated with each other using some middleware system (for example JMX). Basically there is a master component running locally and several multiple remote processes, called slaves. The master component is a normal Spring Batch Step, its writer knows how to send chunks of items as messages using the middleware mentioned before. The slaves are implementations of item writers and item processors with the ability to process the messages. The master component should not be a bottleneck, the standard way to implement this pattern is to leave the expensive parts in the processors and writers and light parts in the readers.
- Partitioning a Step (single or multi process): Spring Batch offers the possibility to partition Steps and execute them remotely. The remote instances are Steps.
These are the main options that Spring Batch offers to programmers to allow them to process their batch applications somehow in parallel. But parallelism in general and specifically parallelism in batch processing is a very deep and complicate topic that is out of the scope of this document.
12. Repeating jobs
Spring Batch offers the possibility to repeat Jobs and Tasks in a programmatic and configurable way. In other words, it is possible to configure our batch applications to repeat Jobs or Steps until specific conditions are met (or until specific conditions are not yet met). Several abstractions are available for this purpose:
- Repeat Operations: The interface RepeatOperations is the basis for all the repeat mechanism in Spring Batch. It contains a method to be implemented where a callback is passed. This callback is executed in each iteration. It looks like the following:
public interface RepeatOperations { RepeatStatus iterate(RepeatCallback callback) throws RepeatException; }The RepeatCallback interface contains the functional logic that has to be repeated in the Batch:
public interface RepeatCallback { RepeatStatus doInIteration(RepeatContext context) throws Exception; }The
RepeatStatusreturned in theiriterate()anddoInIteration()respectively should beRepeatStatus.CONTINUABLEin case the Batch should continue iterating orRepeatStatus.FINIHSEDin case the Batch processing should be terminated.Spring already provides some basic implementations for the
RepeatCallBackinterface. - Repeat Templates: The class RepeatTemplate is a very useful implementation of the
RepeatOperationsinterface that can be used as starting point in our batch applications. It contains basic functionalities and default behavior for error handling and finalization mechanisms. Applications that do not want this default behavior should implement their custom Completion Policies.
Here is an example of how to use a repeat template with a fixed chunk termination policy and a dummy iterate method:RepeatTemplate template = new RepeatTemplate(); template.setCompletionPolicy(new FixedChunkSizeCompletionPolicy(10)); template.iterate(new RepeatCallback() { public ExitStatus doInIteration(RepeatContext context) { int x = 10; x *= 10; x /= 10; return ExitStatus.CONTINUABLE; } });In this case the batch will terminate after 10 iterations since the iterate() method returns always
CONTINUABLEand leaves the responsibility of the termination to the completion policy. - Repeat Status: Spring contains an enumeration with the possible continuation status:
RepeatStatus .CONTINUABLERepeatStatus.FINISHEDIndicating that the processing should continue or it is finished can be successful or unsuccessful. - Repeat Context: It is possible to store transient data in the Repeat Context, this context is passed as parameter to the Repeat Callback
doInIteration()method. Spring Batch provides the abstraction RepeatContext for this purpose.
After theiterate()method is called, the context no longer exists. The repeat context have a parent context in case iterations are nested, in these cases, it is possible to use the parent context in order to store information that can be shared between different iterations, like counters or decision variables. - Repeat Policy: Repeat template termination mechanism is determined by a CompletionPolicy. This policy is also in charge of creating a
RepeatContextand pass it to the callback in every iteration. Once an iteration is completed, the template calls the completion policy and updates its state, which will be stored in the repeat context. After that, the template asks the policy to check if the processing is complete.Spring contains several implementations for this interface, one of the most simple ones is the SimpleCompletionPolicy; which offers the possibility to execute the Batch just a fixed number of iterations.
13. JSR 352 Batch Applications for the Java Platform
Since Java 7, batch processing is included in the Java Platform. The JSR 352 (Batch applications for the Java Platform) specifies a model for batch applications and a runtime for scheduling and executing jobs. At the moment of writing this tutorial, the Spring Batch implementation (3.0) implements completely the specification of the JSR-352.
The domain model and the vocabulary used is pretty similar to the one used in Spring Batch.
JSR 352: Batch Applications for the Java Platform: Jobs, Steps, Chunks, Items, ItemReaders, ItemWriters, ItemProcessors etc. are present in the Java Platform JSR 352 model as well. The differences are minor between both frameworks and configuration files looks almost the same.
This is a good thing for both programmers and the industry; since the industry profits from the fact that a standard has been created in the Java Platform, using as basis a very good library like Spring Batch, which is widely used and well tested. Programmers benefit because in case Spring Batch is discontinued or cannot be used for any reason in their applications (compatibility, company policies, size restrictions…) they can choose the Java standard implementation for Batch processing without much changes in their systems.
You can learn more information about how Spring Batch has been adapter to the JSR 352.
14. Summary
So that’s it. I hope you have enjoyed it and you are able now to configure and implement batch applications using Spring Batch. I am going to summarize here the most important points explained in this article:
- Spring Batch is a batch processing framework built upon the Spring Framework.
- Mainly (simplifying!) it is composed of <code<Jobs, containing
Steps, whereReaders,ProcessorsandWritersand configured and concatenated to execute the desired actions. - Spring Batch contains mechanism that allow programmers to work with the main providers like MySQL, Mongo DB and formats like SQL, CSV or XML out of the box.
- Spring Batch contains features for error handling, repeating
JobsandStepsand retryingJobsandSteps. - It also offers possibilities for parallel processing.
- It contains classes and interfaces for batch applications unit testing.
In this tutorial I used no xml file (apart from some examples) for configuring the spring context, everything was done via annotations. I did it this way for clarity reasons but I do not recommend to do this in real life applications since xml configuration files may be useful in specific scenarios. As I said, this was a tutorial about Spring Batch and not about Spring in general.
15. Resources
The following links contain a lot of information and theoretical examples where you can learn all the features of the Spring Batch module:
- http://docs.spring.io/spring-batch/reference/html/index.html
- https://jcp.org/en/jsr/detail?id=352
- https://spring.io/guides/gs/batch-processing/
- https://kb.iu.edu/d/afrx
16. Download the Source Code
You can download the full source code of this Spring Batch Tutorial here: Spring Batch Tutorial – The ULTIMATE Guide
Last updated on Apr. 29th, 2021

{kind=link}
{kind=link}
Good work…few corrections needed.
Correct the mySQL connection string as :
jdbc:mysql://localhost:3306/spring_batch_annotations in this class:
SpringBatchTutorialConfiguration
Also refer to this:
https://github.com/spring-projects/spring-batch/blob/master/spring-batch-core/src/main/resources/org/springframework/batch/core/schema-mysql.sql
for creating the mysql tables which are needed for Springbatchframework metadata/product tables
If someone wants to skip creating those database tables if they do not have write access to the database, they can override the setDataSource() method in BatchConfig and set it to null, which prevents the spring batch from creating these tables.
it is very useful to devolper
nice website
One of the most well structured technical blog. I think you should write a book. There are lot of great developers but very few have the ability to express to clearly in most effective and least number of words. Very nice explanation. Well, coming back to the topic. There are certain doubts which result from probably overlapping of the batch process concept with other technologies. Like its necessary to explain difference of use-cases between Batch Processing, Scheduling and Messaging Services. Batch processes are sequential, Messaging services are asynchronous, Scheduling can be sequential or asynchronous. Say i need to process thousands… Read more »
Could you please only share the Spring Batch mongodb Item Reader and Writter example? regards, Neha
Its very clear and helpful for Initiators like me Im very thank ful to u.
how can i get the pdf document?
May I just say what a relief to discover somebody
that genuinely understands what they’re talking about on the internet.
You definitely know how to bring an issue to light and make
it important. More people really need to read this and understand
this side of your story. I was surprised that you are not more popular since you surely have the gift.
Very nice tutorial
How can I get this tutorial in pdf format.
Please help.
Could you please provide XML version of this same project ? I also see current code don’t have DS configuration details? please do the needful.
Thank & Regards,
Savani
How can i get the PDF version here?
Hello
Could you please share the full example including the Spring Batch’s XML configuration as well?
Could you please developed code for the Mongo DB to XML Spring Batch example ?
How we can use Oracle Database instead of Mysql ? please Help
where to download?
The zip file is at the end of the article.