Today, I bring you the second part to my previous post about Java EE 7 Batch Processing and World of Warcraft – Part 1. In this post, we are going to see how to aggregate and extract metrics from the data that we obtained in Part 1.

Recap
The batch purpose is to download the World of Warcraft Auction House’s data, process the auctions and extract metrics. These metrics are going to build a history of the Auctions Items price evolution through time. In Part 1, we already downloaded and inserted the data into a database.
The Application
Process Job
After adding the raw data into the database, we are going to add another step with a Chunk style processing. In the chunk we’re are going to read the aggregated data, and then insert it into another table in the database for easy access. This is done in the process-job.xml:
process-job.xml
<step id="importStatistics">
<chunk item-count="100">
<reader ref="processedAuctionsReader"/>
<processor ref="processedAuctionsProcessor"/>
<writer ref="processedAuctionsWriter"/>
</chunk>
</step>A Chunk reads the data one item at a time, and creates chunks that will be written out, within a transaction. One item is read in from an ItemReader, handed to an ItemProcessor, and aggregated. Once the number of items read equals the commit interval, the entire chunk is written out via the ItemWriter, and then the transaction is committed.
ProcessedAuctionsReader
In the reader, we are going to select and aggregate metrics using database functions.
ProcessedAuctionsReader.java
@Named
public class ProcessedAuctionsReader extends AbstractAuctionFileProcess implements ItemReader {
@Resource(name = "java:comp/DefaultDataSource")
protected DataSource dataSource;
private PreparedStatement preparedStatement;
private ResultSet resultSet;
@Override
public void open(Serializable checkpoint) throws Exception {
Connection connection = dataSource.getConnection();
preparedStatement = connection.prepareStatement(
"SELECT" +
" itemid as itemId," +
" sum(quantity)," +
" sum(bid)," +
" sum(buyout)," +
" min(bid / quantity)," +
" min(buyout / quantity)," +
" max(bid / quantity)," +
" max(buyout / quantity)" +
" FROM auction" +
" WHERE auctionfile_id = " +
getContext().getFileToProcess().getId() +
" GROUP BY itemid" +
" ORDER BY 1",
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY,
ResultSet.HOLD_CURSORS_OVER_COMMIT
);
// Weird bug here. Check https://java.net/bugzilla/show_bug.cgi?id=5315
//preparedStatement.setLong(1, getContext().getFileToProcess().getId());
resultSet = preparedStatement.executeQuery();
}
@Override
public void close() throws Exception {
DbUtils.closeQuietly(resultSet);
DbUtils.closeQuietly(preparedStatement);
}
@Override
public Object readItem() throws Exception {
return resultSet.next() ? resultSet : null;
}
@Override
public Serializable checkpointInfo() throws Exception {
return null;
}For this example, we get the best performance results by using plain JDBC with a simple scrollable result set. In this way, only one query is executed and results are pulled as needed in readItem. You might want to explore other alternatives.
Plain JPA doesn’t have a scrollable result set in the standards, so you need to paginate the results. This will lead to multiple queries which will slow down the reading. Another option is to use the new Java 8 Streams API to perform the aggregation operations. The operations are quick, but you need to select the entire dataset from the database into the streams. Ultimately, this will kill your performance.
I did try both approaches and got the best results by using the database aggregation capabilities. I’m not saying that this is always the best option, but in this particular case it was the best option.
During the implementation, I’ve also found a bug in Batch. You can check it here. An exception is thrown when setting parameters in the PreparedStatement. The workaround was to inject the parameters directly into the query SQL. Ugly, I know…
ProcessedAuctionsProcessor
In the processor, let’s store all the aggregated values in a holder object to store in the database.
ProcessedAuctionsProcessor.java
@Named
public class ProcessedAuctionsProcessor extends AbstractAuctionFileProcess implements ItemProcessor {
@Override
@SuppressWarnings("unchecked")
public Object processItem(Object item) throws Exception {
ResultSet resultSet = (ResultSet) item;
AuctionItemStatistics auctionItemStatistics = new AuctionItemStatistics();
auctionItemStatistics.setItemId(resultSet.getInt(1));
auctionItemStatistics.setQuantity(resultSet.getLong(2));
auctionItemStatistics.setBid(resultSet.getLong(3));
auctionItemStatistics.setBuyout(resultSet.getLong(4));
auctionItemStatistics.setMinBid(resultSet.getLong(5));
auctionItemStatistics.setMinBuyout(resultSet.getLong(6));
auctionItemStatistics.setMaxBid(resultSet.getLong(7));
auctionItemStatistics.setMaxBuyout(resultSet.getLong(8));
auctionItemStatistics.setTimestamp(getContext().getFileToProcess().getLastModified());
auctionItemStatistics.setAvgBid(
(double) (auctionItemStatistics.getBid() / auctionItemStatistics.getQuantity()));
auctionItemStatistics.setAvgBuyout(
(double) (auctionItemStatistics.getBuyout() / auctionItemStatistics.getQuantity()));
auctionItemStatistics.setRealm(getContext().getRealm());
return auctionItemStatistics;
}
}Since the metrics record an exact snapshot of the data in time, the calculation only needs to be done once. That’s why we are saving the aggregated metrics. They are never going to change and we can easily check the history.
If you know that your source data is immutable and you need to perform operations on it, I recommend that you persist the result somewhere. This is going to save you time. Of course, you need to balance if this data is going to be accessed many times in the future. If not, maybe you don’t need to go through the trouble of persisting the data.
ProcessedAuctionsWriter
Finally we just need to write the data down to a database:
ProcessedAuctionsWriter.java
@Named
public class ProcessedAuctionsWriter extends AbstractItemWriter {
@PersistenceContext
protected EntityManager em;
@Override
@SuppressWarnings("unchecked")
public void writeItems(List items) throws Exception {
List<AuctionItemStatistics> statistis = (List<AuctionItemStatistics>) items;
statistis.forEach(em::persist);
}
}Metrics
Now, to do something useful with the data we are going to expose a REST endpoint to perform queries on the calculated metrics. Here is how:
WowBusinessBean.java
@Override @GET
@Path("items")
public List<AuctionItemStatistics> findAuctionItemStatisticsByRealmAndItem(@QueryParam("realmId") Long realmId,
@QueryParam("itemId") Integer itemId) {
Realm realm = (Realm) em.createNamedQuery("Realm.findRealmsWithConnectionsById")
.setParameter("id", realmId)
.getSingleResult();
// Workaround for https://bugs.eclipse.org/bugs/show_bug.cgi?id=433075 if using EclipseLink
List<Realm> connectedRealms = new ArrayList<>();
connectedRealms.addAll(realm.getConnectedRealms());
List<Long> ids = connectedRealms.stream().map(Realm::getId).collect(Collectors.toList());
ids.add(realmId);
return em.createNamedQuery("AuctionItemStatistics.findByRealmsAndItem")
.setParameter("realmIds", ids)
.setParameter("itemId", itemId)
.getResultList();
}If you remember a few details of Part 1 post, World of Warcraft servers are called Realms. These realms can be linked with each other and share the same Auction House. To that end, we also have information on how the realms connect with each other. This is important, because we can search for an Auction Item in all the realms that are connected. The rest of the logic is just simple queries to get the data out.
During development, I’ve also found a bug with Eclipse Link (if you run in Glassfish) and Java 8. Apparently the underlying Collection returned by Eclipse Link has the element count set to 0. This doesn’t work well with Streams if you try to inline the query call plus a Stream operation. The Stream will think that it’s empty and no results are returned. You can read a little more about this here.
Interface
I’ve also developed a small interface using Angular and Google Charts to display the metrics. Have a look:
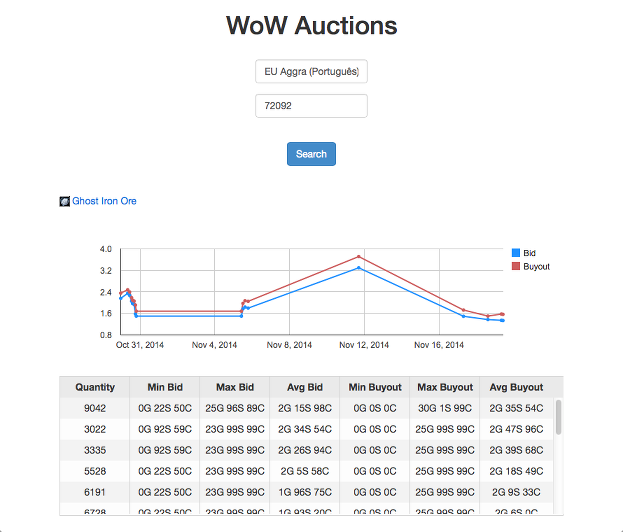
In here, I’m searching in the Realm named “Aggra (Português)” and the Auction Item id 72092 which corresponds to Ghost Iron Ore. As you can see, we can check the quantity for sale, bid and buyout values and price fluctuation through time. Neat? I may write another post about building the Web Interface in the future.
Resources
You can clone a full working copy from my github repository and deploy it to Wildfly or Glassfish. You can find instructions there to deploy it: World of Warcraft Auctions
Check also the Java EE samples project, with a lot of batch examples, fully documented.
| Reference: | Java EE 7 Batch Processing and World of Warcraft – Part 2 from our JCG partner Roberto Cortez at the Roberto Cortez Java Blog blog. |
