Data as a Service: JBoss Data Virtualization and Hadoop powering your Big Data solutions
Red Hat and Cloudera, announce the formation of a strategic alliance. From JBoss perspective, the key objective of the alliance is to leverage big data enterprise-wide and not let Hadoop become another data silo. Cloudera combined with Red Hat JBoss Data Virtualization integrates Hadoop with existing information sources including data warehouses, SQL and NoSQL databases, enterprise and cloud applications, and flat and XML files. The solution creates business-friendly, reusable and virtual data models with unified views by combining and transforming data from multiple sources including Hadoop. This creates integrated data available on-demand for external applications through standard SQL and web services interfaces.
The reality at vast majority of organization is that data is spread across too many applications and systems. Most organizations don’t know what they’ve lost because their data is fragmented across the organization. This problem does not go away just because an organization is using big data technology like Hadoop; in fact, they get more complicated. Some organizations try to solve this problem by hard coding the access to data stores. This simple approach inefficiently breaks down silos and brings lock-in with it. Lock-in makes applications less portable, a key metric for future proofing IT. This approach also impedes organizational agility because hard coding data store access is time consuming and makes IT more complex, incurring technical debt. Successful business need to break down the data silos and make data accessible to all the applications and stakeholders (often a requirement for real time contextual services).
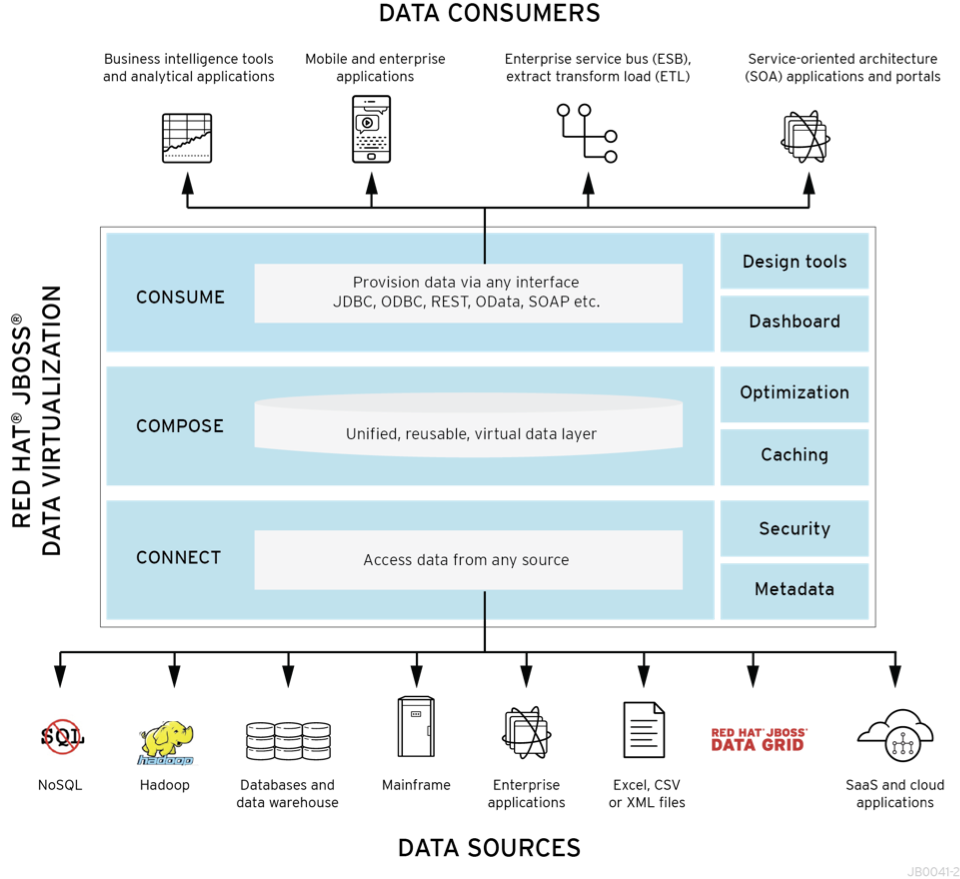
A much better approach to solving this problem is abstraction through data virtualization. It is a powerful tool, well suited for the loose coupling approach prescribed by the Modern Enterprise Model. Data virtualization helps applications retrieve and manipulate data without needing to know technical details about each data store. When implemented, organizational data can be easily accessed using a simple REST API or via familiar SQL interface.
Data Virtualization (or an abstracted Data as a Service) plugs into the Modern Enterprise Platform as a higher-order layer, offering the following advantages:
- Better business decisions due to organization wide accessibility of all data
- Higher organizational agility
- Loosely coupled services making future proofing easier
- Lower cost
Data virtualization is therefore a critical part of the big data solution. It facilitates and improves the use of big data in the enterprise by:
- Abstracting big data into relational-like views
- Integration with existing enterprise sources
- Adding real time query capabilities to big data
- Providing full support for standard based interfaces like REST and OData in addition JDBC and ODBC.
- Adding security and governance to the big data infrastructure
- Flattening data siloes through a unified data layer.
If you want to learn more, download, and get started with JBoss Data Virtualization, then visit: http://www.jboss.org/products/datavirt
Data Virtualization by Example: https://github.com/datavirtualizationbyexample
If you’re interested in community version, then visit: http://teiid.jboss.org/
| Reference: | Data as a Service: JBoss Data Virtualization and Hadoop powering your Big Data solutions from our JCG partner Arun Gupta at the Miles to go 2.0 … blog. |
