When writing unit tests we mostly focus on business correctness. We do our best to exercise happy path and all edge cases. We sometimes microbenchmark and measure throughput. But one aspect that is often missed is how our code behaves when the input is excessively large? We test how we handle normal input files, malformed files, empty files, missing files… but what about insanely large input files?
Let’s start from a real-life use case. You were given a task to implement GPX (GPS Exchange Format, basically XML) to JSON transformation. I chose GPX for no particular reason, it’s just another XML format that you might have come across e.g. when recording your hike or bicycle ride with GPS receiver. Also I thought it will be nice to use some standard rather than yet another “people database” in XML. Inside GPX file there are hundreds of flat <wpt/> entries, each one representing one point in space-time:
<gpx>
<wpt lat="42.438878" lon="-71.119277">
<ele>44.586548</ele>
<time>2001-11-28T21:05:28Z</time>
<name>5066</name>
<desc><![CDATA[5066]]></desc>
<sym>Crossing</sym>
<type><![CDATA[Crossing]]></type>
</wpt>
<wpt lat="42.439227" lon="-71.119689">
<ele>57.607200</ele>
<time>2001-06-02T03:26:55Z</time>
<name>5067</name>
<desc><![CDATA[5067]]></desc>
<sym>Dot</sym>
<type><![CDATA[Intersection]]></type>
</wpt>
<!-- ...more... -->
</gpx>
Full example: www.topografix.com/fells_loop.gpx. Our task is to extract each individual <wpt/> element, discard those without lat or lon attributes and store back JSON in the following format:
[
{"lat": 42.438878,"lon": -71.119277},
{"lat": 42.439227,"lon": -71.119689}
...more...
]
That’s easy! First of all I started with generating JAXB classes using xjc utility from JDK and GPX 1.0 XSD schema. Please note that GPX 1.1 is the most recent version as of this writing, but examples I got use 1.0. For JSON marshalling I used Jackson. The complete, working and tested program looks like this:
import org.apache.commons.io.FileUtils;
import org.codehaus.jackson.map.ObjectMapper;
import javax.xml.bind.JAXBException;
public class GpxTransformation {
private final ObjectMapper jsonMapper = new ObjectMapper();
private final JAXBContext jaxbContext;
public GpxTransformation() throws JAXBException {
jaxbContext = JAXBContext.newInstance("com.topografix.gpx._1._0");
}
public void transform(File inputFile, File outputFile) throws JAXBException, IOException {
final List<Gpx.Wpt> waypoints = loadWaypoints(inputFile);
final List<LatLong> coordinates = toCoordinates(waypoints);
dumpJson(coordinates, outputFile);
}
private List<Gpx.Wpt> loadWaypoints(File inputFile) throws JAXBException, IOException {
String xmlContents = FileUtils.readFileToString(inputFile, UTF_8);
final Unmarshaller unmarshaller = jaxbContext.createUnmarshaller();
final Gpx gpx = (Gpx) unmarshaller.unmarshal(new StringReader(xmlContents));
return gpx.getWpt();
}
private static List<LatLong> toCoordinates(List<Gpx.Wpt> waypoints) {
return waypoints
.stream()
.filter(wpt -> wpt.getLat() != null)
.filter(wpt -> wpt.getLon() != null)
.map(LatLong::new)
.collect(toList());
}
private void dumpJson(List<LatLong> coordinates, File outputFile) throws IOException {
final String resultJson = jsonMapper.writeValueAsString(coordinates);
FileUtils.writeStringToFile(outputFile, resultJson);
}
}
class LatLong {
private final double lat;
private final double lon;
LatLong(Gpx.Wpt waypoint) {
this.lat = waypoint.getLat().doubleValue();
this.lon = waypoint.getLon().doubleValue();
}
public double getLat() { return lat; }
public double getLon() { return lon; }
}
Looks fairly good, despite few traps I left intentionally. We load GPX XML file, extract waypoints to a List, transform that list into lightweight LatLong objects, first filtering out broken waypoints. Finally we dump List<LatLong> back to disk. However one day extremely long bicycle ride crashed our system with OutOfMemoryError. Do you know what happened? The GPX file uploaded to our application was huge, much bigger then we ever expected to receive. Now look again at the implementation above and count in how many places we allocate more memory then necessary?
But if you want to refactor immediately, stop right there! We want to practice TDD, right? And we want to limit WTF/minute factor in our code? I have a theory that many “WTFs” are not caused by careless and inexperienced programmers. Often it’s because of these late Friday production issues, totally unexpected inputs and unpredicted side effects. Code gets more and more workarounds, hard to understand refactorings, logic more complex then one might anticipate. Sometimes bad code was not intended, but required given circumstances we had long forgotten. So if one day you see null check that can’t possible happen or hand-written code that could’ve been replaced by a library – think about the context. That being said let’s start from writing tests proving our future refactorings are needed. If one day someone “fixes” our code, assuming “this stupid programmer” complicated things without good reason, automated tests will tell precisely why.
Our test will simply try to transform insanely big input files. But before we begin we must refactor the original implementation a bit, so that it accapets InputStream and OutputStream rather than input and output Files – there is no reason to limit our implementation to file system only:
Step 0a: Make it testable
import org.apache.commons.io.IOUtils;
public class GpxTransformation {
//...
public void transform(File inputFile, File outputFile) throws JAXBException, IOException {
try (
InputStream input =
new BufferedInputStream(new FileInputStream(inputFile));
OutputStream output =
new BufferedOutputStream(new FileOutputStream(outputFile))) {
transform(input, output);
}
}
public void transform(InputStream input, OutputStream output) throws JAXBException, IOException {
final List<Gpx.Wpt> waypoints = loadWaypoints(input);
final List<LatLong> coordinates = toCoordinates(waypoints);
dumpJson(coordinates, output);
}
private List<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException {
String xmlContents = IOUtils.toString(input, UTF_8);
final Unmarshaller unmarshaller = jaxbContext.createUnmarshaller();
final Gpx gpx = (Gpx) unmarshaller.unmarshal(new StringReader(xmlContents));
return gpx.getWpt();
}
//...
private void dumpJson(List<LatLong> coordinates, OutputStream output) throws IOException {
final String resultJson = jsonMapper.writeValueAsString(coordinates);
output.write(resultJson.getBytes(UTF_8));
}
}
Step 0b: Writing input (stress) test
Input will be generated from scratch using repeat(byte[] sample, int times) utility developed earlier. We will basically repeat the same <wpt/> item millions of times, wrapping it with GPX header and footer so that it is well-formed. Normally I would consider placing samples in src/test/resources, but I wanted this code to be self-containing. Notice that we neither care about the actual input, nor output. This is already tested. If transformation succeeds (we can add some timeout if we want), it’s OK. If it fails with any exception, most likely OutOfMemoryError, it’s a test failure (error):
import org.apache.commons.io.FileUtils
import org.apache.commons.io.output.NullOutputStream
import spock.lang.Specification
import spock.lang.Unroll
import static org.apache.commons.io.FileUtils.ONE_GB
import static org.apache.commons.io.FileUtils.ONE_KB
import static org.apache.commons.io.FileUtils.ONE_MB
@Unroll
class LargeInputSpec extends Specification {
final GpxTransformation transformation = new GpxTransformation()
final byte[] header = """<?xml version="1.0"?>
<gpx
version="1.0"
creator="ExpertGPS 1.1 - http://www.topografix.com"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.topografix.com/GPX/1/0"
xsi:schemaLocation="http://www.topografix.com/GPX/1/0 http://www.topografix.com/GPX/1/0/gpx.xsd">
<time>2002-02-27T17:18:33Z</time>
""".getBytes(UTF_8)
final byte[] gpxSample = """
<wpt lat="42.438878" lon="-71.119277">
<ele>44.586548</ele>
<time>2001-11-28T21:05:28Z</time>
<name>5066</name>
<desc><![CDATA[5066]]></desc>
<sym>Crossing</sym>
<type><![CDATA[Crossing]]></type>
</wpt>
""".getBytes(UTF_8)
final byte[] footer = """</gpx>""".getBytes(UTF_8)
def "Should not fail with OOM for input of size #readableBytes"() {
given:
int repeats = size / gpxSample.length
InputStream xml = withHeaderAndFooter(
RepeatedInputStream.repeat(gpxSample, repeats))
expect:
transformation.transform(xml, new NullOutputStream())
where:
size << [ONE_KB, ONE_MB, 10 * ONE_MB, 100 * ONE_MB, ONE_GB, 8 * ONE_GB, 32 * ONE_GB]
readableBytes = FileUtils.byteCountToDisplaySize(size)
}
private InputStream withHeaderAndFooter(InputStream samples) {
InputStream withHeader = new SequenceInputStream(
new ByteArrayInputStream(header), samples)
return new SequenceInputStream(
withHeader, new ByteArrayInputStream(footer))
}
}
There are actually 7 tests here, running GPX to JSON transformation for inputs of size: 1 KiB, 1 MiB, 10 MiB, 100 MiB, 1 GiB, 8 GiB and 32 GiB. I run these tests on JDK 8u11x64 with the following options: -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xmx1g. 1 GiB of memory is a lot, but clearly can’t fit the whole input file in memory:
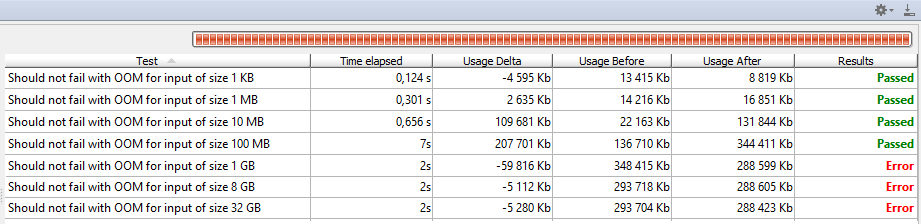
While small tests are passing, inputs above 1 GiB are failing fast.
Step 1: Avoid keeping whole files in Strings
The stack trace reveals where the problem lies:
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3326)
at java.lang.AbstractStringBuilder.expandCapacity(AbstractStringBuilder.java:137)
at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:121)
at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:569)
at java.lang.StringBuilder.append(StringBuilder.java:190)
at org.apache.commons.io.output.StringBuilderWriter.write(StringBuilderWriter.java:138)
at org.apache.commons.io.IOUtils.copyLarge(IOUtils.java:2002)
at org.apache.commons.io.IOUtils.copyLarge(IOUtils.java:1980)
at org.apache.commons.io.IOUtils.copy(IOUtils.java:1957)
at org.apache.commons.io.IOUtils.copy(IOUtils.java:1907)
at org.apache.commons.io.IOUtils.toString(IOUtils.java:778)
at com.nurkiewicz.gpx.GpxTransformation.loadWaypoints(GpxTransformation.java:56)
at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:50)
loadWaypoints eagerly loads input GPX file into a String (see: IOUtils.toString(input, UTF_8)) to later parse it. That’s kind of dumb, especially since JAXB Unmarshaller can easily read InputStream directly. Let’s fix it:
private List<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException {
final Unmarshaller unmarshaller = jaxbContext.createUnmarshaller();
final Gpx gpx = (Gpx) unmarshaller.unmarshal(input);
return gpx.getWpt();
}
private void dumpJson(List<LatLong> coordinates, OutputStream output) throws IOException {
jsonMapper.writeValue(output, coordinates);
}
Similarly we fixed dumpJson as it was first dumping JSON into String and later copying that String intoOutputStream. Results are slightly better, but again 1 GiB fails, this time by going into infinite death loop of Full GC and finally throwing:
java.lang.OutOfMemoryError: Java heap space
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.LeafPropertyLoader.text(LeafPropertyLoader.java:50)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallingContext.text(UnmarshallingContext.java:527)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.SAXConnector.processText(SAXConnector.java:208)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.SAXConnector.endElement(SAXConnector.java:171)
at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.endElement(AbstractSAXParser.java:609)
[...snap...]
at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:649)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal0(UnmarshallerImpl.java:243)
at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal(UnmarshallerImpl.java:214)
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:157)
at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:204)
at com.nurkiewicz.gpx.GpxTransformation.loadWaypoints(GpxTransformation.java:54)
at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:47)
Step 2: (Poorly) replacing JAXB with StAX
We can suspect that main issue now is XML parsing using JAXB, which always eagerly maps the whole XML file into Java objects. It’s easy to imagine why turning a 1 GiB file into object graph fails. We would like to somehow take more control over reading XML and consuming it in chunks. SAX was traditionally used in such circumstances, however the push programming model in SAX API is very inconvenient. SAX uses callback mechanism, which is very invasive and not very readable. StAX (Streaming API for XML), working on a slightly higher level, exposes pull model. It means client code decides when, and how much input to consume. This gives us better control over input and allows more flexibility. To familiarize you with the API, here is almost equivalent code to loadWaypoints(), but I skip attributes of <wpt/>which aren’t needed later:
private List<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException, XMLStreamException {
final XMLInputFactory factory = XMLInputFactory.newInstance();
final XMLStreamReader reader = factory.createXMLStreamReader(input);
final List<Gpx.Wpt> waypoints = new ArrayList<>();
while (reader.hasNext()) {
switch (reader.next()) {
case XMLStreamConstants.START_ELEMENT:
if (reader.getLocalName().equals("wpt")) {
waypoints.add(parseWaypoint(reader));
}
break;
}
}
return waypoints;
}
private Gpx.Wpt parseWaypoint(XMLStreamReader reader) {
final Gpx.Wpt wpt = new Gpx.Wpt();
final String lat = reader.getAttributeValue("", "lat");
if (lat != null) {
wpt.setLat(new BigDecimal(lat));
}
final String lon = reader.getAttributeValue("", "lon");
if (lon != null) {
wpt.setLon(new BigDecimal(lon));
}
return wpt;
}
See how we explicitly ask XMLStreamReader for more data? However the fact that we are using more low-level API (and a lot more code) doesn’t mean it has to be better if used incorrectly. We keep building huge waypoints list, so it’s not a surprise we again see OutOfMemoryError:
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3204)
at java.util.Arrays.copyOf(Arrays.java:3175)
at java.util.ArrayList.grow(ArrayList.java:246)
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:220)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:212)
at java.util.ArrayList.add(ArrayList.java:443)
at com.nurkiewicz.gpx.GpxTransformation.loadWaypoints(GpxTransformation.java:65)
at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:52)
Exactly where we anticipated. The good news is that 1 GiB test passed (with 1 GiB heap), so we are sort of going in the right direction. But it took 1 minute to complete due to excessive GC.
Step 3: StAX implemented properly
Notice that implementation using StAX in previous example would be just as good with SAX. However the reason I chose StAX was that we can now turn an XML file into an Iterator<Gpx.Wpt>. This iterator will consume XML file in chunks, lazily and only when asked. We can later consume that iterator lazily as well, which means we no longer keep whole file in memory. Iterators, while clumsy to work with, are still much better than working with XML directly or with SAX callbacks:
import com.google.common.collect.AbstractIterator;
private Iterator<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException, XMLStreamException {
final XMLInputFactory factory = XMLInputFactory.newInstance();
final XMLStreamReader reader = factory.createXMLStreamReader(input);
return new AbstractIterator<Gpx.Wpt>() {
@Override
protected Gpx.Wpt computeNext() {
try {
return tryPullNextWaypoint();
} catch (XMLStreamException e) {
throw Throwables.propagate(e);
}
}
private Gpx.Wpt tryPullNextWaypoint() throws XMLStreamException {
while (reader.hasNext()) {
int event = reader.next();
switch (event) {
case XMLStreamConstants.START_ELEMENT:
if (reader.getLocalName().equals("wpt")) {
return parseWaypoint(reader);
}
break;
case XMLStreamConstants.END_ELEMENT:
if (reader.getLocalName().equals("gpx")) {
return endOfData();
}
break;
}
}
throw new IllegalStateException("XML file didn't finish with </gpx> element, malformed?");
}
};
}
This is getting complex! I’m using AbstractIterator from Guava to handle tedious hasNext() state. Every time someone tries to pull next Gpx.Wpt item from an iterator (or call hasNext()) we consume a little bit of XML, just enough to return one entry. If XMLStreamReader encounters end of XML (</gpx> tag), we signal iterator end by returning endOfData(). This is a very handy pattern where XML is read lazily and served via convenient iterator. This implementation alone consumes very little, constant amount of memory. However we changed the API fromList<Gpx.Wpt> to Iterator<Gpx.Wpt>, which forces changes to the rest of our implementation:
private static List<LatLong> toCoordinates(Iterator<Gpx.Wpt> waypoints) {
final Spliterator<Gpx.Wpt> spliterator =
Spliterators.spliteratorUnknownSize(waypoints, Spliterator.ORDERED);
return StreamSupport
.stream(spliterator, false)
.filter(wpt -> wpt.getLat() != null)
.filter(wpt -> wpt.getLon() != null)
.map(LatLong::new)
.collect(toList());
}
toCoordinates() was previously accepting List<Gpx.Wpt>. Iterators can’t be turned into Stream directly, so we need this clunky transformation through Spliterator. Do you think it’s over? ! GiB test passes a little bit faster, but more demanding ones are failing just like before:
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3175)
at java.util.ArrayList.grow(ArrayList.java:246)
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:220)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:212)
at java.util.ArrayList.add(ArrayList.java:443)
at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175)
at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175)
at java.util.Iterator.forEachRemaining(Iterator.java:116)
at java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:512)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:502)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at com.nurkiewicz.gpx.GpxTransformation.toCoordinates(GpxTransformation.java:118)
at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:58)
at com.nurkiewicz.LargeInputSpec.Should not fail with OOM for input of size #readableBytes(LargeInputSpec.groovy:49)
Remember that OutOfMemoryError is not always thrown from a place that actually consumes most memory. Luckily it’s not the case this time. Look carefully to the bottom: collect(toList()).
Step 4: Avoiding streams and collectors
This is disappointing. Streams and collectors were designed from the ground up to support laziness. However it’s virtually impossible to implement a collector (see also: Introduction to writing custom collectors in Java 8 and Grouping, sampling and batching – custom collectors) from stream to iterator effectively, which is a big design flaw. Therefore we must forget about streams altogether and use plain iterators all the way down. Iterators aren’t very elegant, but allow consuming input item-by-item, having full control over memory consumption. We need a way to filter() input iterator, discarding broken items and map() entries to another representation. Guava, again, provides few handy utilities for that, replacing stream() completely:
private static Iterator<LatLong> toCoordinates(Iterator<Gpx.Wpt> waypoints) {
final Iterator<Gpx.Wpt> filtered = Iterators
.filter(waypoints, wpt ->
wpt.getLat() != null &&
wpt.getLon() != null);
return Iterators.transform(filtered, LatLong::new);
}
Iterator<Gpx.Wpt> in, Iterator<LatLong> out. No processing was done, XML file was barely touched, marginal memory consumption. We are lucky, Jackson accepts iterators and transparently reads them, producing JSON iteratively. Thus, memory consumption is kept low as well. Guess what, we made it!
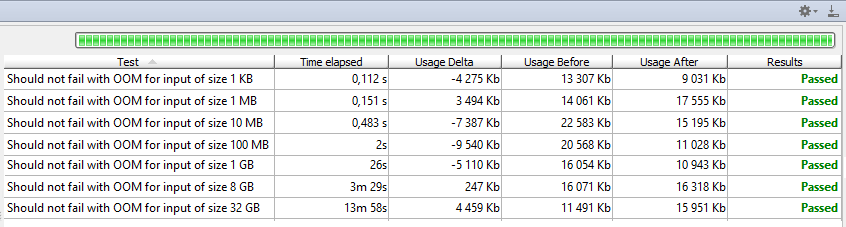
Memory consumption is low and stable, I think we can safely assume it’s constant. Our code processes about 40 MiB/s, so don’t be surprised by almost 14 minutes it took to process 32 GiB. Oh, and did I mention that I run the last test with -Xmx32M? That’s right, processing 32 GiB was successful without any performance loss using thousand times less memory. And 3000 times less, compared to initial implementation. As a matter of fact the last solution using iterators is capable of handling even infinite streams of XML. It’s not really just theoretical case, imagine some sort of streaming API that produces never-ending flow of messages…
Final implementation
This is our code in it’s entirety:
package com.nurkiewicz.gpx;
import com.google.common.base.Throwables;
import com.google.common.collect.AbstractIterator;
import com.google.common.collect.Iterators;
import com.topografix.gpx._1._0.Gpx;
import org.codehaus.jackson.map.ObjectMapper;
import javax.xml.bind.JAXBException;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.XMLStreamException;
import javax.xml.stream.XMLStreamReader;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.math.BigDecimal;
import java.util.Iterator;
public class GpxTransformation {
private static final ObjectMapper jsonMapper = new ObjectMapper();
public void transform(File inputFile, File outputFile) throws JAXBException, IOException, XMLStreamException {
try (
InputStream input =
new BufferedInputStream(new FileInputStream(inputFile));
OutputStream output =
new BufferedOutputStream(new FileOutputStream(outputFile))) {
transform(input, output);
}
}
public void transform(InputStream input, OutputStream output) throws JAXBException, IOException, XMLStreamException {
final Iterator<Gpx.Wpt> waypoints = loadWaypoints(input);
final Iterator<LatLong> coordinates = toCoordinates(waypoints);
dumpJson(coordinates, output);
}
private Iterator<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException, XMLStreamException {
final XMLInputFactory factory = XMLInputFactory.newInstance();
final XMLStreamReader reader = factory.createXMLStreamReader(input);
return new AbstractIterator<Gpx.Wpt>() {
@Override
protected Gpx.Wpt computeNext() {
try {
return tryPullNextWaypoint();
} catch (XMLStreamException e) {
throw Throwables.propagate(e);
}
}
private Gpx.Wpt tryPullNextWaypoint() throws XMLStreamException {
while (reader.hasNext()) {
int event = reader.next();
switch (event) {
case XMLStreamConstants.START_ELEMENT:
if (reader.getLocalName().equals("wpt")) {
return parseWaypoint(reader);
}
break;
case XMLStreamConstants.END_ELEMENT:
if (reader.getLocalName().equals("gpx")) {
return endOfData();
}
break;
}
}
throw new IllegalStateException("XML file didn't finish with </gpx> element, malformed?");
}
};
}
private Gpx.Wpt parseWaypoint(XMLStreamReader reader) {
final Gpx.Wpt wpt = new Gpx.Wpt();
final String lat = reader.getAttributeValue("", "lat");
if (lat != null) {
wpt.setLat(new BigDecimal(lat));
}
final String lon = reader.getAttributeValue("", "lon");
if (lon != null) {
wpt.setLon(new BigDecimal(lon));
}
return wpt;
}
private static Iterator<LatLong> toCoordinates(Iterator<Gpx.Wpt> waypoints) {
final Iterator<Gpx.Wpt> filtered = Iterators
.filter(waypoints, wpt ->
wpt.getLat() != null &&
wpt.getLon() != null);
return Iterators.transform(filtered, LatLong::new);
}
private void dumpJson(Iterator<LatLong> coordinates, OutputStream output) throws IOException {
jsonMapper.writeValue(output, coordinates);
}
}
Summary (TL;DR)
If you were not patient enough to follow all steps, here are three main takeaways:
- Your first goal is simplicity. Initial JAXB implementation was perfectly fine (with minor modifications), keep it like that if your code doesn’t have to handle large inputs.
- Test your code against insanely large inputs, e.g. using generated
InputStream, producing gigabytes of input. Huge data set is another example of edge case. Don’t test manually, once. One careless change or “improvement” might ruin your performance down the road. - Optimization is not an excuse for writing poor code. Notice that our implementation is still composable and easy to follow. If we went through SAX and simply inlined all logic in SAX callbacks, maintainability would greatly suffer.
| Reference: | Testing code for excessively large inputs from our JCG partner Tomasz Nurkiewicz at the Java and neighbourhood blog. |
