In the previous two posts on use cases for Elasticsearch we have seen that Elasticsearch can be used to store even large amounts of documents and that we can access those using the full text features of Lucene via the Query DSL. In this shorter post we will put both of use cases together to see how read heavy applications can benefit from Elasticsearch.
Search Engines in Classic Applications
Looking at classic applications search engines were a specialized thing that was only responsible for helping with one feature, the search page.
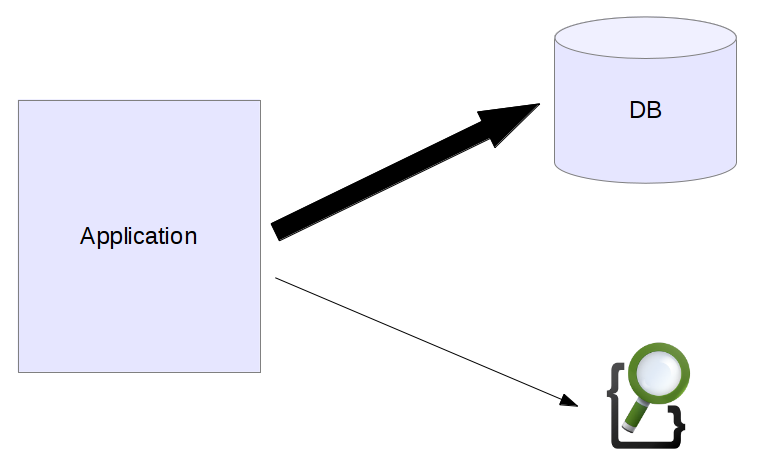
On the left we can see our application, most of its functionality is build by querying the database. The search engine only plays a minor part and is responsible for rendering the search page.
Databases are well suited for lots of types of applications but it turns out that often it is not that easy to scale them. Websites with high traffic peaks often have some problems scaling database access. Indexing and scaling machines up can help but often requires specialized knowledge and can become rather expensive.
As with other search features especially ecommerce providers started doing something different. They started to employ the search engine not only for full text search but also for other parts of the page that require no direct keyword input by the user. Again, let’s have a look at a page at Amazon.
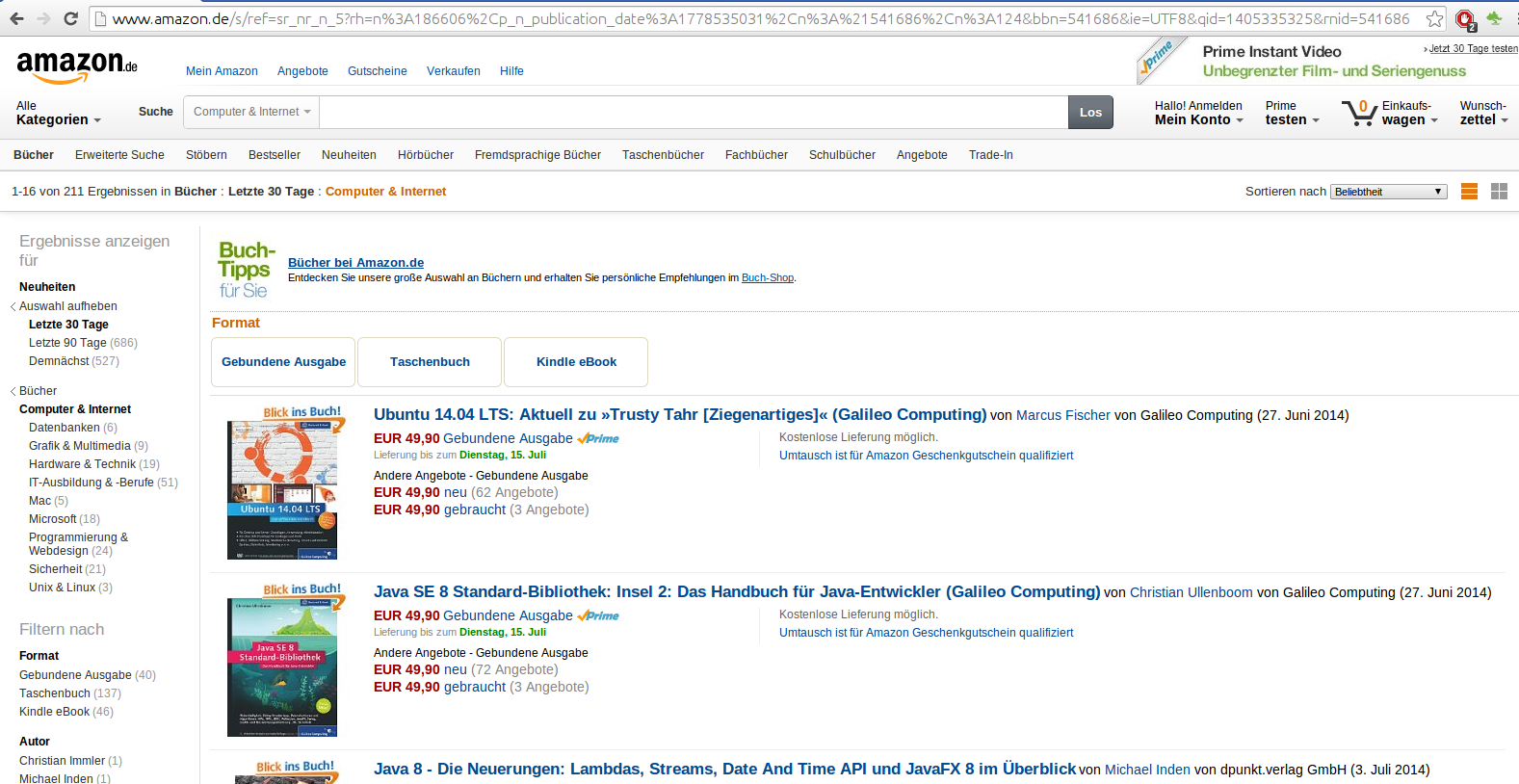
This is one of the category pages that can be accessed using the navigation. We can already see that the interface looks very similar to a search result page. There is a result list, we can sort and filter the results using the facets. Though of course I have no insight how Amazon is doing this exactly a common approach is to use the search engine for pages like this as well.
Scaling Read Requests
A common problem for ecommerce websites is that there are huge traffic spikes. Depending on your kind of business you might have a lot more traffic just before christmas. Or you might have to fight spikes when there are TV commercials for your service or any special discounts. Flash sale sites are at the extreme end of those kind of sites with very high spikes at a certain point in time when a sale starts.
It turns out that search engines are good at being queried a lot. The immutable data set, the segments, are very cache friendly. When it comes to filters those can be cached by the engine as well most of the times. On a warm index most of the data will be in RAM so it is lightning fast.
Back to our example of talks that can be accessed online. Imagine a navigation where the user can choose the city she wants to see events for. You can then issue a query like this to Elasticsearch:
curl -XPOST "http://localhost:9200/conferences/_search " -d'
{
"filter": {
"term": {
"conference.city": "stuttgart"
}
}
}'There is no query part but only a filter that limits the results to the talks that are in Stuttgart. The whole filter will be cached so if a lot of users are accessing the data there can be a huge performance gain for you and especially your users.
Additionally as we have seen new nodes can be added to Elasticsearch without a lot of hassle. If we need more query capacity we can easily add more machines and more replicas, even temporarily. When we can identify some pages that can be moved to the search engine the database doesn’t need to have that much traffic anymore.
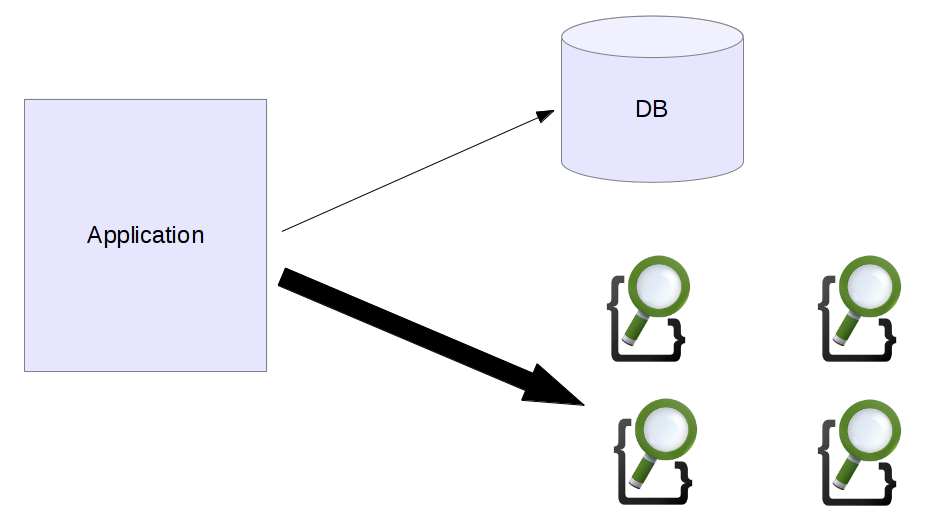
Especially for getting the huge spikes under control it is best to try to not access the database anymore for read heavy pages and deliver all of the content from the search engine.
Conclusion
Though in this post we have looked at ecommerce the same strategy can be applied to different domains. Content management systems can push the editorial content to search engines and let those be responsible for scaling. Classifieds, social media aggregation, …. All of those can benefit from the cache friendly nature of a search engine. Maybe you will even notice that parts of your data don’t need to be in the database at all and you can migrate them to Elasticsearch as a primary data store. A first step to polyglot persistence.
| Reference: | Use Cases for Elasticsearch: Flexible Query Cache from our JCG partner Florian Hopf at the Dev Time blog. |

“Elasticsearch as a primary data store”…
if your data is important, be very careful if you want to use ES as your primary datastore. If you do so, ensure you have a restore (ie, frequent snapshots) and replay mechanism (Kafka works well) in place.
Flakiness in a datacenter just resulted in loss of a couple of daily logstash indexes on 1.3.0 release. It’s internal logging monitoring, so not a big deal, but if this was valuable client data or user facing it would have been a mess.