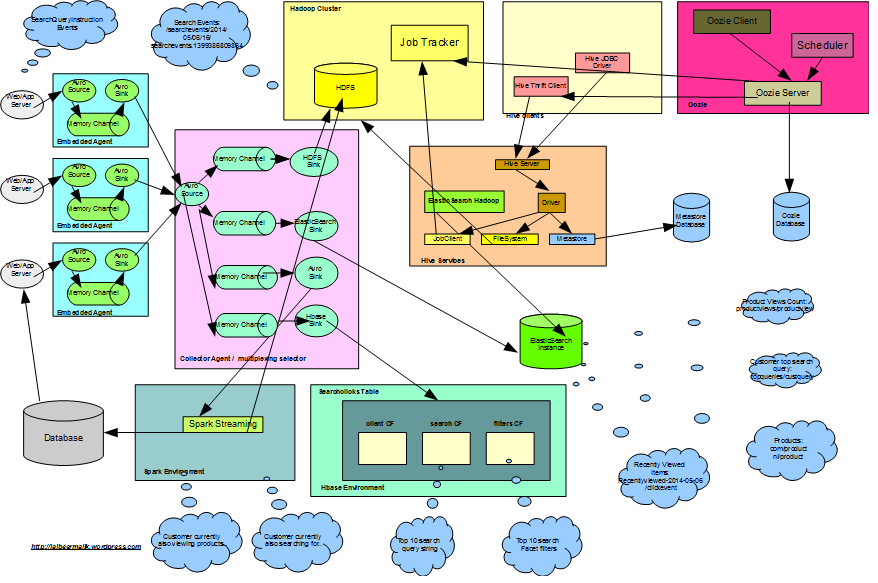
In this post we will explore HBase to store customer search click events data and utilizing same to derive customer behavior information based on search query string and facet filter clicks. We will cover to use MiniHBaseCluster, HBase Schema design, integration with Flume using HBaseSink to store JSON data.
In continuation to the previous posts on,
- Customer product search clicks analytics using big data,
- Flume: Gathering customer product search clicks data using Apache Flume,
- Hive: Query customer top search query and product views count using Apache Hive,
- ElasticSearch-Hadoop: Indexing product views count and customer top search query from Hadoop to ElasticSearch,
- Oozie: Scheduling Coordinator/Bundle jobs for Hive partitioning and ElasticSearch indexing,
- Spark: Real time analytics for big data for top search queries and top product views
We have explored to store search click events data in Hadoop and to query same using different technologies. Here we will use HBase to achieve the same:
- HBase mini cluster setup
- HBase template using Spring Data
- HBase Schema Design
- Flume Integration using HBaseSink
- HBaseJsonSerializer to serialize json data
- Query Top 10 search query string in last an hour
- Query Top 10 search facet filter in last an hour
- Get recent search query string for a customer in last 30 days
HBase
HBase “is the Hadoop database, a distributed, scalable, big data store.”
HBaseMiniCluster/MiniZookeperCluster
To setup and start mini cluster, Check HBaseServiceImpl.java
...
miniZooKeeperCluster = new MiniZooKeeperCluster();
miniZooKeeperCluster.setDefaultClientPort(10235);
miniZooKeeperCluster.startup(new File("taget/zookeper/dfscluster_" + UUID.randomUUID().toString()).getAbsoluteFile());
...
Configuration config = HBaseConfiguration.create();
config.set("hbase.tmp.dir", new File("target/hbasetom").getAbsolutePath());
config.set("hbase.master.port", "44335");
config.set("hbase.master.info.port", "44345");
config.set("hbase.regionserver.port", "44435");
config.set("hbase.regionserver.info.port", "44445");
config.set("hbase.master.distributed.log.replay", "false");
config.set("hbase.cluster.distributed", "false");
config.set("hbase.master.distributed.log.splitting", "false");
config.set("hbase.zookeeper.property.clientPort", "10235");
config.set("zookeeper.znode.parent", "/hbase");
miniHBaseCluster = new MiniHBaseCluster(config, 1);
miniHBaseCluster.startMaster();
...MiniZookeeprCluster is started on client port 10235, all client connections will be on this port. Make sure to configure the hbase server port not colliding with your other local hbase server. Here we are only starting one hbase region server in the test case.
HBase Template using Spring Data
We will be using Spring hbase template to connect to HBase cluster:
<hdp:hbase-configuration id="hbaseConfiguration" configuration-ref="hadoopConfiguration" stop-proxy="false" delete-connection="false" zk-quorum="localhost" zk-port="10235"> </hdp:hbase-configuration> <bean id="hbaseTemplate" class="org.springframework.data.hadoop.hbase.HBaseTemplate" p:configuration-ref="hbaseConfiguration" />
HBase Table Schema Design
We have search click event JSON data in the following format,
{"eventid":"24-1399386809805-629e9b5f-ff4a-4168-8664-6c8df8214aa7","hostedmachinename":"192.168.182.1330","pageurl":"http://blahblah:/5","customerid":24,"sessionid":"648a011d-570e-48ef-bccc-84129c9fa400","querystring":null,"sortorder":"desc","pagenumber":3,"totalhits":28,"hitsshown":7,"createdtimestampinmillis":1399386809805,"clickeddocid":"41","favourite":null,"eventidsuffix":"629e9b5f-ff4a-4168-8664-6c8df8214aa7","filters":[{"code":"searchfacettype_color_level_2","value":"Blue"},{"code":"searchfacettype_age_level_2","value":"12-18 years"}]}
One way to handle the data is to directly store it under one column family and json column. It won’t be easy and flexible to scan the json data that way. Another option can be to store it under one column family but to have different columns. But storing filters data in single column will be hard to scan. The hybrid approach below is to divide it under multiple column family and dynamically generate columns for filters data.
The converted schema is:
{
"client:eventid" => "24-1399386809805-629e9b5f-ff4a-4168-8664-6c8df8214aa7",
"client:eventidsuffix" => "629e9b5f-ff4a-4168-8664-6c8df8214aa7",
"client:hostedmachinename" => "192.168.182.1330",
"client:pageurl" => "http://blahblah:/5",
"client:createdtimestampinmillis" => 1399386809805,
"client:cutomerid" => 24,
"client:sessionid" => "648a011d-570e-48ef-bccc-84129c9fa400",
"search:querystring" => null,
"search:sortorder" => desc,
"search:pagenumber" => 3,
"search:totalhits" => 28,
"search:hitsshown" => 7,
"search:clickeddocid" => "41",
"search:favourite" => null,
"filters:searchfacettype_color_level_2" => "Blue",
"filters:searchfacettype_age_level_2" => "12-18 years"
}The following three column family are created:
- client: To store client and customer data specific information for the event.
- search: search information related to query string and pagination information is stored here.
- filters: To support additional facets in future etc. and more flexible scanning of data, the column names are dynamically created based on facet name/code and the column value is stored as facet filter value.
To create the hbase table,
...
TableName name = TableName.valueOf("searchclicks");
HTableDescriptor desc = new HTableDescriptor(name);
desc.addFamily(new HColumnDescriptor(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES));
desc.addFamily(new HColumnDescriptor(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES));
desc.addFamily(new HColumnDescriptor(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES));
try {
HBaseAdmin hBaseAdmin = new HBaseAdmin(miniHBaseCluster.getConf());
hBaseAdmin.createTable(desc);
hBaseAdmin.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
...Relevant column family has been added on table creation to support new data structure. In general, it is recommended to keep the number of column family as minimum as possible, keep in mind how you structure your data based on the usage. Based on above examples, we have kept the scan scenario like:
- scan client family in case you want to retrieve customer or client information based on total traffic information on the website.
- scan search information to see what free text search the end customers are looking for which are not met by the navigational search. See on which page the relevant product was clicked, do you need boosting to apply to push the product high.
- scan filters family to see how the navigational search is working for you. Is it giving end customers the product they are looking for. See which facet filters are clicked more and do you need to push to up a bit in the ordering to be available easily to the customer.
- scan between family should be avoided and use row key design to achieve specific customer info.
Row key design info
In our case the row key design is based on customerId-timestamp -randomuuid. As the row key is same for all the column family, we can use Prefix Filter to filter on row only relevant to a specific customer.
final String eventId = customerId + "-" + searchQueryInstruction.getCreatedTimeStampInMillis() + "-" + searchQueryInstruction.getEventIdSuffix(); ... byte[] rowKey = searchQueryInstruction.getEventId().getBytes(CHARSET_DEFAULT); ... # 24-1399386809805-629e9b5f-ff4a-4168-8664-6c8df8214aa7
Each column family here will have same row key, and you can use prefix filter to scan rows only for a particular customer.
Flume Integration
HBaseSink is used to store search events data directly to HBase. Check details, FlumeHBaseSinkServiceImpl.java
...
channel = new MemoryChannel();
Map<String, String> channelParamters = new HashMap<>();
channelParamters.put("capacity", "100000");
channelParamters.put("transactionCapacity", "1000");
Context channelContext = new Context(channelParamters);
Configurables.configure(channel, channelContext);
channel.setName("HBaseSinkChannel-" + UUID.randomUUID());
sink = new HBaseSink();
sink.setName("HBaseSink-" + UUID.randomUUID());
Map<String, String> paramters = new HashMap<>();
paramters.put(HBaseSinkConfigurationConstants.CONFIG_TABLE, "searchclicks");
paramters.put(HBaseSinkConfigurationConstants.CONFIG_COLUMN_FAMILY, new String(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES));
paramters.put(HBaseSinkConfigurationConstants.CONFIG_BATCHSIZE, "1000");
paramters.put(HBaseSinkConfigurationConstants.CONFIG_SERIALIZER, HBaseJsonEventSerializer.class.getName());
Context sinkContext = new Context(paramters);
sink.configure(sinkContext);
sink.setChannel(channel);
sink.start();
channel.start();
...Client column family is used only for validation by HBaseSink.
HBaseJsonEventSerializer
Custom serializer is created to store the JSON data:
public class HBaseJsonEventSerializer implements HBaseEventSerializer {
public static final byte[] COLUMFAMILY_CLIENT_BYTES = "client".getBytes();
public static final byte[] COLUMFAMILY_SEARCH_BYTES = "search".getBytes();
public static final byte[] COLUMFAMILY_FILTERS_BYTES = "filters".getBytes();
...
byte[] rowKey = searchQueryInstruction.getEventId().getBytes(CHARSET_DEFAULT);
Put put = new Put(rowKey);
// Client Infor
put.add(COLUMFAMILY_CLIENT_BYTES, "eventid".getBytes(), searchQueryInstruction.getEventId().getBytes());
...
if (searchQueryInstruction.getFacetFilters() != null) {
for (SearchQueryInstruction.FacetFilter filter : searchQueryInstruction.getFacetFilters()) {
put.add(COLUMFAMILY_FILTERS_BYTES, filter.getCode().getBytes(),filter.getValue().getBytes());
}
}
...Check further details, HBaseJsonEventSerializer.java
The events body is converted to Java bean from Json and further the data is processed to be serialized in relevant column family.
Query Raw Cell data
To query the raw cell data:
...
Scan scan = new Scan();
scan.addFamily(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES);
scan.addFamily(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES);
scan.addFamily(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES);
List<String> rows = hbaseTemplate.find("searchclicks", scan,
new RowMapper<String>() {
@Override
public String mapRow(Result result, int rowNum) throws Exception {
return Arrays.toString(result.rawCells());
}
});
for (String row : rows) {
LOG.debug("searchclicks table content, Table returned row: {}", row);
}Check HBaseServiceImpl.java for details.
The data is stored in hbase in the following format:
searchclicks table content, Table returned row: [84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:createdtimestampinmillis/1404832918166/Put/vlen=13/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:customerid/1404832918166/Put/vlen=2/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:eventid/1404832918166/Put/vlen=53/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:hostedmachinename/1404832918166/Put/vlen=16/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:pageurl/1404832918166/Put/vlen=19/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:sessionid/1404832918166/Put/vlen=36/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/filters:searchfacettype_product_type_level_2/1404832918166/Put/vlen=7/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:hitsshown/1404832918166/Put/vlen=2/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:pagenumber/1404832918166/Put/vlen=1/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:querystring/1404832918166/Put/vlen=13/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:sortorder/1404832918166/Put/vlen=3/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:totalhits/1404832918166/Put/vlen=2/mvcc=0]
Query Top 10 search query string in last an hour
To query only search string, we only need search column family. To scan within time range, either we can use the client column family createdtimestampinmillis column but it will be expansive scan.
...
Scan scan = new Scan();
scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES, Bytes.toBytes("createdtimestampinmillis"));
scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES, Bytes.toBytes("querystring"));
List<String> rows = hbaseTemplate.find("searchclicks", scan,
new RowMapper<String>() {
@Override
public String mapRow(Result result, int rowNum) throws Exception {
String createdtimestampinmillis = new String(result.getValue(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES, Bytes.toBytes("createdtimestampinmillis")));
byte[] value = result.getValue(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES, Bytes.toBytes("querystring"));
String querystring = null;
if (value != null) {
querystring = new String(value);
}
if (new DateTime(Long.valueOf(createdtimestampinmillis)).plusHours(1).compareTo(new DateTime()) == 1 && querystring != null) {
return querystring;
}
return null;
}
});
...
//sort the keys, based on counts collection of the query strings.
List<String> sortedKeys = Ordering.natural().onResultOf(Functions.forMap(counts)).immutableSortedCopy(counts.keySet());
...Query Top 10 search facet filter in last an hour
Based on dynamic column creation, you can scan the data to return the top clicked facet filters.
The dynamic columns will be based on your facet codes which can be any of:
#searchfacettype_age_level_1
#searchfacettype_color_level_2
#searchfacettype_brand_level_2
#searchfacettype_age_level_2
for (String facetField : SearchFacetName.categoryFacetFields) {
scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES, Bytes.toBytes(facetField));
}To retrieve to:
...
hbaseTemplate.find("searchclicks", scan, new RowMapper<String>() {
@Override
public String mapRow(Result result, int rowNum) throws Exception {
for (String facetField : SearchFacetName.categoryFacetFields) {
byte[] value = result.getValue(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES, Bytes.toBytes(facetField));
if (value != null) {
String facetValue = new String(value);
List<String> list = columnData.get(facetField);
if (list == null) {
list = new ArrayList<>();
list.add(facetValue);
columnData.put(facetField, list);
} else {
list.add(facetValue);
}
}
}
return null;
}
});
...You will get the full list of all facets, you can process the data further to count top facets and ordering same. For full details check, HBaseServiceImpl.findTopTenSearchFiltersForLastAnHour
Get recent search query string for a customer
If we need to check what is customer is currently looking for, we can create a scan between two column family between “client” and “search”. Or another way is to design the row key in a way to give you relevant information. In our case the row key design is based on CustomerId_timestamp _randomuuid. As the row key is same for all the column family, we can use Prefix Filter to filter on row only relevant to a specific customer.
final String eventId = customerId + "-" + searchQueryInstruction.getCreatedTimeStampInMillis() + "-" + searchQueryInstruction.getEventIdSuffix(); ... byte[] rowKey = searchQueryInstruction.getEventId().getBytes(CHARSET_DEFAULT); ... # 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923
To scan the data for a particular customer,
...
Scan scan = new Scan();
scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES, Bytes.toBytes("customerid"));
Filter filter = new PrefixFilter(Bytes.toBytes(customerId + "-"));
scan.setFilter(filter);
...For details check HBaseServiceImpl.getAllSearchQueryStringsByCustomerInLastOneMonth
Hope this helps you to get hands on HBase schema design and handling data.
| Reference: | HBase: Generating search click events statistics for customer behavior from our JCG partner Jaibeer Malik at the Jai’s Weblog blog. |
