
Synchronized sections are kind of like visiting your parents-in-law. You want to be there as little as possible. When it comes to locking the rules are the same – you want to spend the shortest amount of time acquiring the lock and within the critical section, to prevent bottlenecks from forming.
The core language idiom for locking has always been the synchronized keyword, for methods and discrete blocks. This keyword is really hardwired into the HotSpot JVM. Each object we allocate in our code, be it a String, Array or a full-blown JSON document, has locking capabilities built right into its header at the native GC level. The same goes for the JIT compiler that compiles and re-compiles bytecode depending on the specific state and contention levels for a specific lock.
The problem with synchronized blocks is that they’re all or nothing – you can’t have more than one thread inside a critical section. This is especially a bummer in consumer / producer scenarios, where some threads are trying to edit some data exclusively, while others are only trying to read it and are fine with sharing access.
ReadWriteLocks were meant to be the perfect solution for this. You can specify which threads block everyone else (writers), and which ones play well with others for consuming content (readers). A happy ending? Afraid not.
Unlike synchronized blocks, RW locks are not built-in to the JVM and have the same capabilities as mere mortal code. Still, to implement a locking idiom you need to instruct the CPU to perform specific operations atomically, or in specific order, to avoid race conditions. This is traditionally done through the magical portal-hole into the JVM – the unsafe class. RW Locks use Compare-And-Swap (CAS) operations to set values directly into memory as part of their thread queuing algorithm.
Even so, RWLocks are just not fast enough, and at times prove to be really darn slow, to the point of not being worth bothering with. However help is on the way, with the good folks at the JDK not giving up, and are now back with the new StampedLock. This RW lock employs a new set of algorithms and memory fencing features added to the Java 8 JDK to help make this lock faster and more robust.
Does it deliver on its promise? Let’s see.
Using the lock. On the face of it StampedLocks are more complex to use. They employ a concept of stamps that are long values that serve as tickets used by any lock / unlock operation. This means that to unlock a R/W operation you need to pass it its correlating lock stamp. Pass the wrong stamp, and you’re risking an exception, or worse – unexpected behavior.
Another key piece to be really mindful of, is that unlike RWLocks, StampedLocks are not reentrant. So while they may be faster, they have the downside that threads can now deadlock against themselves. In practice, this means that more than ever, you should make sure that locks and stamps do not escape their enclosing code blocks.
long stamp = lock.writeLock(); //blocking lock, returns a stamp
try {
write(stamp); // this is a bad move, you’re letting the stamp escape
}
finally {
lock.unlock(stamp);// release the lock in the same block - way better
}Another pet peeve I have with this design is that stamps are served as long values that don’t really mean anything to you. I would have preferred lock operations to return an object which describes the stamp – its type (R/W), lock time, owner thread etc.. This would have made debugging and logging easier. This is probably intentional though, and is meant to prevent developers from passing stamps between different parts of the code, and also save on the cost of allocating an object.
Optimistic locking. The most important piece in terms of new capabilities for this lock is the new Optimistic locking mode. Research and practical experience show that read operations are for the most part not contended with write operations. Asa result, acquiring a full-blown read lock may prove to be overkill. A better approach may be to go ahead and perform the read, and at the end of it see whether the value has been actually modified in the meanwhile. If that was the case you can retry the read, or upgrade to a heavier lock.
long stamp = lock.tryOptimisticRead(); // non blocking
read();
if(!lock.validate(stamp)){ // if a write occurred, try again with a read lock
long stamp = lock.readLock();
try {
read();
}
finally {
lock.unlock(stamp);
}
}One of the biggest hassles in picking a lock, is that its actual behavior in production will differ depending on application state. This means that the choice of a lock idiom cannot be done in a vacuum, and must take into consideration the real-world conditions under which the code will execute.
The number of concurrent reader vs. writer threads will change which lock you should use – a synchronized section or a RW lock. This gets harder as these numbers can change during the lifecycle of the JVM, depending on application state and thread contention.
To illustrate this, I stress-tested four modes of locking – synchronized, RW Lock, Stamped RW lock and RW optimistic locking under different contention levels and R/W thread combinations. Reader threads will consume the value of a counter, while writer threads will increment it from 0 to 1M.
5 readers vs. 5 writers: Stacking up five concurrent reader and five writer threads, we see that the stamped lock shines, performing much better than synchronized by a factor of 3X. RW lock also performed well. The strange thing here is that optimistic locking, which on the surface of things should be the fastest, is actually the slowest here.
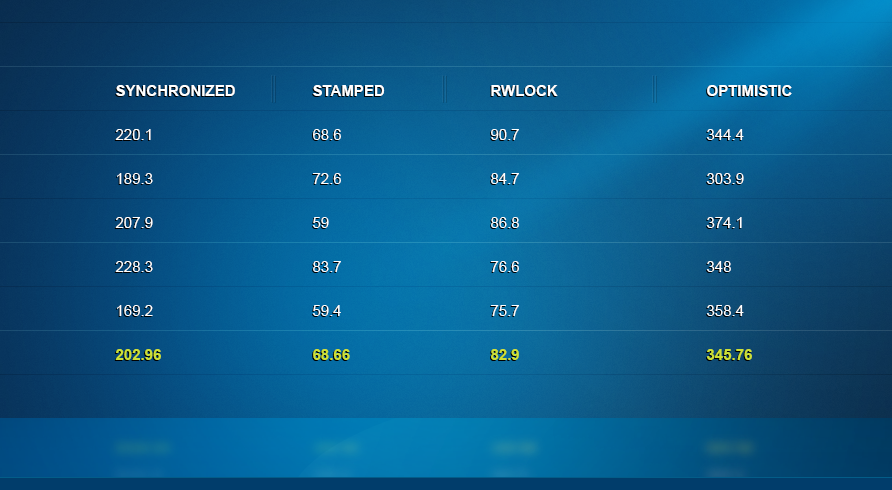
10 readers vs. 10 writers: Next, I increased the levels of contention to ten writer and ten reader threads. Here things start to materially change. RW lock is now an order of magnitude slower than stamped and synchronized locks, which perform at the same level. Notice that optimistic locking surprisingly is still slower stamped RW locking.
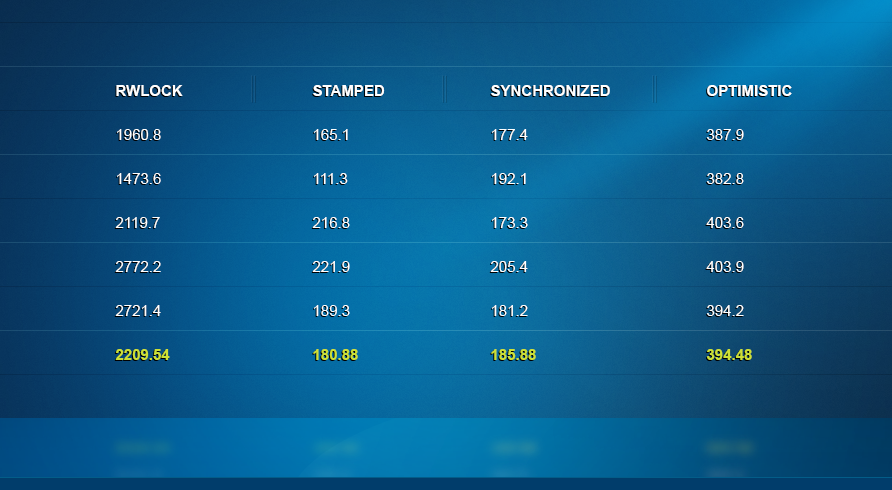
16 readers vs. 4 writers: Next, I maintained a high level of contention while tilting the balance in favor of reader threads: sixteen readers vs. four writers. The RW lock continues to demonstrate the reason why it’s essentially being replaced – it’s a hundred times slower. Stamped and Optimistic perform well, with synchronized not that far behind.
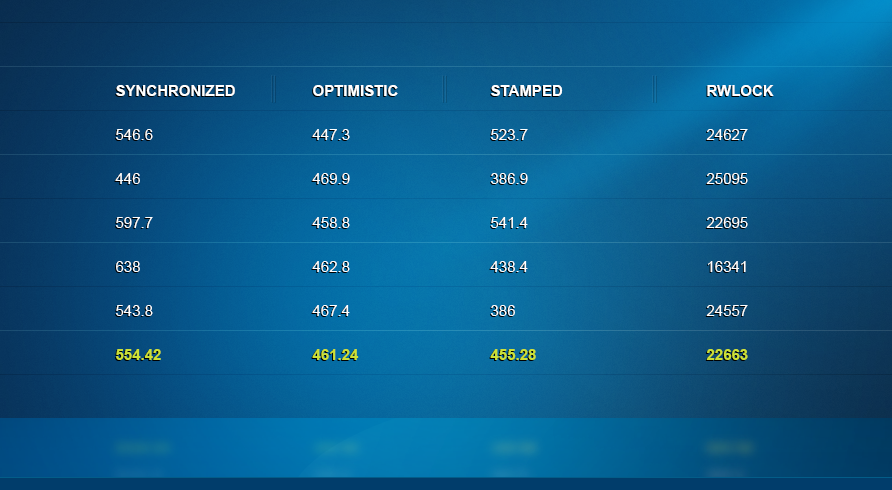
19 readers vs. 1 writer: Last, I looked at how a single writer thread does against nineteen readers. Notice that the results are much slower, as the single thread takes longer to complete the work. Here we get some pretty interesting results. Not surprisingly, the RW lock takes infinity to complete. Stamped locking isn’t doing much better though… Optimistic locking is the clear winner here, beating RW lock by a factor of 100. Even so keep in mind that this locking mode may fail you, as a writer may occur during that time. Synchronized, our old faithful, continues to deliver solid results.
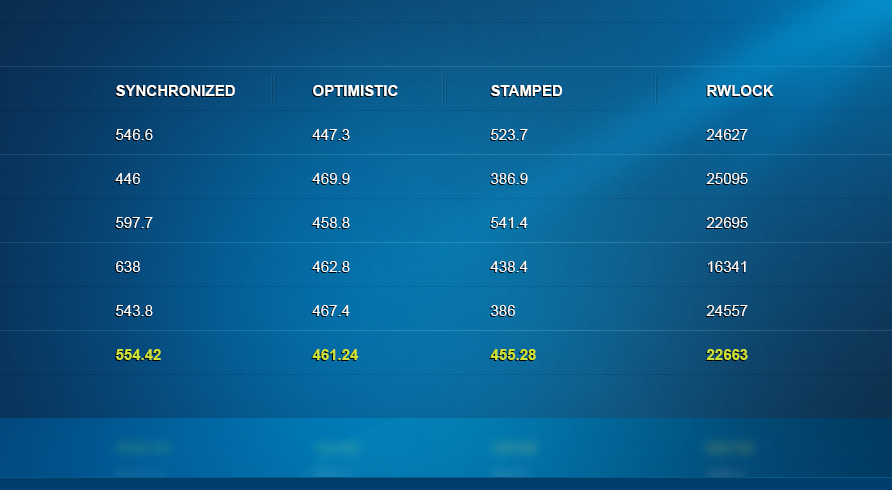
The full results can be found here… Hardware: MBP quad Core i7.
The benchmark code can be found here.
Conclusions
It seems that on average the best performance overall is still being delivered by the intrinsic synchronized lock. Even so, the point here is not to say that it will perform the best in all situations. It’s mainly to show that your choice of locking idiom should be made based on testing both the expected level of contention, and the division between reader and writer threads before you take your code to production. Otherwise you run the risk of some serious production debugging pain.
Additional reading about StampedLocks here.
Questions, comments, notes on the benchmark? Let me know!
| Reference: | Java 8 StampedLocks vs. ReadWriteLocks and Synchronized from our JCG partner Tal Weiss at the Takipi blog. |

{kind=link}
This is a disappointingly skewed benchmark. The point of a ReadWriteLock is to increase throughput for reads when writes are relatively less common. From looking at the benchmark code, though, the top-line number is wholly dependent on how long the writer threads take to push a counter to a target value. In other words, it completely ignores that the ReadWriteLock could be getting dramatically higher read throughput compared to the other approaches, and only reflects that an increasingly busy set of readers can increasingly delay a shrinking pool of writers, which should be obvious. What would be useful is instead… Read more »
Agreed with Jason. The use case for a ReadWriteLock (with re-entrant behavior) is different than what this new lock is intended for. You completely miss the throughput of the reads with your stats.
Hi Jason, Thanks for the great comment. The point of the benchmark was to try and get as much contention as possible between the R/W threads , which is I picked a relatively small operation to be carried out. I was also interested in seeing how those levels of contentions change in relation to the number of readers and writers. You could put a sleep or IO call within the write critical section to alleviate the lock contention, and make the write operation longer (making life for the lock a bit easier). There’s really no one benchmark that can cover… Read more »