At Data Geekery, we love Java. And as we’re really into jOOQ’s fluent API and query DSL, we’re absolutely thrilled about what Java 8 will bring to our ecosystem.
Java 8 Friday
Every Friday, we’re showing you a couple of nice new tutorial-style Java 8 features, which take advantage of lambda expressions, extension methods, and other great stuff. You’ll find the source code on GitHub.
10 Subtle Mistakes When Using the Streams API
We’ve done all the SQL mistakes lists:
- 10 Common Mistakes Java Developers Make when Writing SQL
- 10 More Common Mistakes Java Developers Make when Writing SQL
- Yet Another 10 Common Mistakes Java Developers Make When Writing SQL (You Won’t BELIEVE the Last One)
But we haven’t done a top 10 mistakes list with Java 8 yet! For today’s occasion (it’s Friday the 13th), we’ll catch up with what will go wrong in YOUR application when you’re working with Java 8 (it won’t happen to us, as we’re stuck with Java 6 for another while).
1. Accidentally reusing streams
Wanna bet, this will happen to everyone at least once. Like the existing “streams” (e.g. InputStream), you can consume streams only once. The following code won’t work:
IntStream stream = IntStream.of(1, 2); stream.forEach(System.out::println); // That was fun! Let's do it again! stream.forEach(System.out::println);
You’ll get a:
java.lang.IllegalStateException: stream has already been operated upon or closed
So be careful when consuming your stream. It can be done only once.
2. Accidentally creating “infinite” streams
You can create infinite streams quite easily without noticing. Take the following example:
// Will run indefinitely
IntStream.iterate(0, i -> i + 1)
.forEach(System.out::println);The whole point of streams is the fact that they can be infinite, if you design them to be. The only problem is, that you might not have wanted that. So, be sure to always put proper limits:
// That's better
IntStream.iterate(0, i -> i + 1)
.limit(10)
.forEach(System.out::println);3. Accidentally creating “subtle” infinite streams
We can’t say this enough. You WILL eventually create an infinite stream, accidentally. Take the following stream, for instance:
IntStream.iterate(0, i -> ( i + 1 ) % 2)
.distinct()
.limit(10)
.forEach(System.out::println);So…
- we generate alternating 0′s and 1′s
- then we keep only distinct values, i.e. a single 0 and a single 1
- then we limit the stream to a size of 10
- then we consume it
Well… the distinct() operation doesn’t know that the function supplied to the iterate() method will produce only two distinct values. It might expect more than that. So it’ll forever consume new values from the stream, and the limit(10) will never be reached. Tough luck, your application stalls.
4. Accidentally creating “subtle” parallel infinite streams
We really need to insist that you might accidentally try to consume an infinite stream. Let’s assume you believe that the distinct() operation should be performed in parallel. You might be writing this:
IntStream.iterate(0, i -> ( i + 1 ) % 2)
.parallel()
.distinct()
.limit(10)
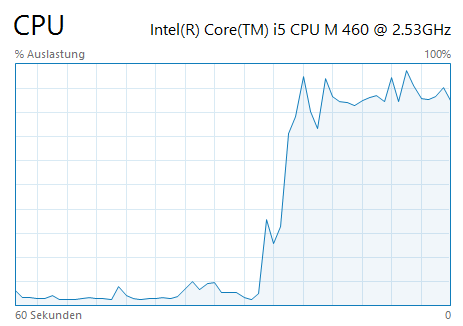
.forEach(System.out::println);Now, we’ve already seen that this will turn forever. But previously, at least, you only consumed one CPU on your machine. Now, you’ll probably consume four of them, potentially occupying pretty much all of your system with an accidental infinite stream consumption. That’s pretty bad. You can probably hard-reboot your server / development machine after that. Have a last look at what my laptop looked like prior to exploding:
5. Mixing up the order of operations
So, why did we insist on your definitely accidentally creating infinite streams? It’s simple. Because you may just accidentally do it. The above stream can be perfectly consumed if you switch the order of limit() and distinct():
IntStream.iterate(0, i -> ( i + 1 ) % 2)
.limit(10)
.distinct()
.forEach(System.out::println);This now yields:
0 1
Why? Because we first limit the infinite stream to 10 values (0 1 0 1 0 1 0 1 0 1), before we reduce the limited stream to the distinct values contained in it (0 1).
Of course, this may no longer be semantically correct, because you really wanted the first 10 distinct values from a set of data (you just happened to have “forgotten” that the data is infinite). No one really wants 10 random values, and only then reduce them to be distinct.
If you’re coming from a SQL background, you might not expect such differences. Take SQL Server 2012, for instance. The following two SQL statements are the same:
-- Using TOP SELECT DISTINCT TOP 10 * FROM i ORDER BY .. -- Using FETCH SELECT * FROM i ORDER BY .. OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY
So, as a SQL person, you might not be as aware of the importance of the order of streams operations.

6. Mixing up the order of operations (again)
Speaking of SQL, if you’re a MySQL or PostgreSQL person, you might be used to the LIMIT .. OFFSET clause. SQL is full of subtle quirks, and this is one of them. The OFFSET clause is applied FIRST, as suggested in SQL Server 2012′s (i.e. the SQL:2008 standard’s) syntax.
If you translate MySQL / PostgreSQL’s dialect directly to streams, you’ll probably get it wrong:
IntStream.iterate(0, i -> i + 1)
.limit(10) // LIMIT
.skip(5) // OFFSET
.forEach(System.out::println);The above yields
5 6 7 8 9
Yes. It doesn’t continue after 9, because the limit() is now applied first, producing (0 1 2 3 4 5 6 7 8 9). skip() is applied after, reducing the stream to (5 6 7 8 9). Not what you may have intended.
BEWARE of the LIMIT .. OFFSET vs. "OFFSET .. LIMIT" trap!
7. Walking the file system with filters
We’ve blogged about this before. What appears to be a good idea is to walk the file system using filters:
Files.walk(Paths.get("."))
.filter(p -> !p.toFile().getName().startsWith("."))
.forEach(System.out::println);The above stream appears to be walking only through non-hidden directories, i.e. directories that do not start with a dot. Unfortunately, you’ve again made mistake #5 and #6. walk() has already produced the whole stream of subdirectories of the current directory. Lazily, though, but logically containing all sub-paths. Now, the filter will correctly filter out paths whose names start with a dot “.”. E.g. .git or .idea will not be part of the resulting stream. But these paths will be: .\.git\refs, or .\.idea\libraries. Not what you intended.
Now, don’t fix this by writing the following:
Files.walk(Paths.get("."))
.filter(p -> !p.toString().contains(File.separator + "."))
.forEach(System.out::println);While that will produce the correct output, it will still do so by traversing the complete directory subtree, recursing into all subdirectories of “hidden” directories.
I guess you’ll have to resort to good old JDK 1.0 File.list() again. The good news is, FilenameFilter and FileFilter are both functional interfaces.
8. Modifying the backing collection of a stream
While you’re iterating a List, you must not modify that same list in the iteration body. That was true before Java 8, but it might become more tricky with Java 8 streams. Consider the following list from 0..9:
// Of course, we create this list using streams:
List<Integer> list =
IntStream.range(0, 10)
.boxed()
.collect(toCollection(ArrayList::new));Now, let’s assume that we want to remove each element while consuming it:
list.stream()
// remove(Object), not remove(int)!
.peek(list::remove)
.forEach(System.out::println);Interestingly enough, this will work for some of the elements! The output you might get is this one:
0 2 4 6 8 null null null null null java.util.ConcurrentModificationException
If we introspect the list after catching that exception, there’s a funny finding. We’ll get:
[1, 3, 5, 7, 9]
Heh, it “worked” for all the odd numbers. Is this a bug? No, it looks like a feature. If you’re delving into the JDK code, you’ll find this comment in ArrayList.ArraListSpliterator:
/* * If ArrayLists were immutable, or structurally immutable (no * adds, removes, etc), we could implement their spliterators * with Arrays.spliterator. Instead we detect as much * interference during traversal as practical without * sacrificing much performance. We rely primarily on * modCounts. These are not guaranteed to detect concurrency * violations, and are sometimes overly conservative about * within-thread interference, but detect enough problems to * be worthwhile in practice. To carry this out, we (1) lazily * initialize fence and expectedModCount until the latest * point that we need to commit to the state we are checking * against; thus improving precision. (This doesn't apply to * SubLists, that create spliterators with current non-lazy * values). (2) We perform only a single * ConcurrentModificationException check at the end of forEach * (the most performance-sensitive method). When using forEach * (as opposed to iterators), we can normally only detect * interference after actions, not before. Further * CME-triggering checks apply to all other possible * violations of assumptions for example null or too-small * elementData array given its size(), that could only have * occurred due to interference. This allows the inner loop * of forEach to run without any further checks, and * simplifies lambda-resolution. While this does entail a * number of checks, note that in the common case of * list.stream().forEach(a), no checks or other computation * occur anywhere other than inside forEach itself. The other * less-often-used methods cannot take advantage of most of * these streamlinings. */
Now, check out what happens when we tell the stream to produce sorted() results:
list.stream()
.sorted()
.peek(list::remove)
.forEach(System.out::println);This will now produce the following, “expected” output
0 1 2 3 4 5 6 7 8 9
And the list after stream consumption? It is empty:
[]
So, all elements are consumed, and removed correctly. The sorted() operation is a “stateful intermediate operation”, which means that subsequent operations no longer operate on the backing collection, but on an internal state. It is now “safe” to remove elements from the list!
Well… can we really? Let’s proceed with parallel(), sorted() removal:
list.stream()
.sorted()
.parallel()
.peek(list::remove)
.forEach(System.out::println);This now yields:
7 6 2 5 8 4 1 0 9 3
And the list contains
[8]
Eek. We didn’t remove all elements!? Free beers (and jOOQ stickers) go to anyone who solves this streams puzzler!
This all appears quite random and subtle, we can only suggest that you never actually do modify a backing collection while consuming a stream. It just doesn’t work.
9. Forgetting to actually consume the stream
What do you think the following stream does?
IntStream.range(1, 5)
.peek(System.out::println)
.peek(i -> {
if (i == 5)
throw new RuntimeException("bang");
});When you read this, you might think that it will print (1 2 3 4 5) and then throw an exception. But that’s not correct. It won’t do anything. The stream just sits there, never having been consumed.
As with any fluent API or DSL, you might actually forget to call the “terminal” operation. This might be particularly true when you use peek(), as peek() is an aweful lot similar to forEach().
This can happen with jOOQ just the same, when you forget to call execute() or fetch():
DSL.using(configuration) .update(TABLE) .set(TABLE.COL1, 1) .set(TABLE.COL2, "abc") .where(TABLE.ID.eq(3));
Oops. No execute()

Yes, the “best” way – with 1-2 caveats!
10. Parallel stream deadlock
This is now a real goodie for the end!
All concurrent systems can run into deadlocks, if you don’t properly synchronise things. While finding a real-world example isn’t obvious, finding a forced example is. The following parallel() stream is guaranteed to run into a deadlock:
Object[] locks = { new Object(), new Object() };
IntStream
.range(1, 5)
.parallel()
.peek(Unchecked.intConsumer(i -> {
synchronized (locks[i % locks.length]) {
Thread.sleep(100);
synchronized (locks[(i + 1) % locks.length]) {
Thread.sleep(50);
}
}
}))
.forEach(System.out::println);Note the use of Unchecked.intConsumer(), which transforms the functional IntConsumer interface into a org.jooq.lambda.fi.util.function.CheckedIntConsumer, which is allowed to throw checked exceptions.
Well. Tough luck for your machine. Those threads will be blocked forever!
The good news is, it has never been easier to produce a schoolbook example of a deadlock in Java!
For more details, see also Brian Goetz’s answer to this question on Stack Overflow.
Conclusion
With streams and functional thinking, we’ll run into a massive amount of new, subtle bugs. Few of these bugs can be prevented, except through practice and staying focused. You have to think about how to order your operations. You have to think about whether your streams may be infinite.
Streams (and lambdas) are a very powerful tool. But a tool which we need to get a hang of, first.
| Reference: | Java 8 Friday: 10 Subtle Mistakes When Using the Streams API from our JCG partner Lukas Eder at the JAVA, SQL, AND JOOQ blog. |

{kind=link}