Apache Kafka has been used for some time now by organizations to consume not only all of the data within its infrastructure from an application perspective but also the server statistics of the running applications and infrastructure. Apache Kafka is great for this.
Coda Hale’s metrics’s has become a leading way to instrument your JVM applications capturing what the application is doing and reporting it to different servers like Graphite, Ganglia, Riemann and other systems. The main problem with this is the tight coupling between your application (and infrastructure) metrics with how you are charting, trending and alerting on them. Now lets insert Apache Kafka to-do the decoupling which it does best.

The systems sending data and the systems reading the data become decoupled through the Kafka brokers.
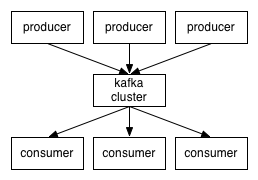
Now, once this decoupling happens it allows us to plug in new systems (producers) to send metrics and then have multiple different systems consuming them. This means that not only can you monitor and alert on the metrics but also (and at the same time) do real time analysis or analysis over the larger dataset consumed off somewhere else.
So, how does this all work? Well, we created a Metrics reporter https://github.com/stealthly/metrics-kafka that you can use within your own applications and any application supporting Coda Hale’s metrics but now reporting to a Kafka topic. We will be creating more producers (such as scrapping cpu, mem, disk, etc) and adding them to this project. To use this setup a Metrics reporter like you would normally but do so like this:
import ly.stealth.kafka.metrics.KafkaReporter val producer = KafkaReporter.builder(registry, kafkaConnection, topic).build() producer.report()
It was developed in Java so you don’t have to include the Scala dependencies if you are not using Scala. The source code for the reporter is available here: https://github.com/stealthly/metrics-kafka/tree/master/metrics/src/main/java/ly/stealth/kafka/metrics.
We also setup an example of how to read the produced metrics with Riemann. Riemann monitors distributed systems and provides low-latency, transient shared state for systems with many moving parts. There is a KafkaRiemman consumer that reads from Kafka and posts to Riemann https://github.com/stealthly/metrics-kafka/blob/master/riemann/src/main/scala/ly/stealth/kafka/riemann/RiemannMetricsConsumer.scala.
- Install Vagrant http://www.vagrantup.com/
- Install Virtual Box https://www.virtualbox.org/
git clone https://github.com/stealthly/metrics-kafka.git cd metrics-kafka vagrant up
Once the virtual machines are launched go to http://192.168.86.55:4567/. We setup a sample dashboard. Fom your command prompt run the test cases from the command prompt (after vms have launched).
./gradlew test
And the dashboard will populate automatically.
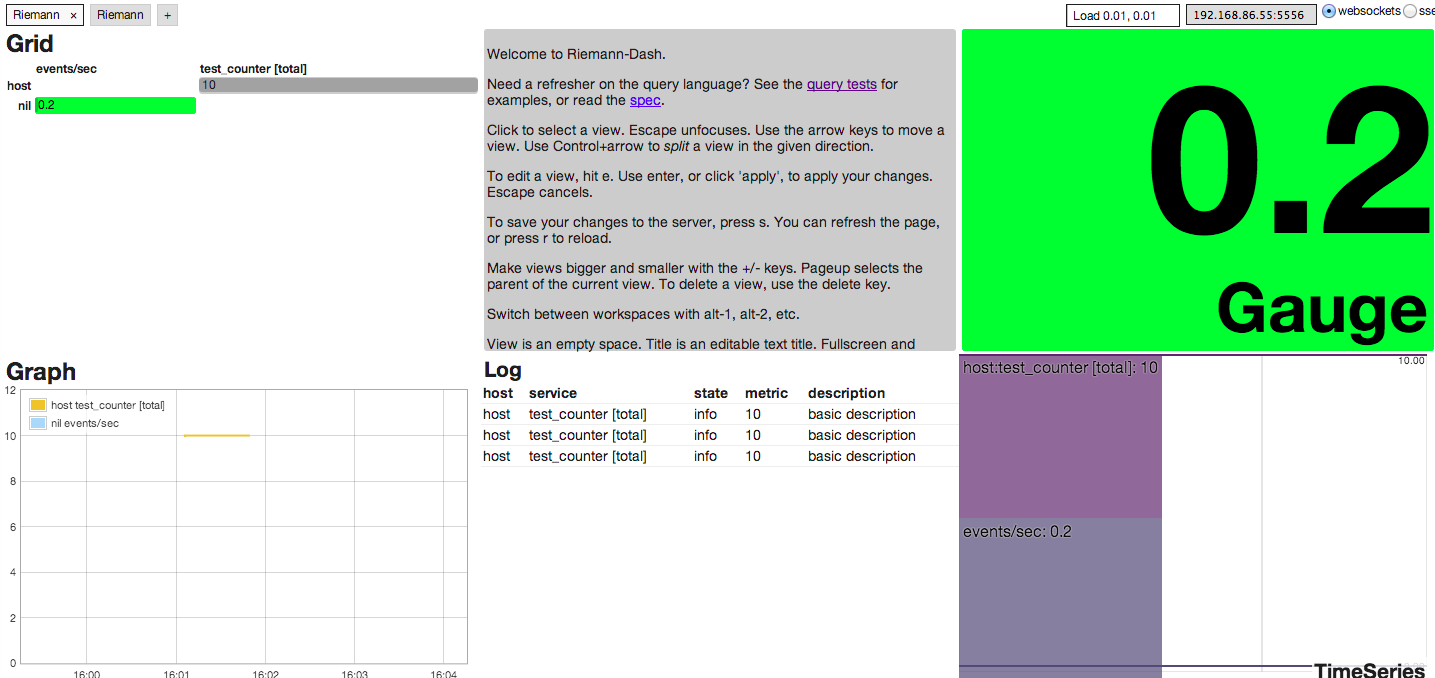
You can modify what is showing up in Riemann and learn how to use this from the test cases https://github.com/stealthly/metrics-kafka/blob/master/riemann/src/test/scala/ly/stealth/kafka/metrics/RiemannMetricsConsumerSpec.scala.
| Reference: | Reporting Metrics to Apache Kafka and Monitoring with Consumers from our JCG partner Joe Stein at the All Things Hadoop blog. |
