I’m a great multi-tasker. Even as I’m writing this post, I can still find room to feel awkward about a remark I made yesterday at a party that had everyone looking at me strange. Well, the good news is I’m not alone – Java 8 is also pretty good at multi-tasking. Let’s see how.
One of the key new features introduced in Java 8 is parallel array operations. This includes things like the ability to sort, filter and group items using Lambda expressions that automatically leverage multi-core architectures. The promise here is to get an immediate performance boost with minimal effort from our end as Java developers. Pretty cool.
So the question becomes – how fast is this thing, and when should I use it? Well, the quick answer is sadly – it depends. Wanna know on what? read on.
The new APIs
The new Java 8 parallel operation APIs are pretty slick. Let’s look at some of the ones we’ll be testing.
- To sort an array using multiple cores all you have to do is –
Arrays.parallelSort(numbers);
- To group a collection into different groups based on a specific criteria (e.g. prime and non-prime numbers) –
Map<Boolean, List<Integer>> groupByPrimary = numbers .parallelStream().collect(Collectors.groupingBy(s -> Utility.isPrime(s))); - To filter out values all you have do is –
Integer[] prims = numbers.parallelStream().filter(s -> Utility.isPrime(s)) .toArray();
Compare this with writing multi-threaded implementations yourself. Quite the productivity boost! The thing I personally liked about this new architecture is the new concept of Spliterators used for splitting a target collection into chunks which could then be processed in parallel and stitched back. Just like their older brothers iterators that are used to go over a collection of items, this is a flexible architecture that enables you to write custom behaviour for going over and splitting collections that you can directly plug into.
So how does it perform?
To test this out I examined how parallel operations work under two scenarios – low and high contention. The reason is that running a multi-core algorithm by itself will usually yield pretty nice results. The kicker comes in when it begins running in a real-world server environment. That’s where a large number of pooled threads are constantly vying for precious CPU cycles to process messages or user requests. And that’s where things start slowing down. For this I set up the following test. I randomized arrays of 100K integers with a value range between zero to a million. I then ran sort, group, and filter operations on them using both a traditional sequential approach and the new Java 8 parallelism APIs. The results were not surprising.
- Quicksort is now 4.7X times faster.
- Grouping is now 5X times faster.
- Filtering is now 5.5X times faster.
A happy ending? Unfortunately not.
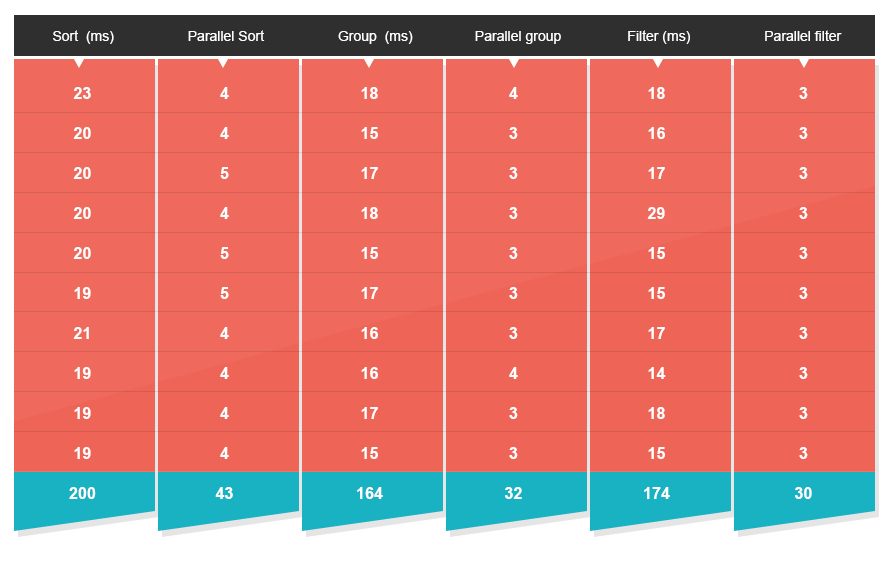
* The results are consistent with an additional test that ran 100 times * The test machine was a MBP i7 Quad Core.
So what happens under load?
So far things have been quite peachy, the reason being that there’s little contention between threads for CPU cycles. That’s an ideal situation, but unfortunately, one that doesn’t happen a lot in real life. To simulate a scenario which is more on par with what you’d normally see in a real-world environment I set up a second test. This test runs the same set of algorithms, but this time executes them on ten concurrent threads to simulate processing ten concurrent requests performed by a server when it’s under pressure (sing it Kermit!). Each of those requests will then be handled either sequentially using a traditional approach, or the new Java 8 APIs.
The results
- Sorting in now only 20% faster – a 23X decline.
- Filtering is now only 20% faster – a 25X decline.
- Grouping is now 15% slower.
Higher scale and contention levels will most likely bring these numbers further down. The reason is that adding threads in what already is a multi-threaded environment doesn’t help you. We’re only as good as how many CPUs we have – not threads.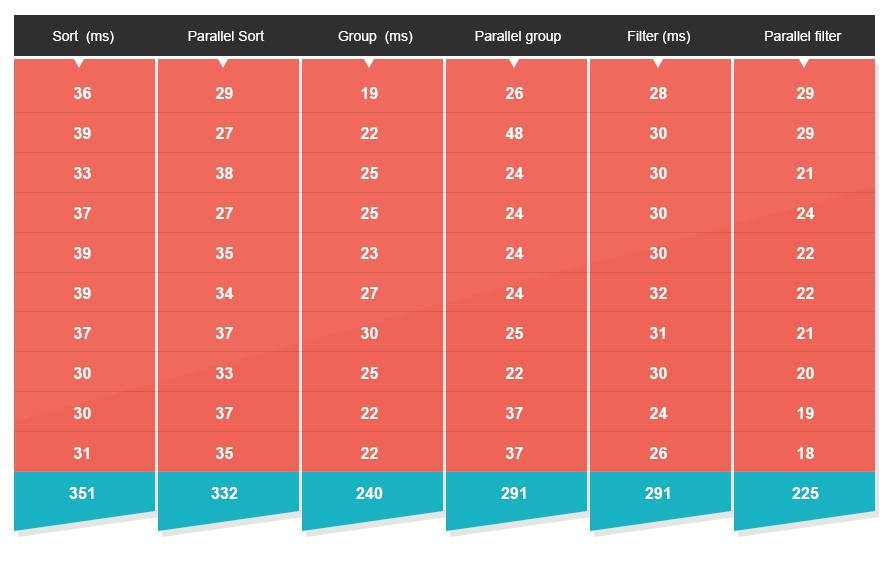
Conclusions
While these are very strong and easy-to-use APIs, they’re not a silver bullet. We still need to apply judgment as to when to employ them. If you know in advance that you’ll be doing multiple processing operations in parallel, it might be a good idea to think about using a queuing architecture to match the number of concurrent operations to the actual number of processors available to you. The hard part here is that run-time performance will rely on the actual hardware architecture and levels of stress. Your code will most likely only see those during load-testing or in production, making this a classic case of ”easy to code, hard to debug”.
| Reference: | New Parallelism APIs in Java 8: Behind The Glitz and Glamour from our JCG partner Tal Weiss at the Takipi blog. |
