Prologue
I’ve been using and contributing to jclouds for over a year now. So far I’ve used it extensively in many areas and especially in the Fuse Ecosystem. In all its awesomeness it was lacking one thing, a tool which you can use to manage any cloud provider that jclouds provides access too. Something like the EC2 command like tool, but with the jclouds coolness. A common tool through which you would be able to manage EC2, Rackspace, Opesntack, CloudStack … you name it.
I am really glad that now there is such a tool and its first release is at the corner.
So this post is an introduction to the new jclouds cli, which comes in two flavors:
- Interactive mode (shell)
- Non interactive mode (cli)
A little bit of history
Being a Karaf committer, one of the first things I did around jclouds is to work on its OSGi support. The second thing was to work on jclouds integration for Apache Karaf. So I worked on a project that made it really easy to install jclouds on top of Karaf and added the first basic commands around blob stores and the Jclouds Karaf project started to take shape. At the same time a friend and colleague of mine, Guillaume Nodet had started a similar work, which he contributed to Jclouds Karaf. This project now support most of jclouds operations, provides rich completion support which makes it really fast and easy to use.
Of course, this integration project is mostly targeting people that are familiar with OSGi and Apache Karaf and cannot be considered a general purpose tool, like the one I was dreaming about in the prologue.
A couple of months ago, Andrew Bayer started considering building a general purpose jclouds cli. Then, it strike me: ” why don’t we reuse the work that has been done on Jclouds Karaf to build a general purpose cli?”
One of the great things about Apache Karaf is that it is easily branded and due to its modular foundation, you can pretty easily add/remove bits in order to create your own distribution. On top of that it allows you discover and use commands outside OSGi.
So it seemed like a great idea to create a tailor made Karaf distribution, with jclouds integration “out of the box“, that would be usable by anyone without having to know anything about Karaf, both as an interactive shell and as a cli. And here it is: Jclouds CLI.
Getting started with Jclouds CLI
You can either build the cli from source, or download a tar ball. Once you extract it, you’ll find a structure like:
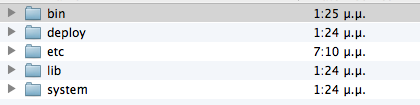
The bin folder contains two scripts:
- jclouds-cli: Starts up the interactive shell.
- jcouds: Script through which you invoke jclouds operations.
The zip distribution provides the equivalent bat files for windows.
Let’s start with the jclouds script. The script takes two parameters, multiple options and arguments. The general usage is:
./jclouds [category] [action] [options] [arguments]
- Category: The type of command to use. For example node, group, image, hardware, image etc.
- Action: The action to perform on the category. For example: list, create, destroy, run-script, info etc.
All operations wether the are compute service or blobstore operations, will require a provider or api and valid credentials for that provider/api. All of these can be specified as option to the command. For example to list all running nodes on Amazon EC2:
/jclouds node list --provider aws-ec2 --identity [my identity] --credential [my credential] --add-option [some jclouds options]
For apis you also need to specify the endpoint, for example the same operation for Cloudstack can be:
./jclouds node list --api cloudstack --identity [my identity] --credential [my credential] --endpoint http://localhost:8080/client/api
Of course, you might don’t want to specify the same options again and again. In this case you can just specify them as environmental variables. The variable name are always in capital characters and prefixed with JCLOUDS_COMPUTE_ or JCLOUDS_BLOBSTORE_ for compute service and blobstore operations respectively. So the –provider option would match JCLOUDS_COMPUTE_PROVIDER for compute service or JCLOUDS_BLOBSTORE_PROVIDER for blob stores.
The picture below shows a sample usage of the cli inside an environment setup for accessing EC2. The commands create 3 nodes on EC2 and then destroy all of them.
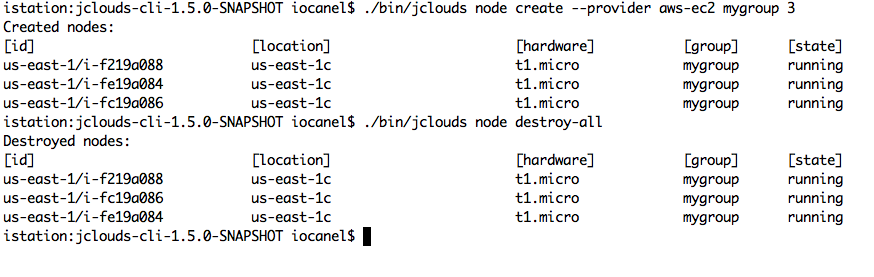
The environmental variables configured are:
- JCLOUDS_COMPUTE_PROVIDER aws-ec2
- JCLOUDS_COMPUTE_IDENITY ????
- JCLOUDS_COMPUTE_CREDENTIAL ???
When using the jclouds script all providers supported by jclouds will be available by default. You can add custom providers and apis, by placing the custom jars under the system folder (preferably using a maven like directory structure).
Using the interactive shell
The second flavor of the jclouds cli is the interactive shell. The interactive shell works in a similar manner, but it also provides the additional features:
- Service Reusability
- Services are created once
- Commands can reuse services resulting in faster execution times.
- Code completion
- Completion of commands
- Completion of argument values and options
- Modularity
- Allows you to install just the things you need.
- Extensible
- You can add commands of your own.
- You can additional project.
- Example: As of Whirr 0.8.0 you can install it to any Karaf based environment. So you can add it to the cli too.
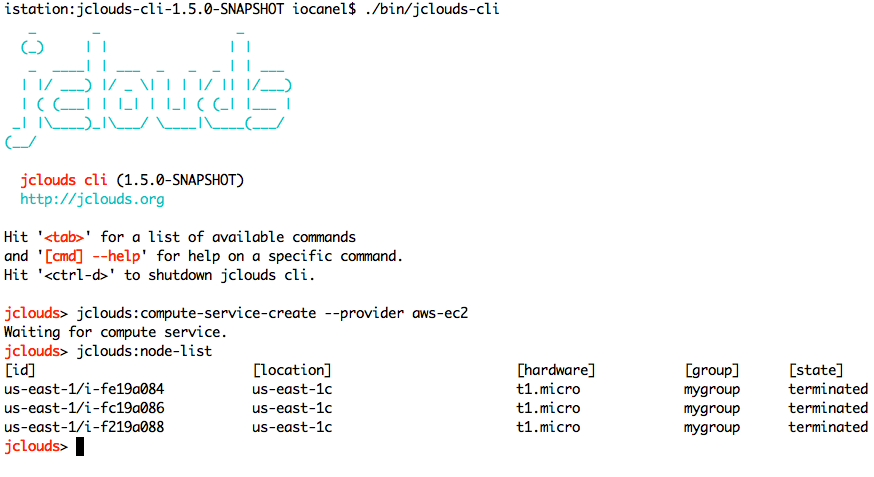
In the example above we created a reusable service for EC2 and then we performed a node list, that displayed the nodes that we created and destroyed in the previous example.
Using the interactive shell with multiple providers or apis
The interactive shell will allow you to register compute service for multiple providers and apis or even multiple service for the same provider or api using different configuration parameters, accounts etc.

The image above displays how you can create multiple services for the same provider, with different configuration parameters. It also show how to specify which service to use in each case. Note again that in this example the identity and provider was not passed but were provided as environmental variables.
Modular nature of the interactive mode
As mentioned above the interactive shell is also modular, allowing you to add / remove modules at runtime. A module can be support for a provider or api, but it can be any type of extension you may need.
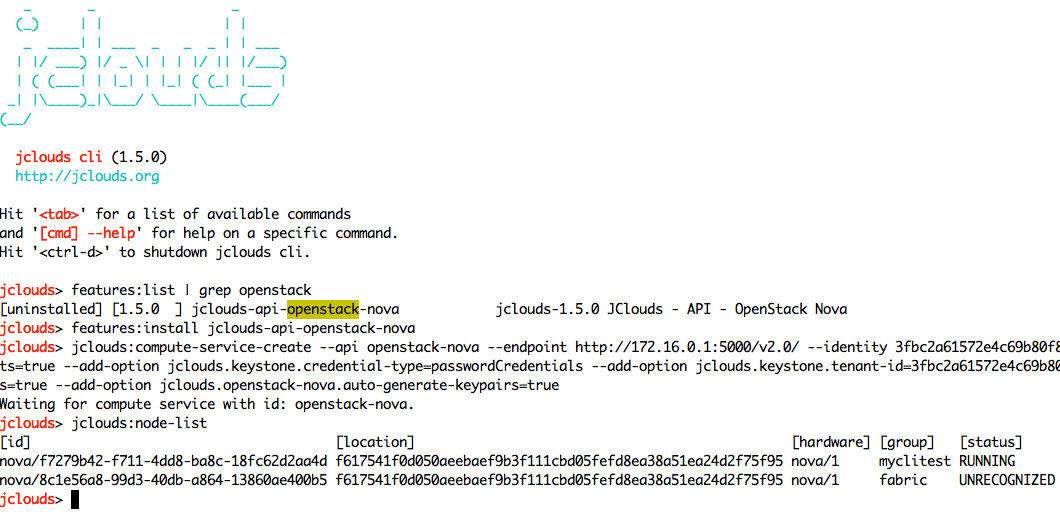
To see the list of available providers and api that can be used in the interactive mode, you can use the features:list and features:install commands. In the example below we list the features and grep for “openstack” and then install the jclouds openstack-nova api. Then we create a service for it and list the nodes in our openstack.
Configuring the command output
Initially the command output was designed and formatted, using the most common cloud providers as a guide. However, the output was not optimal for all providers (different widths etc). Moreover, different users needed different things to be displayed.
To solve that problem the cli uses a table-like output for the commands, with auto-adjustable column sizes to best fit the output of the command. Also the output of the commands is fully configurable.
Each table instance is feed the display data as a collection which represents table rows. The column headers are read from a configuration file. The actual value for each cell is calculated using JSR-233 script expressions (by default it uses groovy), which are applied for each row and column. Finally the table supports sorting by column.
A sample configuration for the hardware list command can be something like:
#The column headers
hardware.headers=[id];[ram];[cpu];[cores]
#Groovy expressions for displaying id, ram, sum of (cores X speed) for each proceessor, sum of cores.
hardware.expressions=hardware.id;hardware.ram;hardware.processors.sum{it.cores*it.speed};hardware.processors.sum{it.cores}
#Cell alignments. We prefer numbers to be right aligned.
hardware.alignments=left;right;right;right
#Sort by the [cpu] column in descending order
hardware.shortby=[cpu]
hardware.ascending=trueWith this configuration the image list command will produce the following output:

We can modify the configuration above and add an additional column, that will display the volumes that are assigned to the current hardware profile. In order to do so we need to have a brief idea of how the jclouds hardware object looks like:
public interface Hardware extends ComputeMetadata {
List<? extends Processor> getProcessors();
int getRam();
List<? extends Volume> getVolumes();
Predicate<Image> supportsImage();
}
public interface Volume {
String getId();
Type getType();
Float getSize();
String getDevice();
boolean isDurable();
boolean isBootDevice();
}So in order to get all the volume size and the type of the volume we could use the following expression on the hardware object: hardware.volumes.collect{it.size + “GB ” + it.type}.
The updated configuration would then look like:
#The column headers
hardware.headers=[id];[ram];[cpu];[cores];[volumes]
#Groovy expressions for displaying id, ram, sum of (cores X speed) for each proceessor, sum of cores.
hardware.expressions=hardware.id;hardware.ram;hardware.processors.sum{it.cores*it.speed};hardware.processors.sum{it.cores};hardware.volumes.collect{it.size + "GB " + it.type}
#Cell alignments. We prefer numbers to be right aligned.
hardware.alignments=left;right;right;right;left
#Sort by the [cpu] column in descending order
hardware.shortby=[cpu]
hardware.ascending=true
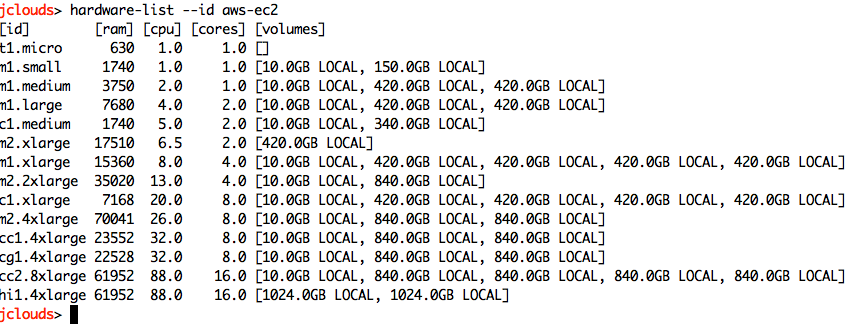
The new configuration would produce an the following output on EC2:
You can find the project at github: https://github.com/jclouds/jclouds-cli. Or you can directly download the tarballs at: http://repo1.maven.org/maven2/org/jclouds/cli/jclouds-cli/1.5.0/
