In this post, I illustrate how to maintain in DB the current state of a real time event-driven process in a scalable and lock free manner thanks to the Storm framework.
Storm is an event based data processing engine. Its model relies on basic primitives like event transformation, filtering, aggregation… that we assemble into topologies. The execution of a topology is typically distributed over several nodes and a storm cluster can also execute several instances of a given topology in parallel. At design time, it’s thus important to have in mind which Storm primitives execute with partition scope, i.e. at the level of one cluster node, and which ones are cluster-wide (also called repartitioning operations, since they involve network traffic that move events from partition to partition). The Storm Trident API documentation mentions clearly which ones do what and with what scope. The partition concept of Storm is aligned with the partition concept of Kafka queues, which are a usual source of inbound events.
Topologies usually need to maintain some execution ongoing state. This can be for example a sliding window average of some sensor values, recent sentiment extracted from tweets, counts of people present at different locations,… The scalability model is thus particularly important here since some state update operations have partition scope (e.g. partitionAggregate), while others have cluster scope (e.g. combination of groupby + perstitentAggregate). This later one is illustrated in this post.
The example code is available on githup. It is based on Storm 0.8.2, Cassandra 1.2.5 and JDK 1.7.0. Please note that this example does not include proper error handling: neither the spout nor the bolts support replay of failed tuples, I’ll address that in a later post. Also, I use java serialization to store data in my tuples, so even if Storm supports several languages, my example are java specific.
Practical example: presence events
My example is simulating a system that tracks people’s position inside a building. A sensor at the entrance of each room emits an event like the ones below anytime a user enters or leaves the room:
{"eventType": "ENTER", "userId": "John_5", "time": 1374922058918, "roomId": "Cafetaria", "id": "bf499c0bd09856e7e0f68271336103e0A", "corrId": "bf499c0bd09856e7e0f68271336103e0"}
{"eventType": "ENTER", "userId": "Zoe_15", "time": 1374915978294, "roomId": "Conf1", "id": "3051649a933a5ca5aeff0d951aa44994A", "corrId": "3051649a933a5ca5aeff0d951aa44994"}
{"eventType": "LEAVE", "userId": "Jenny_6", "time": 1374934783522, "roomId": "Conf1", "id": "6abb451d45061968d9ca01b984445ee8B", "corrId": "6abb451d45061968d9ca01b984445ee8"}
{"eventType": "ENTER", "userId": "Zoe_12", "time": 1374921990623, "roomId": "Hall", "id": "86a691490fff3fd4d805dce39f832b31A", "corrId": "86a691490fff3fd4d805dce39f832b31"}
{"eventType": "LEAVE", "userId": "Marie_11", "time": 1374927215277, "roomId": "Conf1", "id": "837e05916349b42bc4c5f65c0b2bca9dB", "corrId": "837e05916349b42bc4c5f65c0b2bca9d"}
{"eventType": "ENTER", "userId": "Robert_8", "time": 1374911746598, "roomId": "Annex1", "id": "c461a50e236cb5b4d6b2f45d1de5cbb5A", "corrId": "c461a50e236cb5b4d6b2f45d1de5cbb5"}Each event of the (“ENTER” and “LEAVE”) pair corresponding to one occupancy period of one user inside one room has the same correlation id. That might be asking a lot to a sensor, but for the purpose of this example this makes my life easier ![]() .
.
To make things interesting, let’s imagine that the events arriving at our server are not guaranteed to respect chronological order (see the shuffle() call in the python script that generates the events).
We are going to build a Storm topology that builds the minute per minute occupancy timeline of each room, as illustrated by the time plot at the end of this post. In database, room timelines are sliced into periods of one hour which are stored and updated independently. Here is an example of 1h of Cafetaria occupancy:
{"roomId":"Cafetaria","sliceStartMillis":1374926400000,"occupancies":[11,12,12,12,13,15,15,14,17,18,18,19,20,22,22,22,21,22,23,25,25,25,28,28,33,32,31,31,29,28,27,27,25,
22,22,21,20,19,19,19,17,17,16,16,15,15,16,15,14,13,13,12,11,10,9,11,10,9,11,10]}
In order to produce that, our topology needs to:
- regroup the “ENTER” and “LEAVE” events based on correlationID and produce the corresponding presence period for this user in this room
- Apply the impact of each presence period to the room occupancy timeline
As a side, Cassandra provides Counter columns which I do not use here, even though they would have been a good alternative to the mechanism I present. My purpose however is to illustrate Storm functionalities, even if it makes the approach a bit contrived.
group by/ persistentAggregate / iBackingMap explained
Before looking at the example code, let’s clarify how these Trident Storm primitives work together.
Imagine we received the two events describing a user presence in roomA from 9:47am to 10:34am. Updating the room’s timeline requires to:
- load from DB the two impacted timeline slices: [9.00am, 10:00am] and [10.00am, 11:00am]
- add this user’s presence in these two timeline slices
- save them to DB
Implementing this naively like this however is far from optimal, first because it uses two DB requests per event, second because this “read-update-write” sequence requires in general a locking mechanism, which usually does not scale well.
To solve the first point we want to regroup the DB operations for several events. In Storm, events (or tuples) are processed as batches. IBackingMap is a primitive that we can implement and which allows us to peek at a whole batch of tuples at once. We are going to use that to re-group all the DB-read operations at the beginning of the batch (multiget) and all the DB-write operations at the end (multiput). The multiget does not let us look at the tuples themselves though, but only at “query keys”, which are computed from the tuples content, as described below.
The reason for this lies in the second point raised above about the naive implementation: we want to execute several [multiget + our update logic + multiput] streams in parallel without relying on locks. The is achieved here by ensuring that those parallel sub-processes update disjoint sets of data. This requires that the topology element defining the split into parallel streams also controls which data is loaded and updated in DB within each stream. This element is the Storm groupBy primitive: it defines the split by grouping tuples by field value and it controls which data is updated by each parallel stream by providing the “groupedBy” values as query key to the multiget.
The following picture illustrates this on the room occupancy example (simplified by storing only one timeline per room, as opposed to one timeline per one-hour slice):
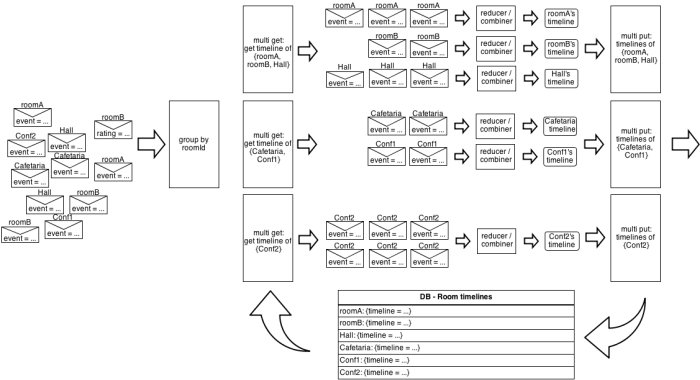
The parallelism is not happening exactly like that though (e.g. the current Storm implementation calls each reducer/combiner sequencially within a grouped stream), but that’s a good model to keep in mind when designing topologies.
It’s interesting to realize that there is some Storm magic happening between the groupBy and the multiget. Recall that Storm is meant to be massively distributed, which implies that each stream is executed in parallel throughout several nodes, getting input data from distributed data sources like Hadoop HDFS or distributed Kafka queues. This means the groupBy() is executed on several nodes simultaneously, all potentially processing events that needs to be grouped together. groupBy is a repartitioning operation and ensures that all events that need to be grouped together will be sent to the same node and processed by the same instance of IBackingMap + combiner or reducer, so no race condition occur.
Also, Storm requires us to wrap our IBackingMap into one of the available Storm MapState primitive (or our own…), typically to handle failed/replayed tuples. As mentioned above I am not discussing that aspect in this post.
With this approach, we must implement our IBackingMap so that it respects the following property:
- The DB row(s) read by multiget and written by multiput operations of IBackingMap for different key values must be distinct.
I guess that’s the reason they called those values “key” ![]() (although anything that respect this property should be ok).
(although anything that respect this property should be ok).
Back to the example
Let’s see how this works in practice. The main topology of the example is available here:
// reading events
.newStream("occupancy", new SimpleFileStringSpout("data/events.json", "rawOccupancyEvent"))
.each(new Fields("rawOccupancyEvent"), new EventBuilder(), new Fields("occupancyEvent"))This first part is just reading the input events in JSON format (I’m using a simple file spout), deserializing them and putting them into a tuple field called “occupancyEvent” using java serialization. Each of those tuple describes an “ENTER” or “LEAVE” event of a user in or out of a room.
// gathering "enter" and "leave" events into "presence periods"
.each(new Fields("occupancyEvent"), new ExtractCorrelationId(), new Fields("correlationId"))
.groupBy(new Fields("correlationId"))
.persistentAggregate( PeriodBackingMap.FACTORY, new Fields("occupancyEvent"), new PeriodBuilder(), new Fields("presencePeriod"))
.newValuesStream()The groupBy primitive yields the creation of as many tuple groups as we meet distinct values of the correlationId (which can mean a lot since normally at most two events have the same correlationId). All tuples having the same correlation ID in the current batch will be regrouped together, and one or several groups of tuples will be presented together to the elements defined in the persistentAggregate. PeriodBackingMap is our implementation of IBackingMap where we implement the multiget method that will receive all the correlation ids of the group of groups of tuples we’ll be handling in the next steps (for example: {“roomA”, “roomB”, “Hall”}, on the picture above).
public List<RoomPresencePeriod> multiGet(List<List<Object>> keys) {
return CassandraDB.DB.getPresencePeriods(toCorrelationIdList(keys));
}This code just needs to retrieve from DB potentially existing periods for each correlation id. Because we did a groupBy on one tuple field, each List contains here one single String: the correlationId. Note that the list we return must have exactly the same size as the list of keys, so that Storm knows what period corresponds to what key. So for any key that does not exist in DB, we simply put a null in the resulting list.
Once this is loaded Storm will present the tuples having the same correlation ID one by one to our reducer, the PeriodBuilder. In our case we know it will be called maximum twice per unique correlationId in this batch, but that could be more in general, or just once if the other ENTER/LEAVE event is not present in the current batch. Right between the calls to muliget()/multiput() and our reducer, Storm lets us to insert the appropriate logic for replays of previously failed tuples, thanks to an implementation of MapState of our choice. More on that in a later post…
Once we have reduced each tuple sequence, Storm will pass our result to the mulitput() of our IBackingMap, where we just “upsert” everything to DB:
public void multiPut(List<List<Object>> keys, List<RoomPresencePeriod> newOrUpdatedPeriods) {
CassandraDB.DB.upsertPeriods(newOrUpdatedPeriods);
}Storm persistenceAggregate automatically emits to the subsequent parts of the topology tuples with the values our reducer provided to the multitput(). This means the presence periods we just built are readily available as tuple fields and we can use them to update the room timelines directly:
// building room timeline
.each(new Fields("presencePeriod"), new IsPeriodComplete())
.each(new Fields("presencePeriod"), new BuildHourlyUpdateInfo(), new Fields("roomId", "roundStartTime"))
.groupBy(new Fields("roomId", "roundStartTime"))
.persistentAggregate( TimelineBackingMap.FACTORY, new Fields("presencePeriod","roomId", "roundStartTime"), new TimelineUpdater(), new Fields("hourlyTimeline"))The first line simply filters out any period not yet containing both an “ENTER” and “LEAVE” event.
BuildHourlyUpdateInfo then implements a one-to-many tuple emission logic: for each occupancy period, it simply emits one tuple per “started hour”. For example an occupancy presence in roomA from 9:47am to 10:34am would trigger here the emission of a tuple for the 9.00am timeline slice of roomA and another for 10.00am.
The next part implements the same groupBy/IBackingMap approach as before, simply this time with two grouping keys instead of one (so now the List<Object> in the mulitget will contain two values: one String and one Long). Since we store timeline chunks of one hour the necessary property of IBackingMap mentioned above is respected. The multiget retrieves timeline chunks for each (“roomId”, “start time”) pair, then TimelineUpdater (again a reducer) updates the timeline slice with each presence period corresponding to this timeline slice found in the current batch (that’s the purpose of the one-to-many tuple emission logic of BuildHourlyUpdateInfo) and the multiput() just saves the result.
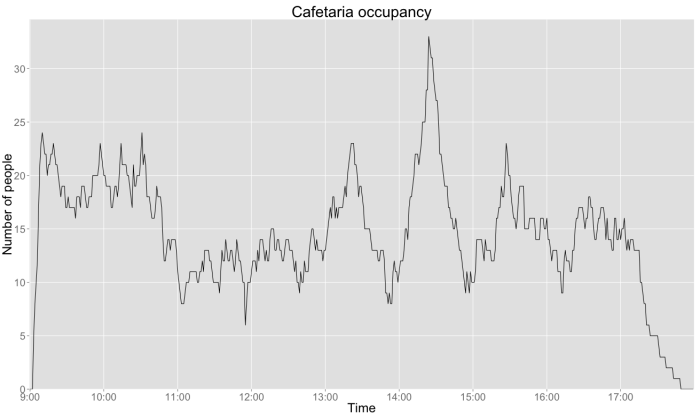
Resulting cafetaria occupancy
Everything is always more beautiful when we can look at it, so let’s plot the occupancy of the room ![]() . A bit of R code later, we have this visualization of a room occupancy minute by minute (which does not mean much since all data are random, but well…):
. A bit of R code later, we have this visualization of a room occupancy minute by minute (which does not mean much since all data are random, but well…):
Conclusion
Hopefully this post presents one useful approach for maintaining state in Storm topologies. I have also tried to illustrate the implementation of the processing logic into small topology elements plugged one into another, as opposed to having a few “mega-bolts” bundling long and complex pieces of logic.
One great aspect of Storm is its extensibility, it’s very possible to go and plug sub-classes of this or that a bit everywhere to tune its behavior. It has this clever and fun feeling that Spring had 10 years ago (oh, damn, I feel old now…^__^)
