There are a number of factors to take into account while developing distributed software systems. If you don’t even know what I am talking about in the first sentence then let me give you some insight, examples and for instances of what distributed systems are.
Overview
A distributed system is when multiple physical hardware devices interact with separate and discrete users and collaborate together through these hardware devices to accomplishes different and also similar goals for these discrete and seperate users. Sometimes these devices work in a pier-to-pier mode using servers as hubs for knowledge of connectivity to each other while others collaborate and coordinate through a single or set of centralized servers e.g.
An extranet like system where supply side users are reviewing documents through a web browser and click through a workflow in their browsers that ultimatly fax documents to another set of users that provide services that are sufficiently labeled… i.e. with a bar code. This loop makes for a closed system to design and develop distributed software for. The recipient of the faxes fill out and do whatever they need as part of their paper based world (including receiving many faxes over time and sending them all back in at once, which is another set of cases for another blog post on e-signing). The receiving fax servers on receipt of the inbound original documents “hands” the faxed images received over for collation and processing for yet another set of users (or even the same ones that originated the outbound fax) to review and work with them under an intake workflow again in their browser.
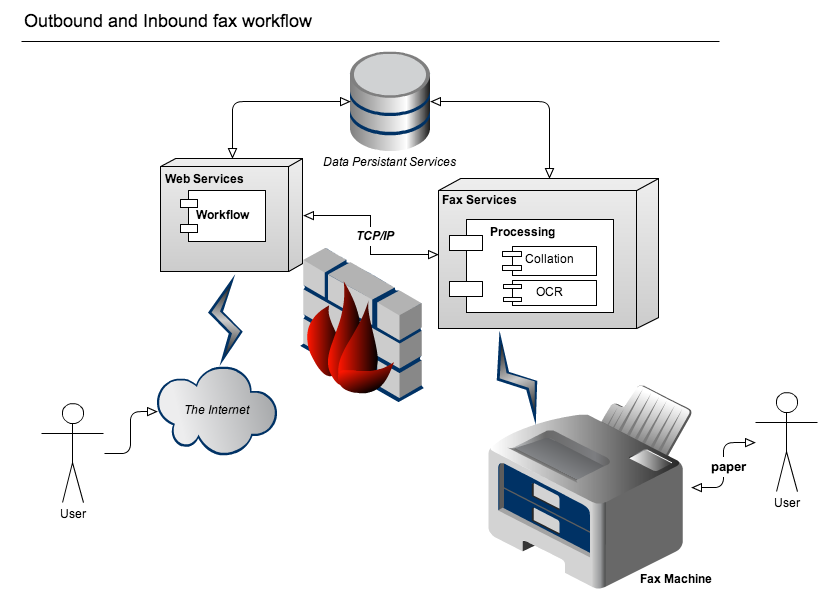
Here you have many systems working together in the data center to accomplish different goals. You have some web servers for the user interface. Some data persistance layer for the workflow systems, analytics and reporting. You have fax servers for management of the incoming/outgoing fax transmissions (I like Dialogic Brooktrout Fax Boards myself http://www.dialogic.com/Products/fax-boards-and-software/fax-boards.aspx ). You have the inbound and outbound labeling, stamping, collation, scanning and object character recognition components (usually a few different servers together depending on design likely not each a separate instance but likely a half dozen or so depending on scale).
The fabric underneath all of those components are what is consistent across all of them together. This starts at the OSI Layer because first and for most distributed systems are connected through physical layers of constraints so lets start there.
The Physical Layer Constraints
The OSI Layer has either 7 or 9 layers depending on whom you speak with. In some teams layers 8 and 9 are politics and religion (respectively) because social structures, methodologies and human behavior around all interactions to design, develop, deploy and maintain these systems have to be taken into account. If you don’t appreciate this then your application layer user experience is likely going to be wrong also. Layers 1-7 (the more commonly known and often better understood layers) classify how computers move data through an interface for a user or computer and an interface to another computer for another computer or another user. You can never do anything outside of the underlying layers without refactoring or creating new software in those layers. So, its good to know how they work. You can do that some in your own software program writing works (please, please, pretty please) to better balance out processing constraints.
Figure 30-1 of http://fab.cba.mit.edu/classes/MIT/961.04/people/neil/ip.pdf maps many of the protocols of the Internet protocol suite and their corresponding OSI layers.
Where software continues within the hardware device
The operating system and its implementation for the local machine hardware is next and foremost. I am hard pressed to pick many or any other layers or systems that are truelly part of the underly fabric depending on your hosting provider which ultimately is a vendor so thats a different story for another time too… unless they run software your wrote also via open source project work you have done but, I digress… The Linux Programming Interface: A Linux and UNIX System Programming Handbook is the resource I like for Linux.
Now What?
Over the last nine years a lot of classic computer concepts have been more readily achievable because of the inexpensive (sometimes cheep) commodity hardware that has become our foreshadowed reality. This has made parallel and distributed computing platforms, distributed document and key/value stores, distributed pub/sub broker, publisher and consumer systems and even actor patterns with immutable structures start to become part of this fabric. The rub here is the competition and infancy of these market segments arguably yet to even have “crossed the chasm“.
Now, having said all of that … There is a stand out. “ZooKeeper provides key points of correctness and coordination that must have higher transactional guarantees than all of these types of system that want to build intrinsically into their own key logic”. Camille Fournier made me see this in one of her blog posts http://whilefalse.blogspot.com/2013/05/zookeeper-and-distributed-operating.html?spref=tw because of how Zookeeper is tied into so many of these existing types of systems. Since these systems have yet to mature in the marketplace (while having sufficiently matured with early adopters, by far) there are some consistencies within and across them we have to start to take a look at, support and commit to (literally).
What is also nice now about Zookeeper is that there is an open source library that has been developed and (all things being equal) continuously maintained to make developing the repeatable patterns of Zookeeper development easier http://curator.incubator.apache.org/. If you have never worked with Zookeeper I recommend starting here http://zookeeper.apache.org/doc/trunk/zookeeperStarted.html.
