For archiving your data at AWS you can use AWS Glacier. This service offers cheaper storage than the S3 service but the downside is that your data won’t be accessible right away as it is with S3. It may take a few hours to restore the data but if you are using this service for real archiving purposes this shouldn’t be a real issue. Lets setup a Glacier Vault by using the Management Console. Select the Glacier service in the Management Console:
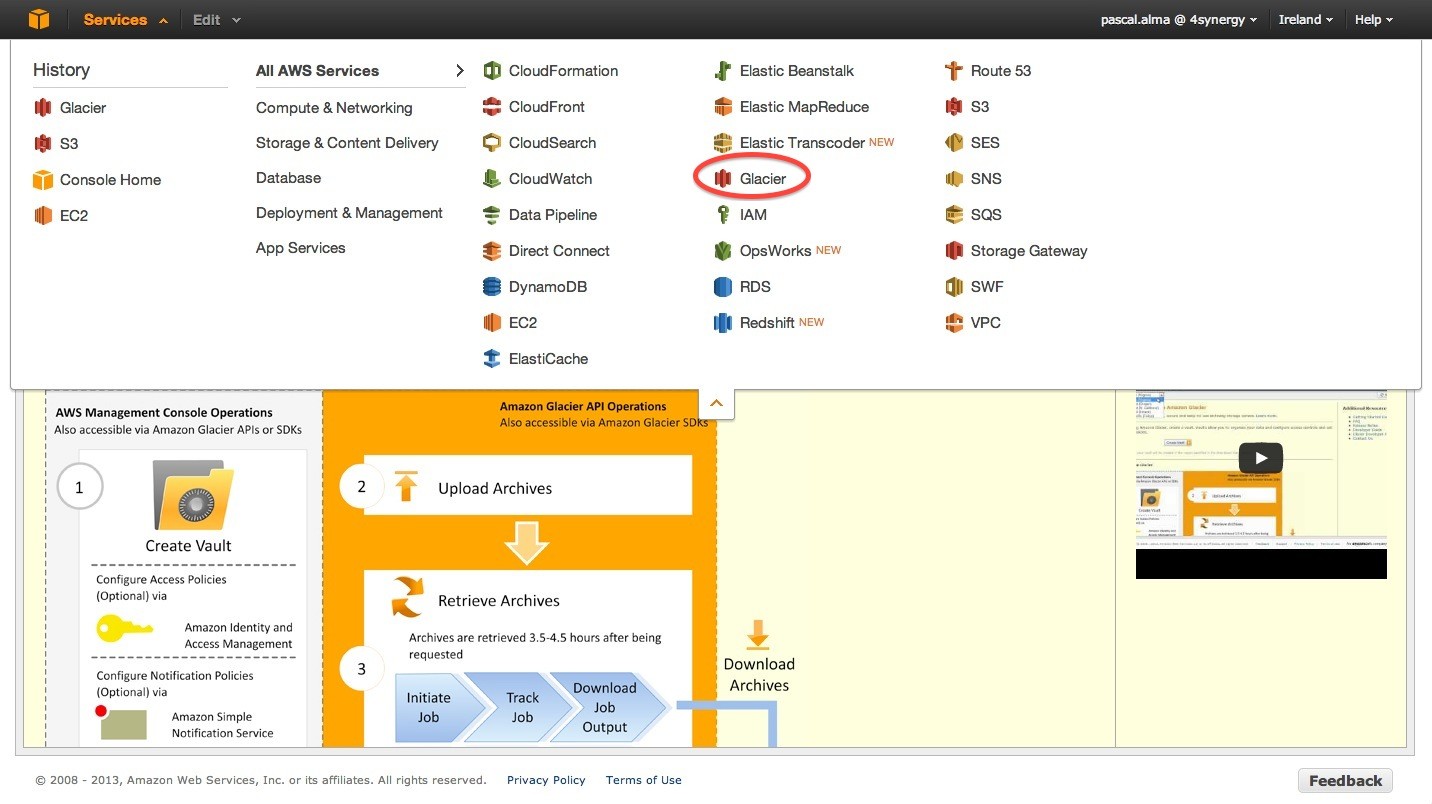
Click ‘Create Vault’ and give it a name:
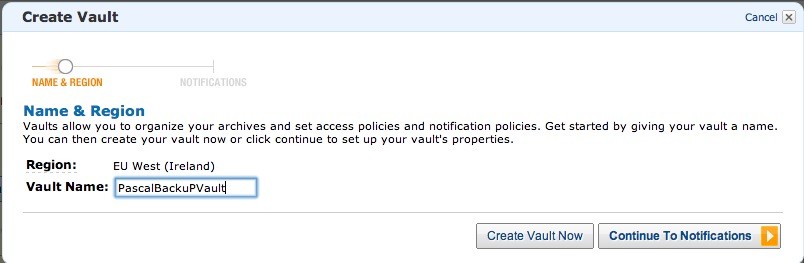
Set up a new SNS topic so we can receive messages when archiving actions are finished.
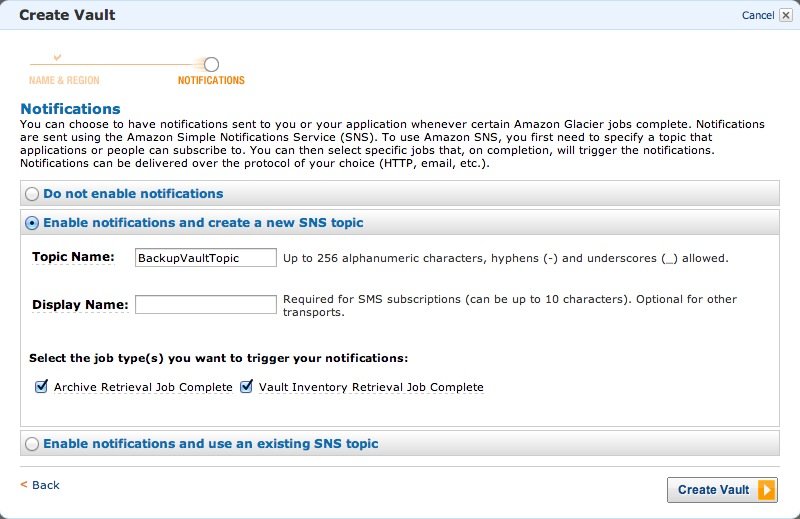
If all went well the Vault is created:
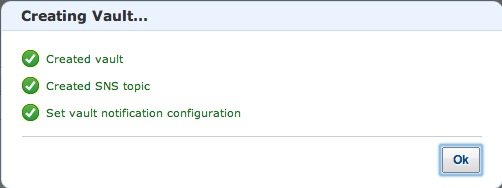
Together with the vault also a new SNS is created. To receive the messages posted on the SNS lets subscribe to it. Select the SNS service in the console:
Select the SNS topic that is just created:
Now click on the button to create a subscription to this topic. I simply create an email subscription so every message posted on the topic is send to the supplied email address:
The Glacier service in the Management Console doesn’t come with the functionality to archive/restore files to and from Glacier (like it does with S3). But there is of course an API to use and several SDK’s to transfer files. And of course there is the community which jumped into this and created a lot of tools both GUI and CLI based. I just picked one of them and installed it.
After installing and configuring the Glacier-cli I can check the created vault is found:
pascal$ ./glacier.py --region eu-west-1 vault list PascalBackuPVault
Lets put some data into the vault. I use the example of the CLI tool as inspiration. Create a local file:
pascal$ echo 42 > example.txt
Upload the file into the vault created earlier:
pascal$ ./glacier.py --region eu-west-1 archive upload PascalBackuPVault example.txt
Lets check the file is in the vault:
pascal$ ./glacier.py --region eu-west-1 archive list PascalBackuPVault example.txt
Now remove the local file and restore the archived one:
pascal$ rm example.txt pascal$ ./glacier.py --region eu-west-1 archive retrieve PascalBackuPVault example.txt glacier: queued retrieval job for archive 'example.txt' pascal$ ./glacier.py --region eu-west-1 archive retrieve PascalBackuPVault example.txt glacier: job still pending for archive 'example.txt' pascal$ ./glacier.py --region eu-west-1 job list a/p 2013-05-20T18:40:25.107Z PascalBackuPVault example.txt pascal$ ./glacier.py --region eu-west-1 archive retrieve --wait PascalBackuPVault example.txt
After a few hours the job is finished and we can access the local file ‘example.txt’ again.
pascal$ cat example.txt 42
And in the mail I find the following notification telling me the archive file is ready for retrieval:
{"Action":"ArchiveRetrieval"
,"ArchiveId":"CggVcXvaWKfRn5tDR_UKna0GsYyXyZzlALPvjEFkcLdRq4NRBXra36m7hBOJSNCbOmEkQ04VoyTQyMt_
pXdrNggms13e3vjUqwW3tZwps8BiA1gprQQZyUQPDwwWkuKAFZoqahzA-g"
,"ArchiveSHA256TreeHash":
"084c799cd551dd332d5c5f9a5d593b2e931f5e36122ee5c793c1d08a19839cc0"
,"ArchiveSizeInBytes":3
,"Completed":true
,"CompletionDate":"2013-05-20T22:40:31.040Z"
,"CreationDate":"2013-05-20T18:40:25.107Z"
,"InventorySizeInBytes":null
,"JobDescription":null
,"JobId":"rxRUKT0QVWyOEMu4VYW_zrhXXYZC0ZrVo63sCtQJDBpFyhO-pPRJ7Z_Af02Hvn-bge-yGrKzRw78xG9d-Nvxjv2LcQho"
,"RetrievalByteRange":"0-2"
,"SHA256TreeHash":
"084c799cd551dd1d6e535f9a5d593b2e931f5e36122ee5c793c1d08a19839cc0"
,"SNSTopic":null
,"StatusCode":"Succeeded"
,"StatusMessage":"Succeeded"
,"VaultARN":"arn:aws:glacier:eu-west-1:678658091597:vaults/PascalBackuPVault"}
--
...There is of course a lot more to tell about AWS Glacier. This page will be a good next step to get familiair with Glacier.
